





Top Three Data Sharing Use Cases With Delta Sharing
Update: Delta Sharing is now generally available on AWS and Azure. Data sharing has become an essential component to drive business value as...
In today's interconnected digital landscape, data sharing and collaboration across organizations and platforms are crucial for modern business operations. Delta Sharing, an innovative open data sharing protocol, empowers organizations to securely share and access data across diverse platforms, prioritizing security and scalability without constraints of vendor or data format.
This blog is dedicated to presenting data replication options within Delta Sharing by exploring architecture guidance tailored to specific data sharing scenarios. Drawing insights from our experiences with many Delta Sharing clients, our goal is to reduce egress costs and improve performance by providing specific data replication alternatives. While live sharing remains suitable for many cross-region data sharing scenarios, there are instances where replicating the entire dataset and establishing a data refresh process for local regional replicas proves to be more cost-efficient. Delta Sharing facilitates this through the utilization of Cloudflare R2 storage, Change Data Feed (CDF) Delta Sharing and Delta Deep Cloning functionalities. As a result of these capabilities, Delta Sharing is highly valued by clients for empowering users and providing exceptional flexibility in meeting their data sharing needs.
Databricks and the Linux Foundation developed Delta Sharing to provide the first open source approach to data sharing across data, analytics and AI. Customers can share live data across platforms, clouds and regions with strong security and governance. Whether you use the open source project by self-hosting, or the fully managed Delta Sharing on Databricks – both provide a platform-agnostic, flexible, and cost-effective solution for global data delivery. Databricks customers receive additional benefits within a managed environment that minimizes administrative overhead and integrates natively with Databricks Unity Catalog. This integration offers a streamlined experience for data sharing within and across organizations.
Delta Sharing on Databricks has experienced widespread adoption across various collaboration scenarios since its general availability in August 2022.
In this blog, we will explore two common architectural patterns where Delta Sharing has played a pivotal role in enabling and enhancing critical business scenarios:
As part of this blog, we will also demonstrate that the Delta Sharing deployment architecture is flexible and can be seamlessly extended to fulfill new data sharing requirements.
In this use case, we will illustrate a common deployment pattern of Delta Sharing among our customers where there is a business need to share some of the data across regions, such as having a QA team in separate regions or a reporting team interested in business activity data on a global basis. Usually sharing Intra-enterprise tables involves:
In this scenario, both the data provider's and the data recipient's business units share the same Unity Catalog account, but they have different metastores on Databricks.
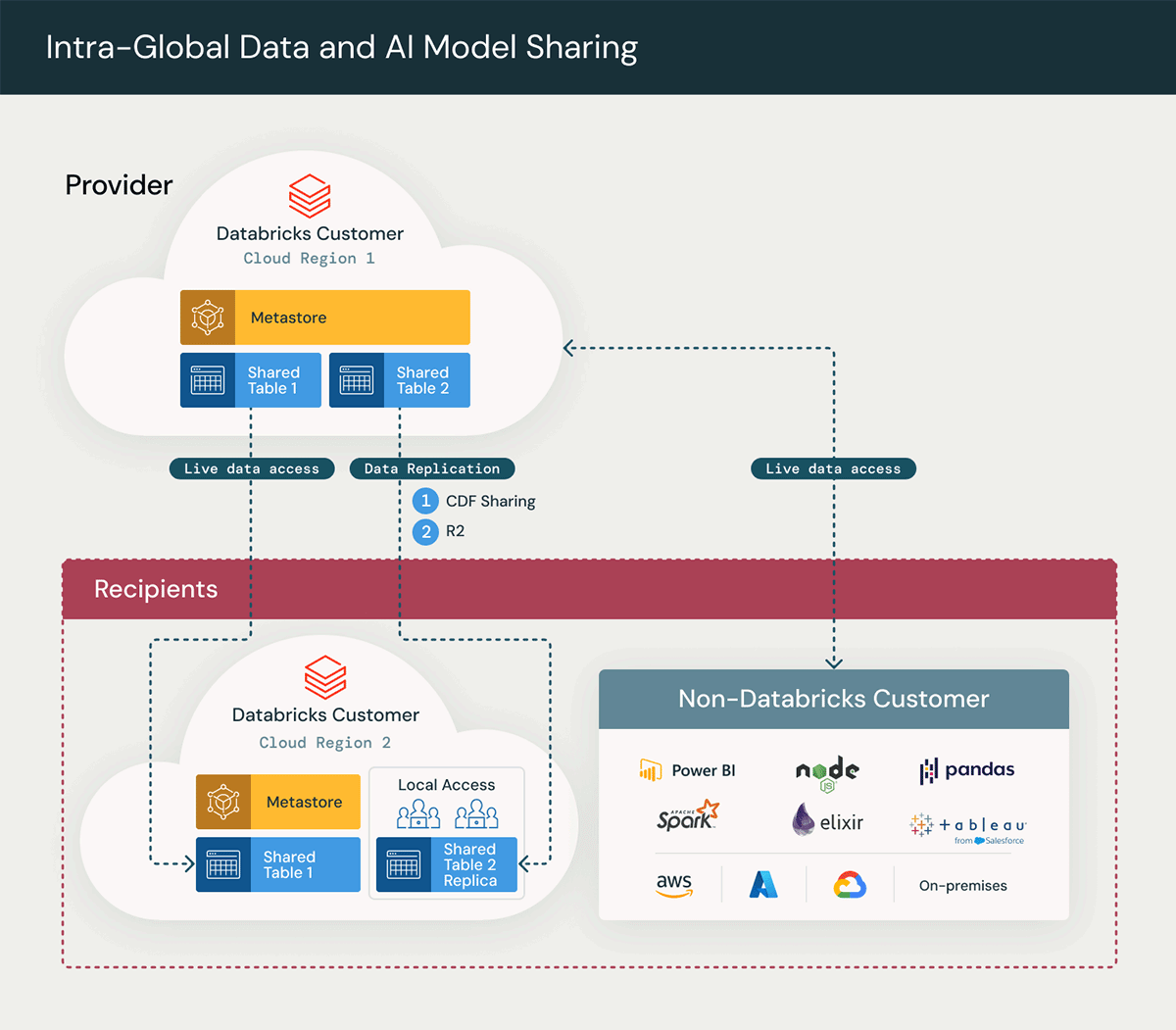
The above diagram illustrates a high-level architecture of the Delta Sharing solution, highlighting the key steps in the Delta Sharing process:
This option requires sharing the table history and enabling the change data feed (CDF) which must be explicitly enabled in the setup code by setting the table property delta.enableChangeDataFeed = true using the Create/Alter table commands.
Furthermore, when adding the table to the Share, ensure that it is added with the CDF option, as shown in the example below.
ALTER SHARE flights_data_share
ADD TABLE db_flights.flights
AS db_flights.flights_with_cdf
WITH CHANGE DATA FEED;Once Data is added or updated, Changes can be accessed as in this example
-- View changes as of version 1
SELECT * FROM table_changes('db_flights.flights', 1)On the recipient side, changes can be accessed and merged into a local copy of the data in a similar way as in this notebook. Propagating the changes from the shared table to a local replica can be orchestrated using a Databricks workflow job.
R2 is an excellent option for all Delta Sharing scenarios because customers can fully realize the potential of sharing without worrying about any unpredictable egress charges. It is discussed in detail later in this blog.
Another special case option for intra-enterprise sharing is to use Delta deep clone when sharing within the same Databricks cloud account. Deep Cloning is a Delta functionality that copies both the source table data and the metadata of the existing table to the clone target. Additionally, deep clone command has the ability to identify new data and refresh accordingly. Here is the syntax:
CREATE TABLE [IF NOT EXISTS] table_name DEEP CLONE source_table_name
[TBLPROPERTIES clause] [LOCATION path]The previous command runs on the recipient side where source_table_name is the shared table and table_name is the local copy of the data that users can access.
A simple Databricks Workflows job can be scheduled for an incremental refresh of the data with recent updates using the following command:
CREATE OR REPLACE TABLE table_name DEEP CLONE source_table_nameThe same use case can easily be extended to share data with external partners and clients on the Databricks Platform or any other platform. This is another common extended pattern where partners and external clients, who are not on Databricks, wish to access this data through Excel, Power BI, Pandas, and other compatible software like Oracle.
Another common scenario pattern arises when a business is focused on sharing data with clients, particularly in cases involving data aggregator enterprises or when the primary business function is collecting data on behalf of clients. A data aggregator, as an entity, specializes in collecting and merging data from diverse sources into a unified, cohesive dataset. These data shares are instrumental in serving diverse business needs such as business decision-making, market analysis, research, and supporting overall business operations.
The data sharing model in this pattern does the following:
In general, this can typically be achieved by the provider establishing a Databricks workspace in each cloud and replicating data using CDF on a shared table (as discussed above) across all three clouds to enhance performance and reduce egress costs. Then within each cloud region, data can be shared with the appropriate clients and partners.
However, a new, more efficient and straightforward approach can be employed by utilizing R2 through Cloudflare with Databricks, currently in private preview.
Cloudflare R2 integration with Databricks will enable organizations to safely, simply, and affordably share and collaborate on live data. With Cloudflare and Databricks, joint customers can eliminate the complexity and dynamic costs that stand in the way of the full potential of multi-cloud analytics and AI initiatives. Specifically, there will be zero egress fees and no need for complex data transfers or costly replication of data sets across regions.
Using this option requires the following steps:
As explained above, these approaches demonstrate various methods of on-demand data replication, each with its distinct advantages and specific requirements, making them suitable for various use cases.
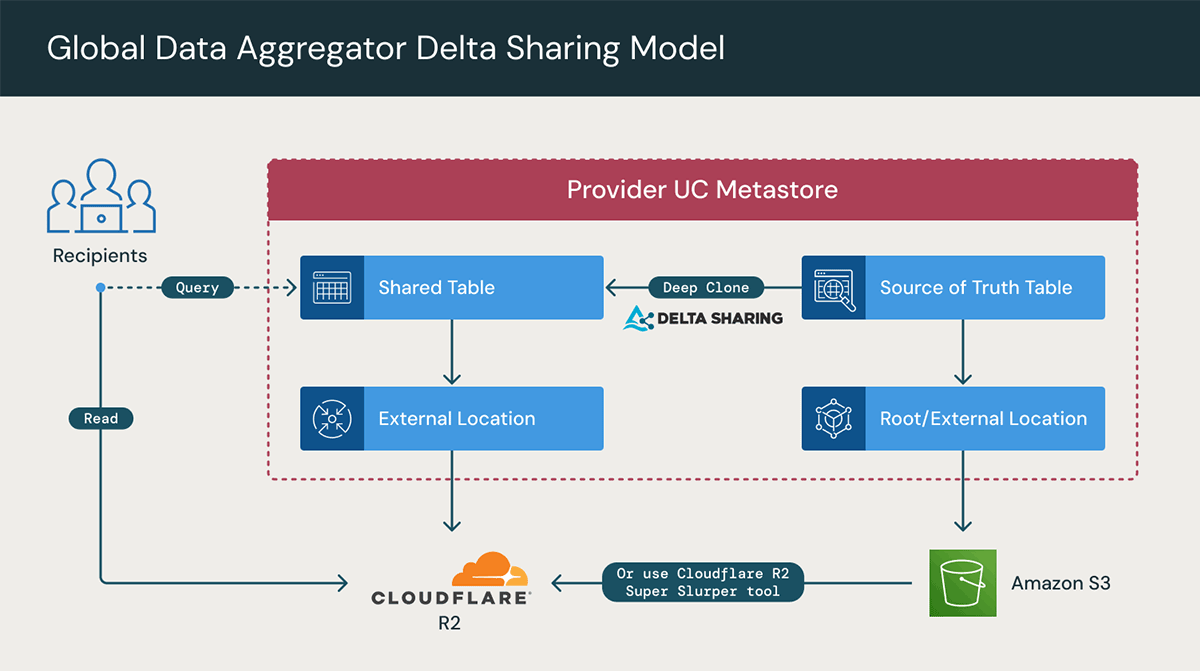
All three previous mechanisms enable Delta Sharing users to create a local copy, to minimize egress fees, especially across clouds and regions. The table below provides a quick summary to differentiate between these options.
| Data Replication Tool | Key highlights | Recommendation |
|---|---|---|
| Change data feed on a shared table |
| Use for external Sharing with partners/clients across regions |
| Cloudflare R2 with Databricks |
| Strongly recommended for large scale Delta Sharing in terms of number of shares and 2+ regions |
| Delta Deep Clone |
| Recommended when sharing internally across regions |
Delta Sharing is open, flexible, and cost-efficient and on Databricks it supports a broad spectrum of data assets, including notebooks, volumes, and AI models. In addition, several optimizations have significantly enhanced the performance of Delta Sharing protocols. Databricks' ongoing investment in Delta Sharing capabilities, including improved monitoring, scalability, ease of use, and observability, underscores its commitment to enhancing the user experience and ensuring that Delta Sharing remains at the forefront of data collaboration for the future.
Throughout this blog, we have provided architectural guidance based on our experience with many Delta Sharing customers. Our primary focus is on cost management and performance. While live sharing is suitable for many cross-region data sharing scenarios, we have explored instances where replicating the entire dataset and establishing a data refresh process for local regional replicas proves to be more cost-efficient. Delta Sharing facilitates this through the utilization of R2 and CDF Delta Sharing functionalities, providing users with enhanced flexibility.
In the Intra-Enterprise Cross-Regional Data Sharing use case, Delta Sharing excels in sharing large tables with varied access patterns. Local replication, facilitated by CDF sharing, ensures optimal performance and cost management. Additionally, R2 through Cloudflare with Databricks offers an efficient option for large-scale Delta Sharing across multiple regions and clouds.
To learn more about how to integrate Delta Sharing into your data collaboration strategy check out the latest resources:


