


How Databricks Unity Catalog Helped Amgen Enable Data Governance at Enterprise Scale
This blog authored post by Jaison Dominic, Senior Manager, Information Systems at Amgen, and Lakhan Prajapati, Director of Architecture and Engineering at ZS...
Today's enterprise data estates are vastly different from 10 years ago. Industries have transitioned their analytics from monolithic data platforms (i.e. relational databases, data warehouse appliances) to distributed, scalable, and almost limitless compute and storage capabilities (i.e. data lakes). Data has also been growing at an exponential pace, driving new capabilities of interoperability, creating an ever more connected ecosystem, and unlocking new opportunities for data to shape the way we live.
This drastic shift in the data estate drives the need for teams to find a new way to meet the challenges of exponential data delivery at a rapid pace. As a result, frameworks like data mesh have gained in popularity and success. At its core, data mesh looks to reduce bottlenecks on business teams for data delivery through self service and treating "data-as-a-product" to maximize data insights to scale, be more competitive, and drive innovation.
The cornerstone of this methodology is to move from centralized data delivery teams to decentralized delivery around domains: domains take ownership of data pipelines, cross- domain collaboration is enabled through standardization, data and metadata are discoverable, and data is democratized for self-service.
Democratized and self-service data is counter-intuitive to protecting personal identifiable information (PII). This is exacerbated in healthcare, where organizations face regulatory requirements around protected health information (PHI), which is a subset of PII that specifically relates to an individual's health history and/or status. Often it is the case that data engineering, data analytics, and data science teams do not need full access to PHI to perform job functions and therefore should not have the ability to see PHI. Organizations are slowed down with the burden of creating work-arounds such as data masking (not re-identifiable), de-identification (re-identifiable through tokenization, often involving purchase of third party software), and/or cumbersome governance policies that greatly inhibit the ability to deliver.
Additional complications arise when a downstream team inevitably needs PHI to perform their job function, e.g. clinical care delivery teams. This requires the data to be re-identified, and triggers additional steps that do not align with enterprise security. These additional steps greatly inhibit delivery timelines and increase friction in a data estate.
The aforementioned solutions to PHI and data governance are bandaids applied at the application development level for an enterprise strategy. As such, they are risky and do not scale with today's data estates. A major limiting factor to scale is that traditional data lakes typically lack a secure data governance model and enterprise integration.
Databricks Unity Catalog aims to solve scale and reduce risk by bringing the governance of databases and data warehouses to the cheap cloud storage of the data lake directly to enterprise access and controls. The result is one, consistent model that's fully integrated and applied at a platform level.
Let's demonstrate what this looks like using CMS's Public Use Files to secure PHI data at scale.
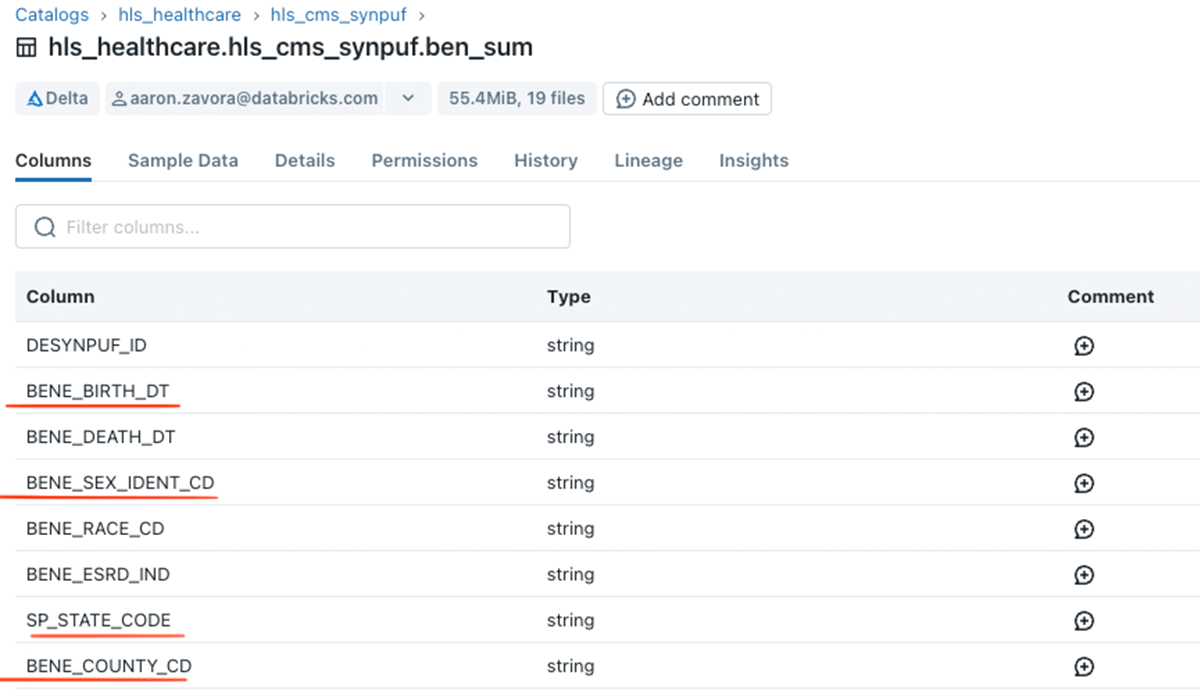
Looking at the beneficiary (member) table in Data Explorer we see PHI columns like birth date, sex, and address information.
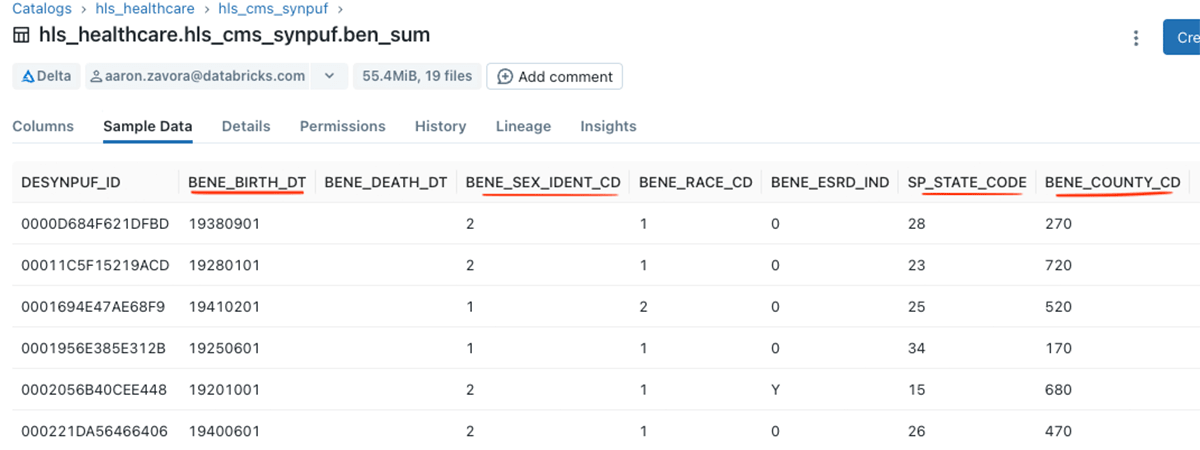
And data is visible to users with access to the table.
Now how do we make PHI in these columns only visible to those who need it for their job functions?
Let's assume my organization has an enterprise group called "pii_viewers" which includes only individuals who should have access to PHI for their job function. I can then apply this security on a per column basis without needing to duplicate datasets or create views. For this example, let's just concern ourselves with the birth date column.
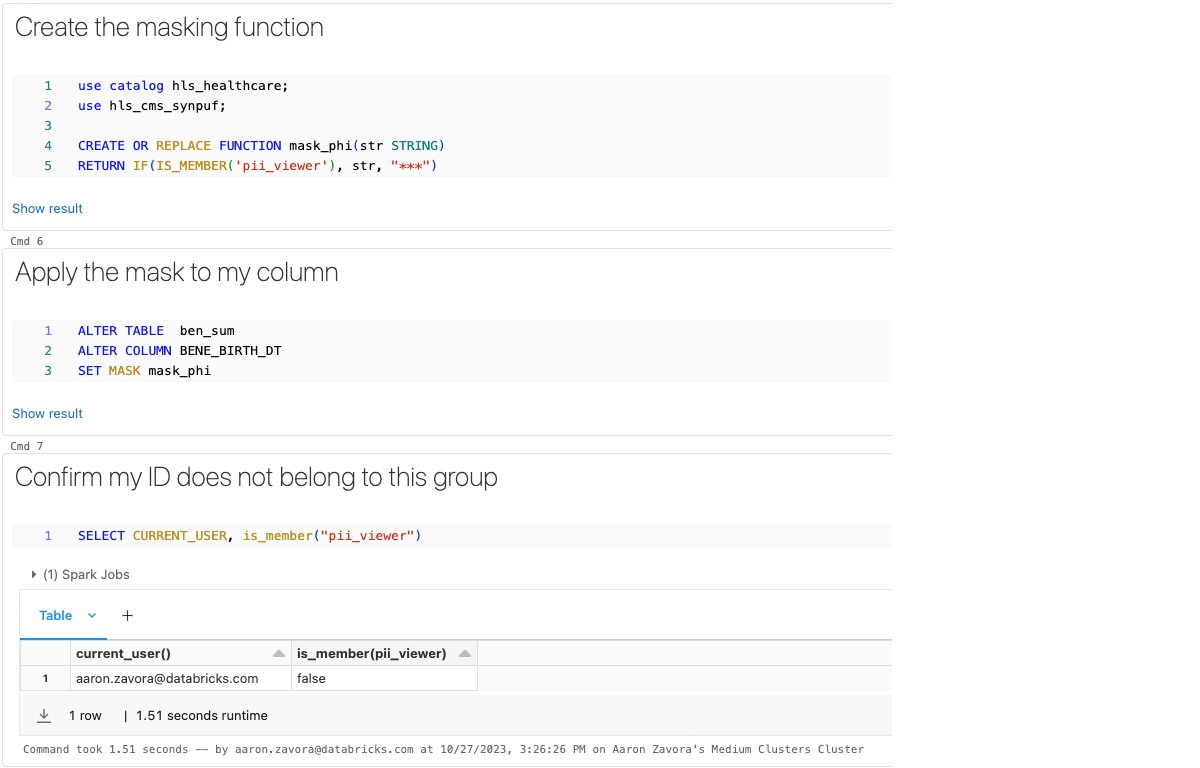
Now, when I query the data I am not able to see this data because I do not belong to the group "pii_viewer".
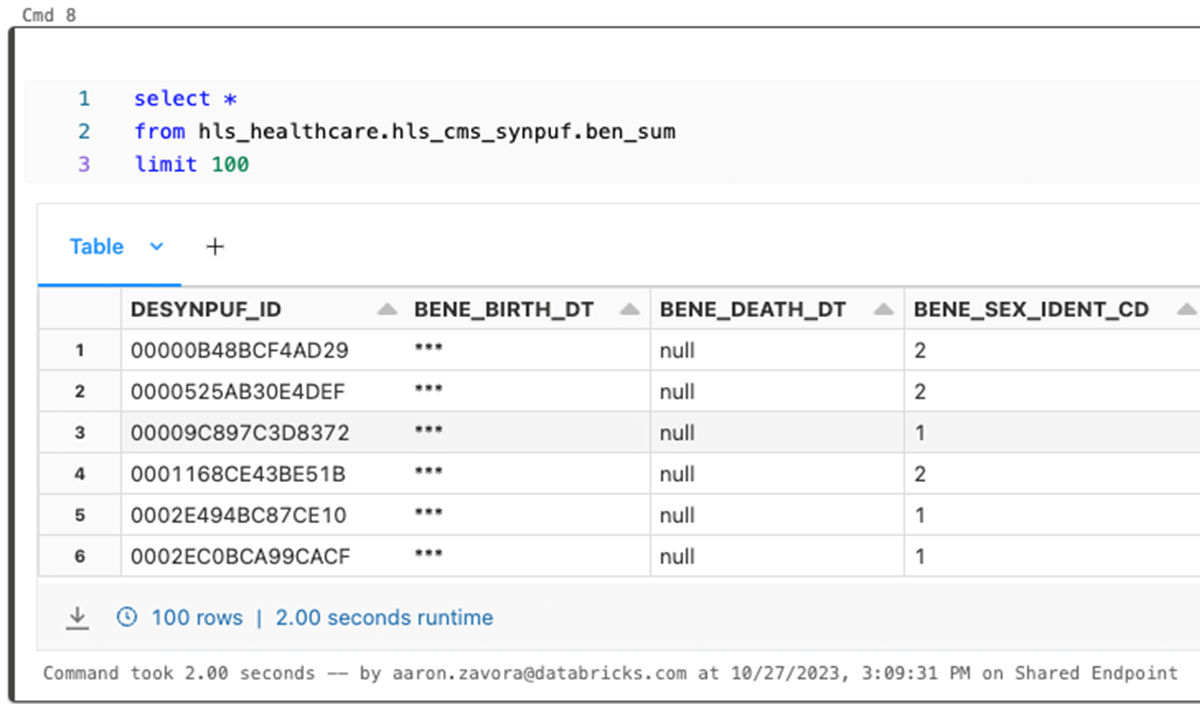
Even after deriving this data downstream to other tables, the column access permissions are persisted.
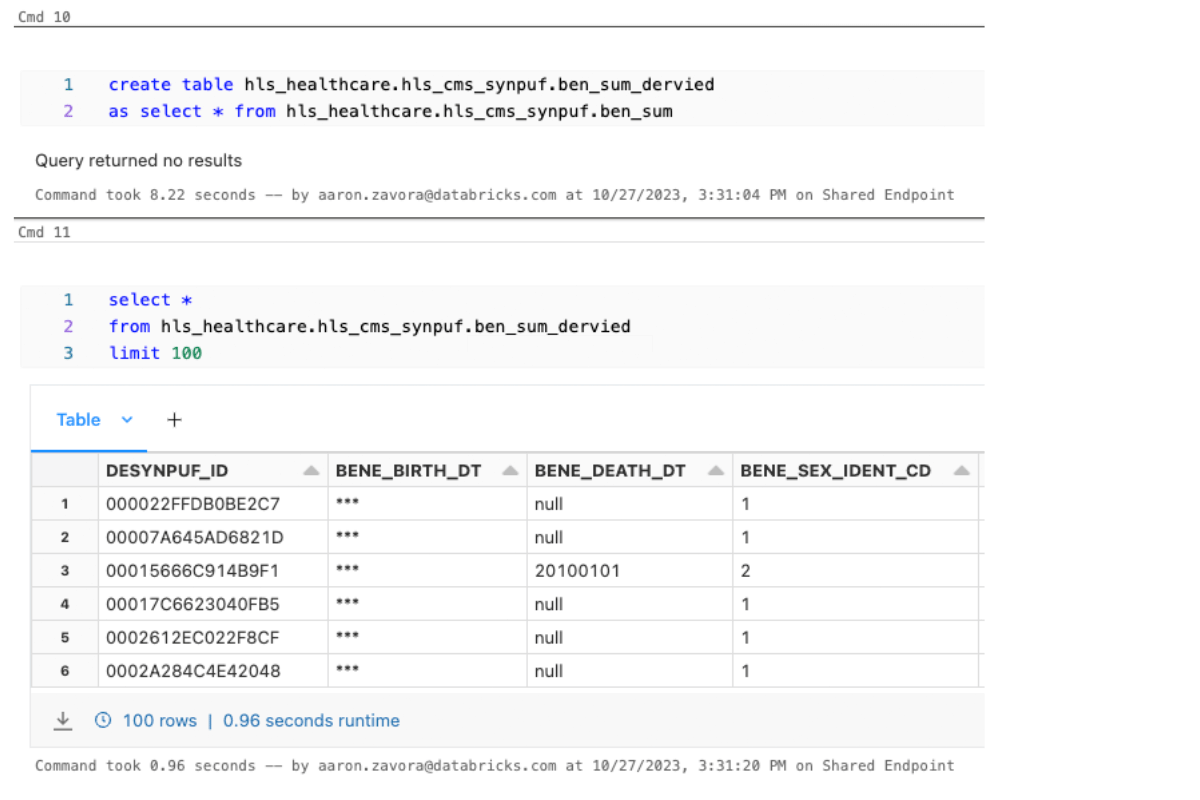
Despite the very short and simple lines of code above, this feature unlocks a very powerful capability to secure your sensitive information like PHI, democratize your data assets and products, and scale compliance with infrastructure instead of scaling with code and labor. Streamlined data access controls lead to more productive teams and higher compliance, and unleash the full potential of enterprise data assets.
Learn more about Unity Catalog, here.

