





The Hitchhiker's Guide to data privilege model and access control in Unity Catalog
As the volume, velocity and variety of data grows, organizations are increasingly relying on staunch data governance practices to ensure their core business...
Providence is a healthcare organization with 120,000 caregivers serving over 50 hospitals and 1,000 clinics across seven states. Providence is a pioneer in moving all electronic healthcare records (EHR) data to the cloud and is a healthcare leader in leveraging cloud technology to develop a large inventory of Artificial Intelligence (AI) and Machine Learning (ML) models.
The recent popularity of Large Language Models (LLMs) has created an unprecedented demand to deploy open source LLMs fine-tuned on Providence's rich EHR data set. Home-brewed AI/ML models and fine-tuned LLMs have created an even more extensive inventory of AI/ML models at Providence. The data science team at Providence embarked on an ambitious project to build an MLOps platform to develop, validate and deploy a large inventory of AI/ML models at scale.
Providence's MLOps platform has three pillars: model development, model risk management, and model deployment. The data science team has been building processes, best practices, and governance as part of the first two pillars of the MLOps platform. We partnered with Databricks to build the third pillar of the MLOps platform: model deployment.
There are over sixty-five Databricks workspaces at Providence. Each of these workspaces has an inventory of models, with some in high demand across the enterprise. The problem Providence encountered was how to deploy high-demand AI/ML models without searching all sixty-five workspaces for models. Once popular models are identified, how can the governance infrastructure provide access to these models with minimal effort?
Providence presented this problem to Databricks who devised a solution to create "Providence's Model Marketplace," a single and centralized Databricks workspace with a repository of popular AI/ML models. This solution solves two major problems: (1) caregivers across the enterprise just need access to the "Models Marketplace" to deploy any model from over sixty-five workspaces. (2) The "Providence's Model Marketplace" is one workspace where the enterprise searches when deploying models, therefore reducing model governance complexity.
Over several weeks, Providence's team of platform engineers, DevOps engineers, and Data Scientists worked closely with the Databricks Professional Services team to build "Providence's Model Marketplace." Providence and Databricks teams met multiple times a week to share updates, resolve blockers, and transfer knowledge. As a result, when the Databricks team completed the project, Providence seamlessly picked up the project and immediately began using and improving the platform.
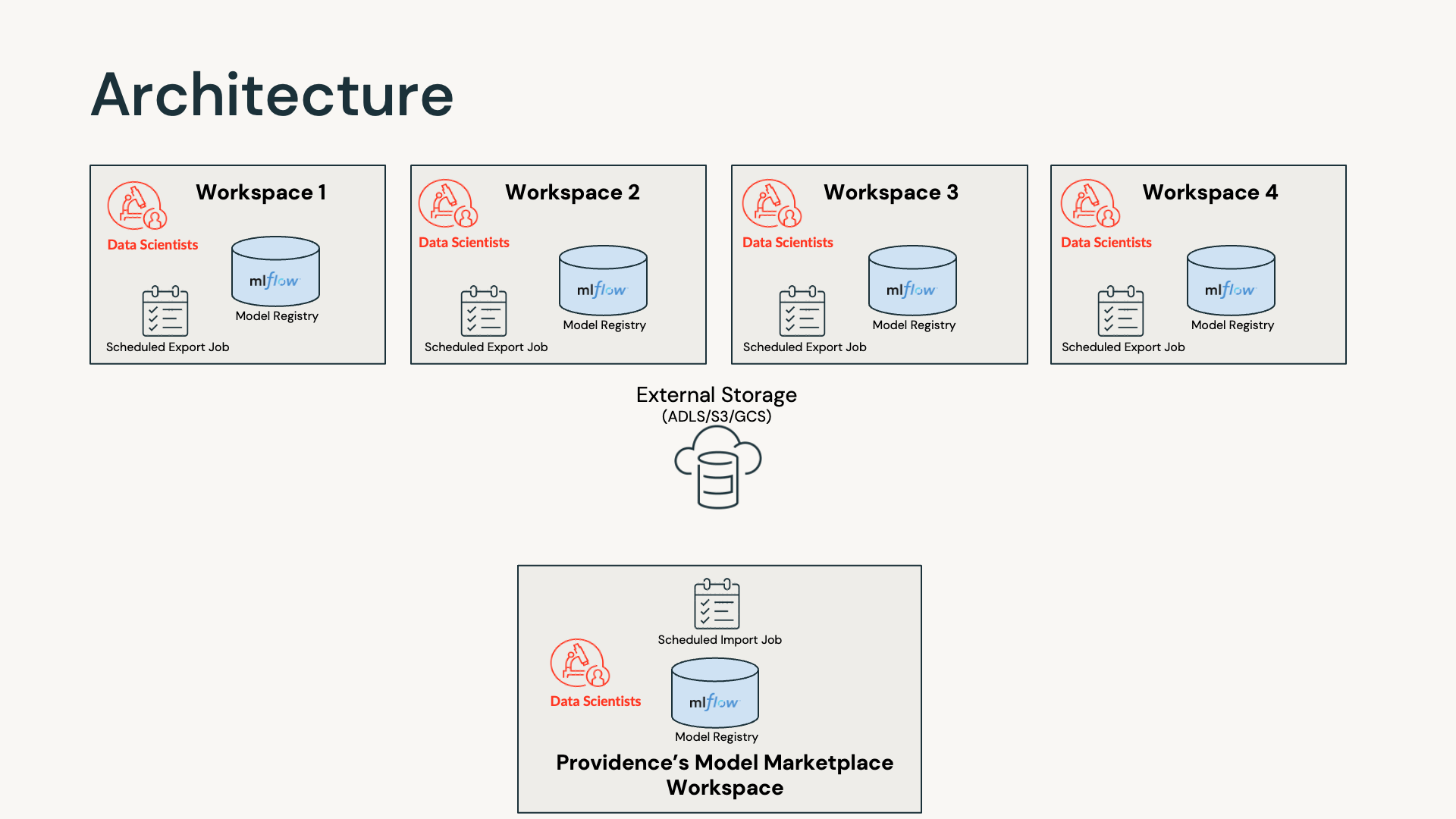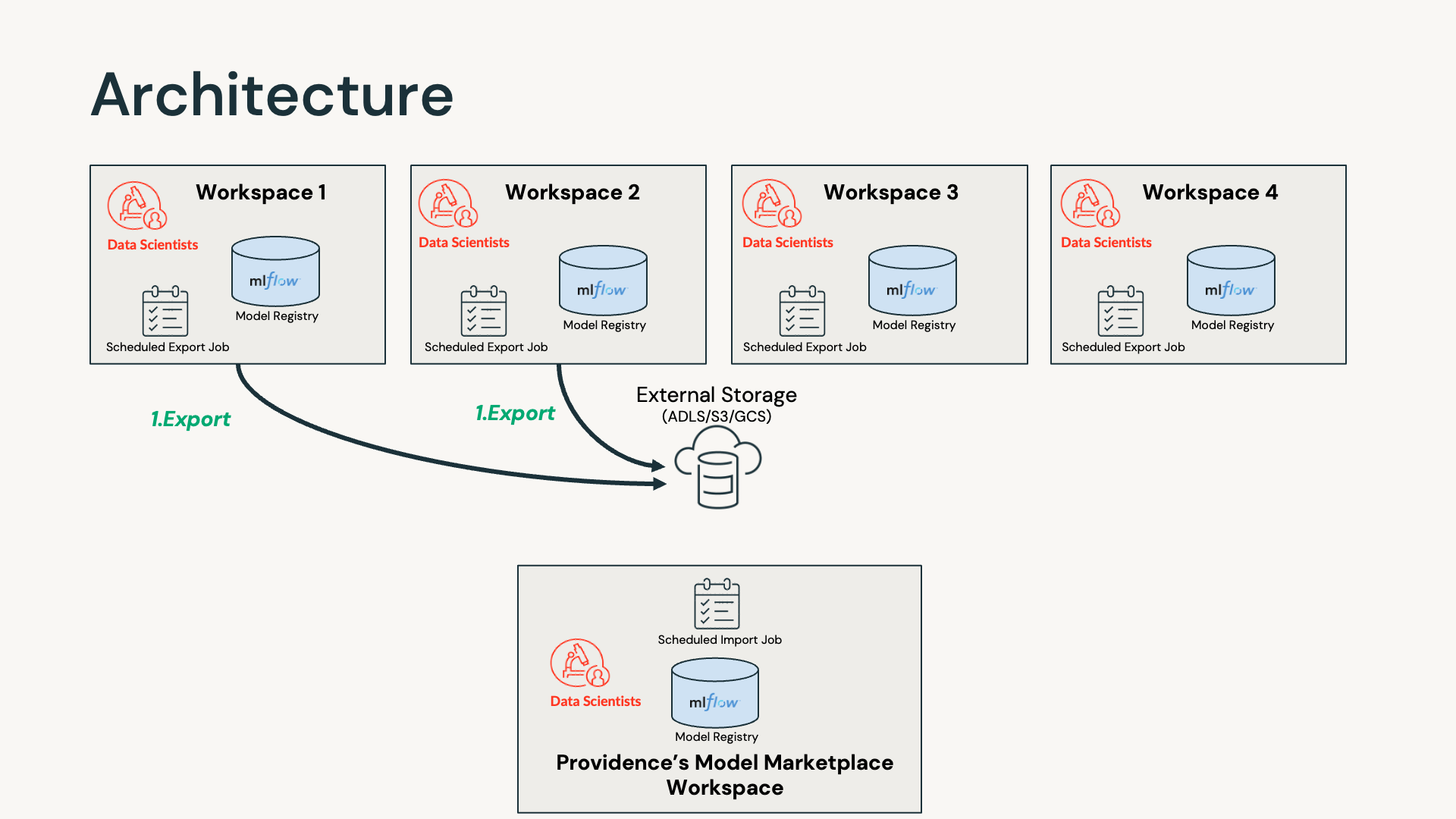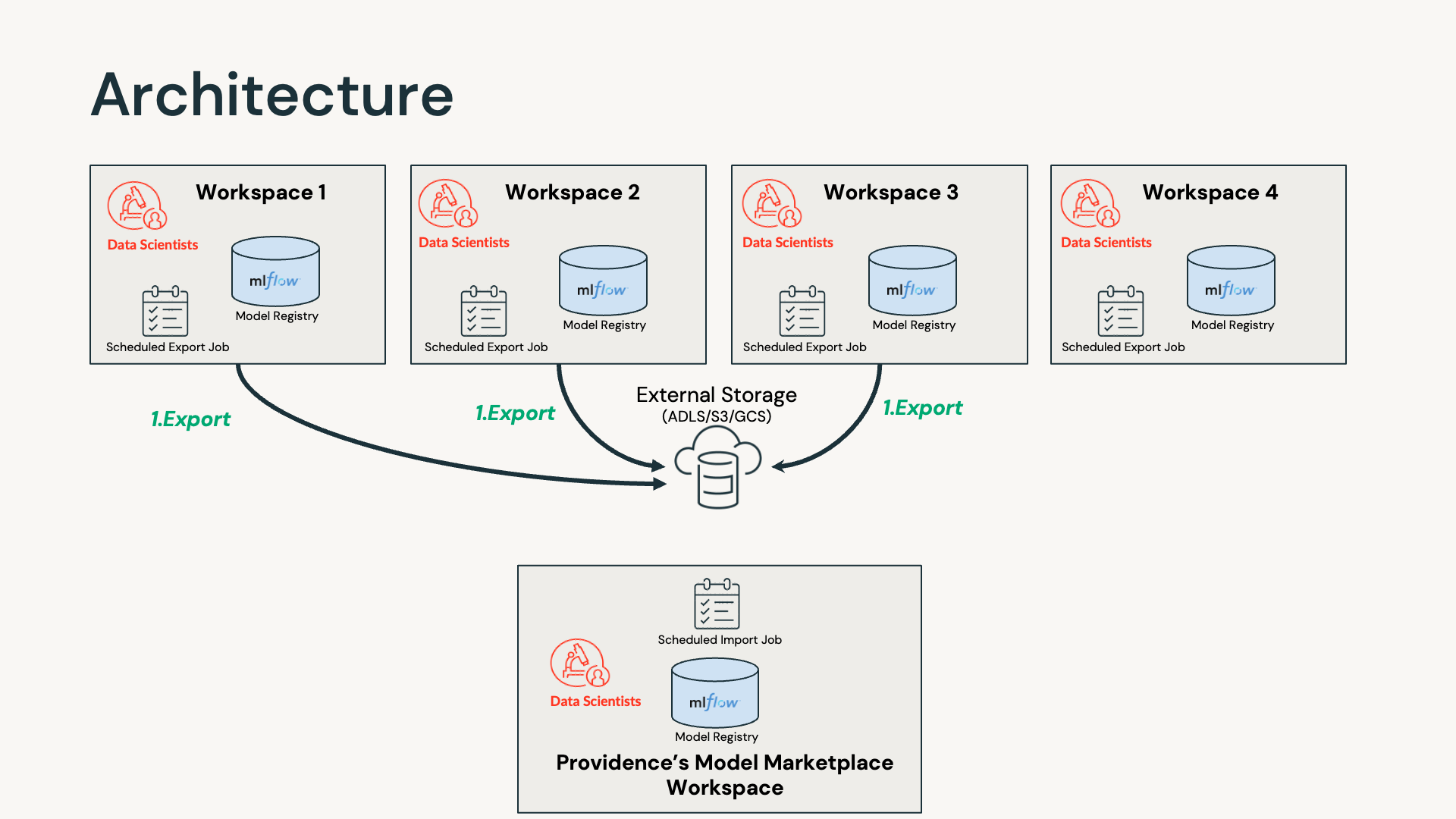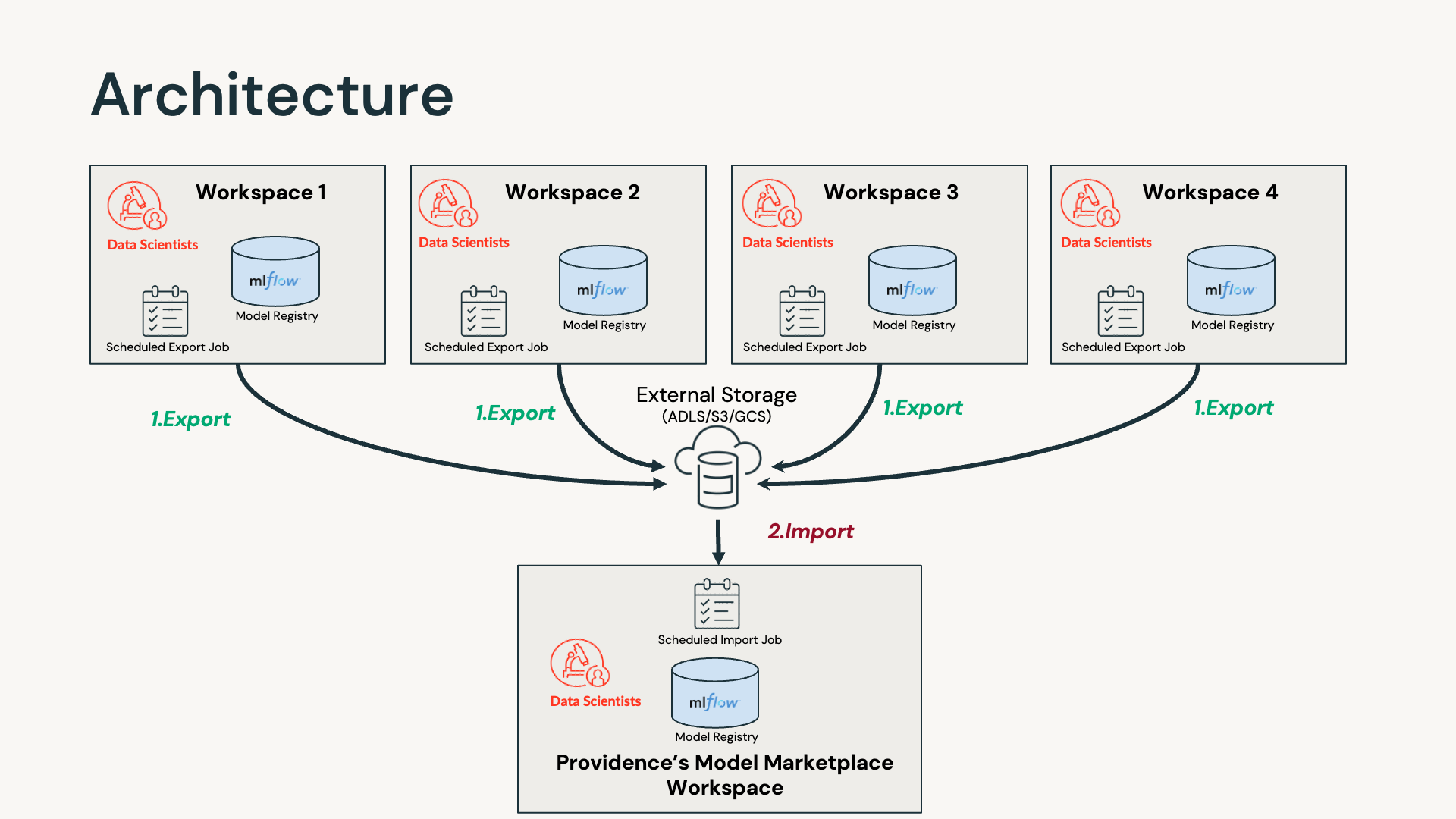
Data Scientists often generate tens of hundreds of models over a short period of time. To better govern the existing models, having all production-grade ML models live in one centralized workspace is ideal so they can be easily looked up or shared across teams.
Databricks workspaces represent a natural division among business groups or teams. In order to have all production versions of ML models live in one curated workspace, Databricks proposed the above diagram for architecture — using external storage storage as an intermediate layer for exporting and importing models.
In this project, Providence was restricted to using Databricks Generally Available features, therefore Models in Unity Catalog functionality was not considered. In general, we proposed 2 high-level steps.
All code and jobs were run by service principals. The code was built on top of the MLflow export/import tool.
The logic of the implementation is straightforward. When data scientists are ready to push a version of a model into production, they will first transition the model stage into "Production" in the MLflow model registry in their dev Databricks workspace. After that, the export and import logic details are explained in the following sections.
The export code is run in all of the dev workspaces. The algorithm, as described below, grabs the latest production version of the model that has not been exported before. Then it exports the corresponding files into DBFS, and copies them into external storage. Those files include model files together with its MLflow experiments and other artifacts. After this latest production version of the model has been exported, we update the description as "Exported Already On …….".
After the export, make the description of the original model's latest production version as "Exported Already On......"
client.update_model_version(
name=model_name,
version=latest_production_version,
description="Exported Already On " + todaysdate + ", old description: " + latest_description_production_version
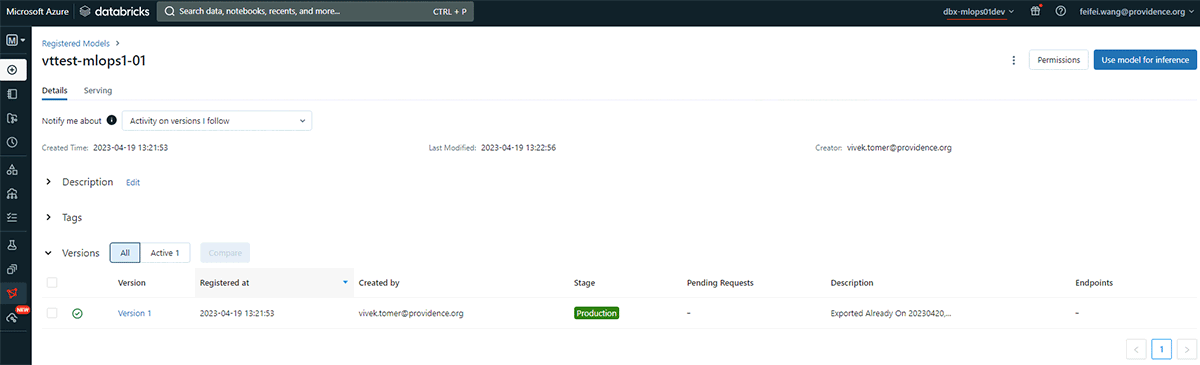
)The two screenshots below demonstrate first exporting the latest production Version 1 model created by Vivek in the "dev01" workspace, then importing it to the "Providence's Models Marketplace" workspace by a service principal.
The export screenshot:
The import screenshot:
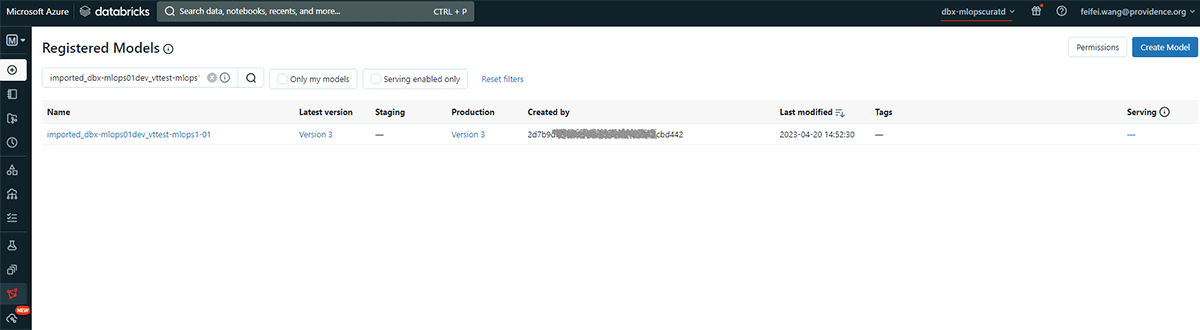
Let's take a look at the import logic for production models from external storage into the "Providence Model Marketplace" workspace.
The project took an evolutionary architecture approach to deal with Databricks features not yet in general availability (GA). For example, "Models in Unity Catalog" offers similar functionality, but (as of the time of this writing) it is in preview. When in GA, "Models in Unity Catalog" would be leveraged to make the curated models available at the Providence Model Marketplace workspace. A Databricks workflow triggered from CI/CD would still be used as the mechanism to apply the corresponding permissions to the approved models.
Providence continues to build upon the work done by Databricks. In recent months, requests to implement large language models (LLMs) in various applications and processes at Providence have significantly increased. As a result, we are fine-tuning open-source LLMs on Providence's EHR data and deploying it on the MLOps platform created in partnership with Databricks.
The DevOps engineering team at Providence is creating a DevOps pull request process to download, distribute and deploy open-source models securely across the enterprise. Providence's MLOps platform is secure, open, and fully automated. A Providence caregiver can easily access any home-brewed or open-source LLM by simply making a pull request.
At Providence, our strength lies in Our Promise of "Know me, care for me, ease my way." Working at our family of organizations means that regardless of your role, we'll walk alongside you in your career, supporting you so you can support others. We provide best-in-class benefits and we foster an inclusive workplace where diversity is valued, and everyone is essential, heard, and respected. Together, our 120,000 caregivers (all employees) serve in over 50 hospitals, over 1,000 clinics and a full range of health and social services across Alaska, California, Montana, New Mexico, Oregon, Texas and Washington. As a comprehensive health care organization, Providence serves more people, advancing best practices, and continue our more than 100-year tradition of serving the poor and vulnerable.
If you are interested in job searching, please feel free to apply to join Providence and the team. Here is Providence's careers website: https://www.providenceiscalling.jobs/
We would like to thank Young Ling, Patrick Leyshock, Robert Kramer and Ramon Porras from Providence for supporting the MLOps project. We would also like to thank Andre Mesarovic, Antonio Pinheirofilho, Tejas Pandit, and Greg Wood for developing the MLflow-export-import tool: https://github.com/mlflow/mlflow-export-import.

