Data consistency is one of the most important aspects when building and maintaining any application. While multiple architecture patterns are present to build applications, microservices prevail as one of the most widely used software architectures.
Using microservices architecture can enable you to develop e-commerce applications, streaming platforms, and many other applications where different microservices handle different services. Although there are many advantages to using microservices architecture, there are significant limitations in managing distributed systems and maintaining data consistency.
Considering the limitations, it can become challenging to take advantage of microservices. This article will highlight methods to overcome these challenges and maintain data consistency between microservices.
Challenges of Data Consistency in Microservices
In a monolithic architecture, a shared relational database ensures data consistency with the help of ACID transactions. ACID transactions include:
- Atomicity: Transactions co-occur, or the whole transaction process fails.
- Consistency: The database remains consistent before and after the transaction.
- Isolation: The transactions can occur independently without any interruptions.
- Durability: The system failure does not interfere with the changes of a successful transaction.
Each microservice handles its data store using a unique set of technologies. It also handles all transactions locally since there is no centralization of a single database. However, with the decentralization of data, traditional single-unit ACID transactions are not feasible across databases in microservices.
You can follow different strategies to maintain consistent data storage between microservices. Some methods to achieve microservices data consistency include eventual consistency, distributed transactions, and compensation mechanisms.
Here’s an example that can enable you to understand the issue with data consistency across microservices.
Imagine an application with microservices handling a social media platform’s user profiles, posts, and notifications. Since microservice architecture is applicable here, each service has its database.
Suppose a user creates a new post. The platform first performs identification through the user profile and then stores the post’s content. Simultaneously, the platform triggers notifications to notify the user’s followers about the post.
Now, if a database connectivity issue occurs while storing the post’s content, and users are notified about a new post, but the post doesn’t exist. This creates a data inconsistency problem.
Strategies to Achieve Data Consistency Between Microservices
If you are wondering how to maintain data consistency in microservices, this section outlines three widely used approaches. The choice of strategy depends on your organizational requirements.
Eventual Consistency
In distributed systems like microservices architecture, eventual consistency is a model that can enable you to attain high availability. Temporary data inconsistencies are allowed in the eventual consistency models as long as the data eventually converges to the same state.
Rather than relying on ACID transactions, eventual consistency depends on the BASE transactions model. The ACID model prioritizes consistency, whereas the BASE model prioritizes availability.
Here’s an overview of the BASE transactions model:
- Basically Available: It ensures data availability across a database cluster’s nodes without mandating immediate consistency.
- Soft State: Data inconsistency can present difficulties in transactions, so the BASE model delegates the responsibility of maintaining consistency to the developers.
- Eventually Consistent: BASE does not enforce immediate consistency, but the data eventually converges, ensuring consistency. Data reads are possible before the eventual consistency and might produce inconsistency and not reflect reality.
Understanding SAGA Model
 Saga Model
Saga Model
The SAGA pattern is an Eventual Consistency model that enables distributed transactions asynchronously with local transactions to all the microservices. Each microservice under the SAGA pattern conducts transactions asynchronously while maintaining the execution sequence.
For example, if a social media user posts content. The SAGA will contain three local transactions: maintenance of user profiles, content in the posts, and notifications sent to other users. If any single one of these fails, the SAGA model performs an undo action for the previously performed steps.
Here are the two different ways to coordinate SAGA:
SAGA Choreography: This pattern enables services to communicate with each other after completing each task. The choreography pattern is a decentralized way of performing SAGA operations. It promotes loose coupling and boosts independence among different services. Each service acts on its own and reactively listens to other services.
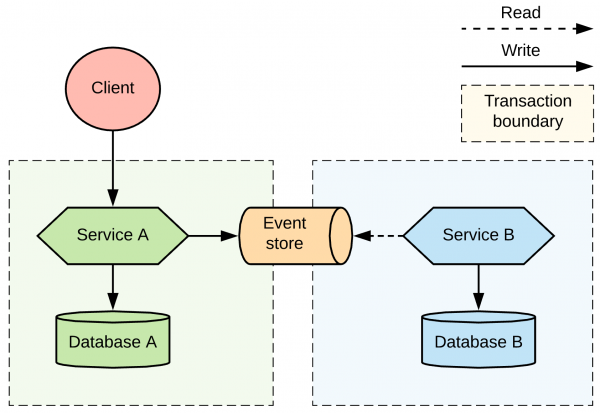
In SAGA Choreography, event sourcing is a method for storing event changes. The event store models state in different forms while acting as an event database.
However, this system requires strong and resilient event management to ensure data consistency. In choreography patterns, the complexities can increase as the number of services increases. If the number of services increases, the monitoring and visibility of transactions can decrease, reducing the transparency of the model.
SAGA Orchestration: The orchestration pattern provides a centralized way of performing SAGA operations. In this case, a single microservice acts as a central coordinator (SAGA Execution Orchestrator) that commands other microservices to update local transactions. It understands the order and logic of the SAGA operations and communicates with other microservices through commands and replies.
If any operation fails, the Orchestrator initiates undo actions to the previously performed operations to maintain data consistency. This process is known as Compensation Operations. It manages the failures that occur to maintain a consistent system state.
For example, the coordinator can send a command to the post content service in the user profile service SAGA. If the returned response is positive, the user profile service can directly contact the notification service and send notifications to other users. If any command fails, the coordinator can send a compensating command to the previous microservice to update the local transactions.
In contrast to Saga Choreography, Orchestration simplifies the complexity of maintaining data consistency. It improves transaction visibility and monitoring and requires less coordination.
However, orchestration has drawbacks, including higher coupling between microservices, decreasing availability and scalability, and limited flexibility and evolution. It creates a single point of failure. If one part of the system breaks, it could stall the whole system.
Compensation Mechanism
The compensation mechanism discusses the measures to maintain data consistency while monitoring data transfer. However, you need to perform multiple steps to reduce the effect of failures.
Reconciliation
In this method, you will receive an error message if the system crashes between transactions. The compensation mechanism triggers compensation logic, a series of steps to maintain data consistency. The execution logic may resume after the request is processed without any error.
Main Process Failure
Compensation will require reconciling data from multiple services through action triggers during primary process failure. These action triggers happen due to scheduling or monitoring systems for failures. A record-by-record technique compares aggregated values and designates one system as the data source per record.
Event Log
In a multi-step transaction failure, you can check each transaction’s status to identify failure steps during reconciliation. The Stateless mail services can lack availability for functions such as email sending, limiting immediate visibility into transaction states for complex scenarios.
Single-write
In this method, a single data source is modified at a time. Rather than executing a single process, changing the service’s state and emitting events into different steps happens individually.
Change Data Capture
 Change Data Capture
Change Data Capture
This strategy alters the state of the service, and then a separate process captures the changes to generate a response accordingly. It ensures reliable tracking of the changes made and the generation of specific events based on them. You can follow the article Micorservices event sourcing vs CDC to understand critical aspects of the CDC.
Event-first Strategy
In the event-first method, you can initiate an event and then distribute it among services rather than updating the database. Here, the event serves as a primary source of accurate information. Each event represents the write model, and the service’s state is the read model. This method is a part of the command query responsibility segregation (CQRS).
Distributed Transactions
Distributed transactions are another strategy in microservices to maintain data consistency. They try to move a system from one consistent state to another, managing common data consistency failures without putting additional pressure on the developer. The XA two-phase commit protocol is one of the most widely used distributed transaction protocols.
 Two-phase commit
Two-phase commit
XA protocols can ensure updates to multiple data sources while adhering to a transaction’s ACID property. The two-phase commit protocol guarantees data consistency in distributed systems by maintaining the ACID properties of database transactions across various nodes. It consists of two distinct phases: the prepare and commit phases.
In distributed transactions, two or more resources manage the transactions, and the distributed transaction coordinator or manager guarantees the data guarantee. Since multiple resources are involved in the transaction, it can become a complex process.
These methods can enable you to maintain data consistency between microservices, which is essential for ensuring the integrity and reliability of the data. However, it can become complicated, too, as various sources contribute to the data. Integrating data from multiple sources to a destination takes work, as it requires prior technical knowledge and continuous monitoring.
This is why many companies prefer using SaaS-based data integration platforms that enable them to extract data from source to destination seamlessly. One of the most popular data integration platforms available today is Hevo Data.
Perform Seamless Data Integration with Hevo Data
Hevo is a no-code, automated ELT data pipeline platform that provides a cost-effective solution for creating data pipelines that perform real-time data integration. It provides 150+ data connectors and an easy-to-use user interface that enables data movement to multiple destinations without any prior technical knowledge.
Here are some of the key features provided by Hevo Data:
- Data Transformation: Hevo Data enables you to perform data transformation using simple drag-and-drop and Python-based transformations. This feature allows you to clean and prepare your data for analysis quickly.
- Incremental Data Load: Hevo Data allows you to transfer your modified data in real-time, ensuring efficient bandwidth utilization at both the source and destination ends.
- Automated Schema Mapping: Hevo automatically detects the incoming data format and replicates it to the destination schema. It provides you with the option to choose between Full and Incremental Mappings according to your specific preference.
Interested in reading more about different data integration processes? Here are some of the top picks for you:
Conclusion
This article has taught you various methods that you can use to solve various issues around data consistency in microservices architecture. While there are multiple solutions, you must carefully consider the use cases and the kind of consistency you require. It’s always better to consider an event-driven fault-tolerant architecture and design your system without requiring distributed consistency.
Frequently Asked Questions (FAQs)
Q. How does data consistency get maintained in a microservices architecture?
- Eventual consistency is a concept that guarantees data consistency over time. This strategy can be utilized when different system parts try to sync data asynchronously. Handling temporary inconsistencies involves event-driven architectures and powerful system design.
Want to take Hevo for a spin? Sign up for a 14-day free trial and experience the feature-rich Hevo suite first hand. You can also have a look at the unbeatable Hevo pricing that will help you choose the right plan for your business needs.
Visit our Website to Explore Hevo
Suraj is a technical content writer specializing in AI and ML technologies, who enjoys creating machine learning models and writing about them.