


Automating ML, Scoring, and Alerting for Detecting Criminals and Nation States Through DNS Analytics
This blog is part two of our DNS Analytics blog, where you learned how to detect a remote access trojan using passive DNS...
Successfully building GenAI applications means going beyond just leveraging the latest cutting-edge models. It requires the development of compound AI systems that integrate data, models, and infrastructure in a flexible, scalable, and production-ready way. This entails access to both open source and proprietary models, vector databases, the ability to fine-tune models and query structured data, create endpoints, prepare data, manage costs, and monitor solutions.
In this blog, we’ll walk through the GenAI transformation for a leading venture capital firm (referred to as "VC" throughout the blog) that is also an investor in Databricks. In addition to driving innovation internally, this VC wanted to better understand opportunities to build GenAI applications to guide their future investments. The VC developed multiple GenAI use cases, including a Q&A interface to query information from their structured fund data, such as “How much did we invest in Databricks, and what is its current value?” They also built an IT assistant to respond to user questions, significantly reducing response turn-around time by the IT department. Additional use cases have been and are being rapidly developed. In this blog, we will walk through the specifics of these two initial applications with a focus on the framework currently being extended to new applications in collaboration with Databricks Professional Services.
The VC has many general partners (GP) who invest strategically in technology startups across multiple funds. VC already has powerful, self-service dashboards that resolve many GP requests, but specific analyses must go through a manual process by strategists and analysts who need to write and execute SQL queries in order to get them the information they need. VC asked for our help in using GenAI to automate this process in collaboration with their analysts. The goal was to set up a Slackbot that could automate most of the common types of questions being asked by GPs, reducing the response time and freeing up analysts to work on more complex tasks.
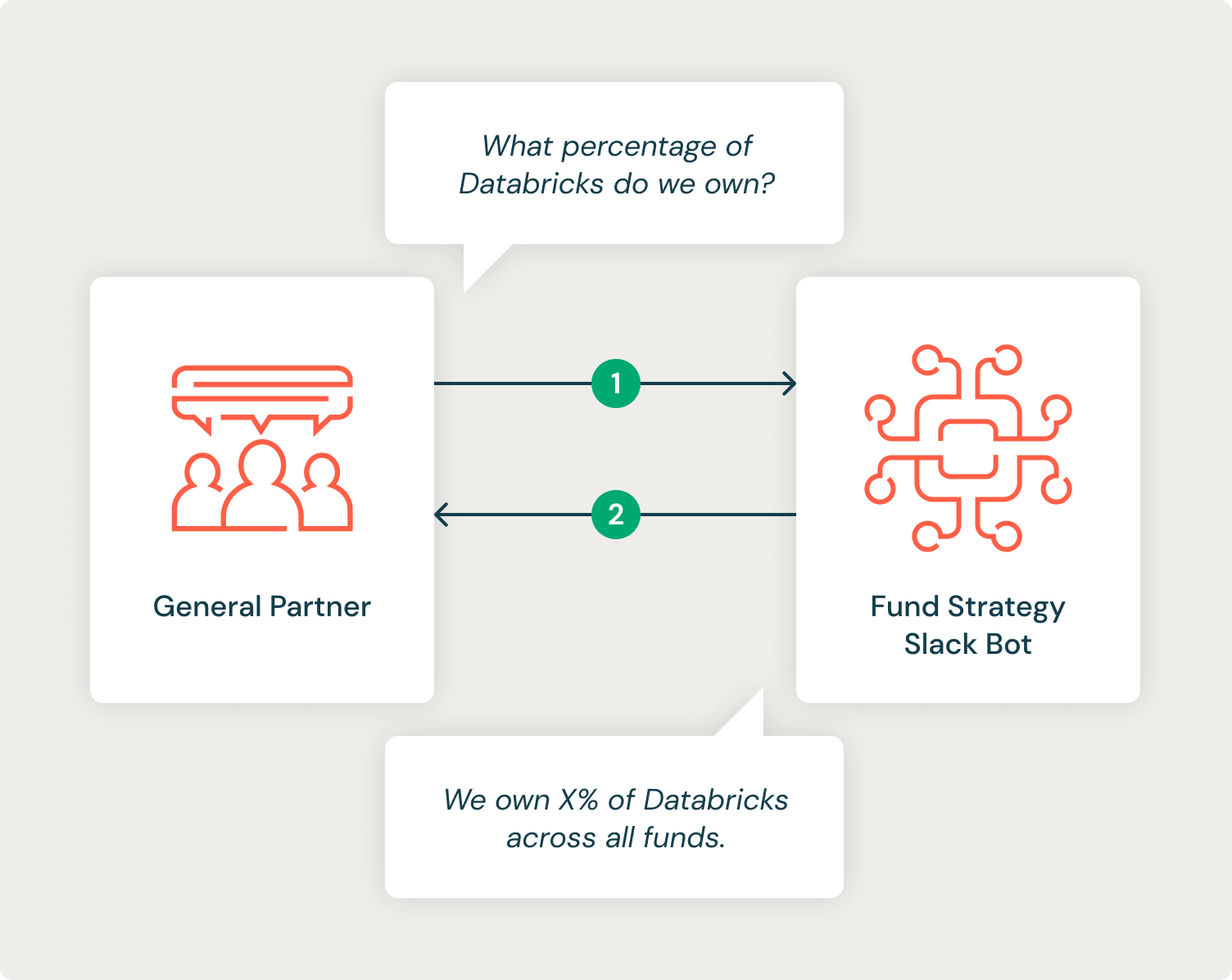
To build this system, we needed to leverage the power of LLMs to generate SQL code, execute and debug the generated SQL, and interpret the returned structured data to answer the question in natural language.
We also considered some of the implicit knowledge of the analysts when they complete these requests, such as:
Our system should ask clarifying questions if the user’s intent isn’t clear from their question. For example, if a user asks about “Adam’s investments” and there are two general partners named Adam, it should clarify which Adam the user wants to know about.
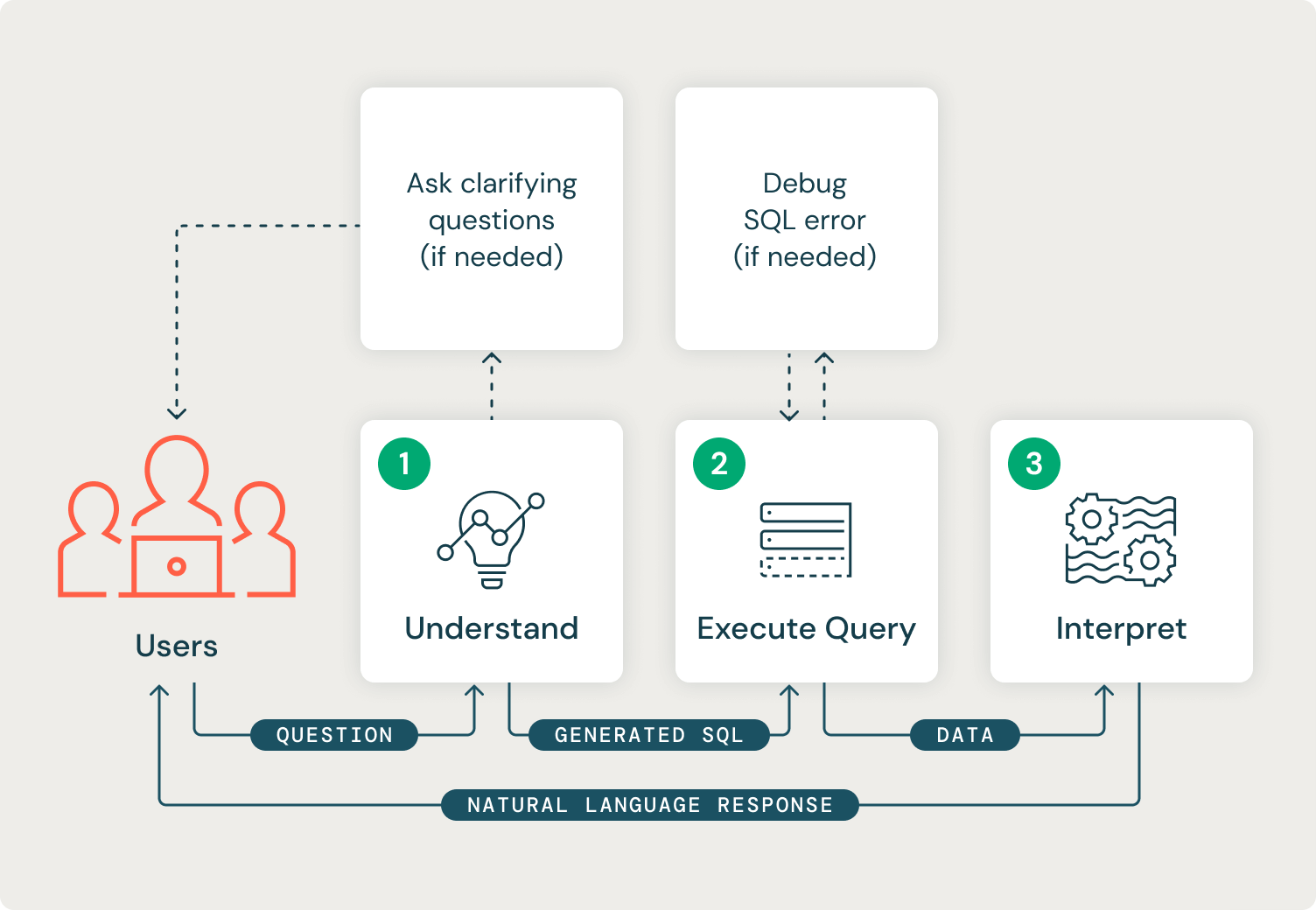
Our system should also continually progress through three distinct stages. The first stage is to understand the user’s request intent. In this stage, our system should understand the available data tables and determine whether it has enough information from the user to generate a valid SQL query to accomplish the desired task. If it does not have enough information, it should ask the user a clarifying question and restart the process. The output of the first stage will be a valid SQL string.
The second stage is the execution of the generated SQL and automated debugging of any returned errors or data issues. The output of this stage will be a data frame containing the data required to answer the user’s question.
The third and final stage interprets the data results to generate a natural language response to the user. This stage's output will be a string response.
It is possible to build this system with an agent approach (known as ReAct) or a Finite State Machine (FSM). Agent approaches excel in complex and dynamic environments, when tasks may need to be used in different combinations or orders and when the choice of task selection is ambiguous. Agents tend to bring along complexity in debugging, memory management, controllability, and interpretability. FSM-based systems are best applied to simpler, well-defined processes with deterministic outcomes. FSM’s simplified and deterministic flow allows for easier debugging and interpretability. FSMs tend to be less flexible than agent-based systems and can be difficult to scale if many possible states are desired.
We decided on an FSM approach because:
In order to build our system we needed a hosted endpoint able to run the model and respond to requests from the Slackbot. Databricks Model Serving allows easy, scalable, production-ready model endpoints that can host any native MLflow model. Using Databricks External Models and Model Serving allowed us to quickly benchmark a variety of models and select the best-performing model. Databricks features a built-in integration of MLflow that makes it simple to use one interface for managing experimentation, evaluation, and deployment. Specifically, MLflow allows tracking of a generic Python function model (pyfunc). Generic Python function models can be used to quickly wrap and log any Python class as a model. We used this pattern to iterate quickly on a core unit-testable class, which we then wrapped in a pyfunc to log to MLflow.
Each distinct state of our FSM had well-defined inputs, outputs, and execution patterns:
VC wrapped the API call to the Model Serving endpoint in a Slackbot and deployed it to their internal Slack workspace. We took advantage of Slack’s built-in threads to store a conversational state which allowed GPs to ask follow-up questions.
One particular challenge in this project was evaluation. Since this system will be providing financial information to GPs who are making decisions, the accuracy of the responses is paramount. We needed to evaluate the SQL queries that were generated, the returned data, and the final response. In an unstructured RAG, metrics like ROUGE are often used to compare a final result against a reference answer from an evaluation set. For our system, it is possible to have a high ROUGE score due to similar language but a completely wrong numeric result in the response!
Evaluating SQL queries can also be challenging. It is possible to write many different SQL queries to accomplish the same thing. It’s also possible for column names to be aliased, or additional columns retrieved which our evaluation data didn’t anticipate. For example, a question like “What are Rafael’s investments this year?” might trigger the generation of a SQL query that only returns the company names of investments or may additionally include the amount invested.
We solved the above problems by evaluating 3 metrics on our evaluation set:
Feedback from internal VC stakeholders was very positive and high metrics were observed during the model creation. Some example conversations (scrubbed of identifying info) are below:

Like many companies, VC employees can send emails to an IT email alias to get assistance from their IT helpdesk, which in turn creates a ticket in their IT ticketing system. The IT department stores its internal documentation in Confluence, and the goal of this use case was to find the appropriate Confluence documentation and reply to the IT ticket with links to the relevant documentation along with instructions for resolving the user’s request.
Using APIs provided by the IT ticketing system, our GenAI use case runs a job that periodically checks for new tickets and processes them in batches. Generated summaries, links, and final responses are posted back to the IT ticketing system. This allows the IT department to continue using its tool of choice while leveraging the information gained from this GenAI solution.
The IT documentation from Confluence is extracted by API and put in a vector store for retrieval (Databricks Vector Search, FAISS, Chroma, etc.). As is often the case with RAG on a knowledge repository of internal documents, we iterated on the confluence pages to clean the content. We quickly learned that passing in the raw email threads resulted in poor retrieval of Confluence context due to noisy elements like email signatures. We added an LLM step before retrieval to summarize the email chain into a single-sentence question. This served two purposes: it improved retrieval dramatically, and it allowed the IT department to read a single-sentence summary of the request rather than having to scroll through an email exchange.

After retrieving the proper Confluence documentation, our GenAI helpdesk assistant generates a potential response to the user’s summarized question and posts all of the information (summarized question, confluence links, and answer) back to the IT ticket as a private note that only the IT department can see. The IT department can then use this information to respond to the user’s ticket.
Similar to the previous use case, this RAG implementation was written as a wrapped PyFunc for easy deployment to a streaming job that could process new records as they arrived.
Databricks workflows and Spark structured streaming were utilized to load the model out of MLflow, apply it to the IT tickets, and post back the results. Databricks External Models was used to easily switch between LLM models and find the model with the best performance. This design pattern allows for models to be easily switched out for cheaper, faster, and better options as they become available. Workflows were automatically deployed using Databricks Asset Bundles, Databricks’ solution for productionizing workflows into CI/CD systems.
The IT helpdesk assistant has been an instant success, adding key pieces of information to each IT ticket to accelerate the IT helpdesk’s resolution. Below is an example of an IT ticket and response from the IT helpdesk assistant.
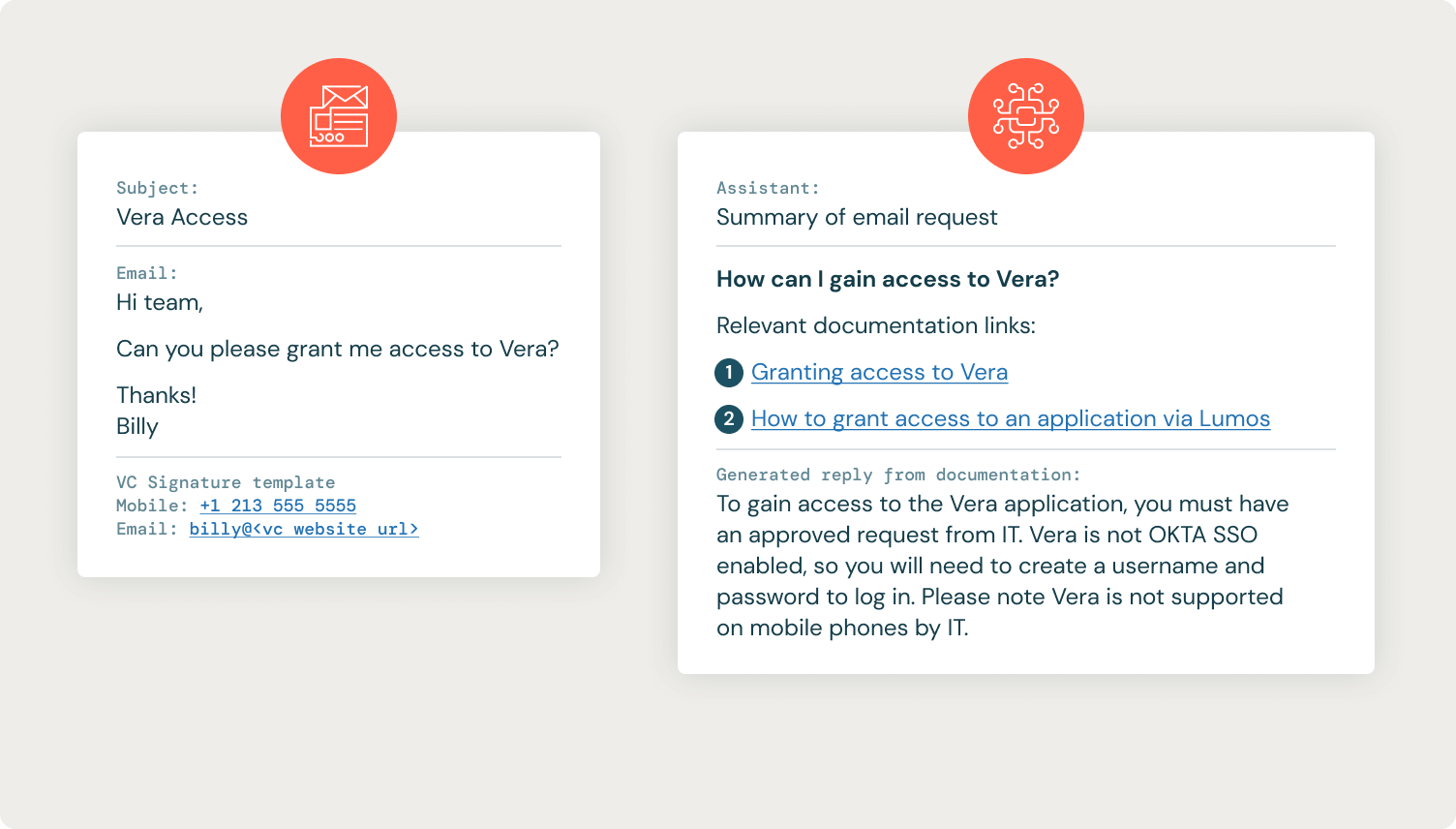
Many requests still require the IT department to process them manually, but by providing a quick summary of the required steps and directly linking the IT helpdesk to the relevant Confluence documentation pages, we were able to speed up the resolution process.
These solutions enabled the VC to launch their first production GenAI applications and prototype solutions to new use cases. Databricks is enabling the next generation of compound AI systems across the GenAI maturity process. By standardizing across a set of tools for data processing, vector retrieval, deploying endpoints, fine-tuning models, and results monitoring, companies can create a production GenAI framework that allows them to more easily create applications, control costs, and adapt to new innovations in this rapidly-changing environment.
VC is further developing these projects as it evaluates fine-tuning; for example, they are adapting the tone of the GenAI IT assistant’s responses to better resemble their IT department. Through Databricks’ acquisition of MosaicML, Databricks is able to simplify the fine-tuning process, allowing businesses to easily customize GenAI models with their data via instruction fine-tuning or continued pretraining. Upcoming features will allow users to quickly deploy a RAG system to a chat-like interface that can gather user feedback across their organization. Databricks recognizes that organizations across all industries are rapidly adopting GenAI, and businesses that find ways to quickly work through technical barriers will have a strong competitive advantage.
Learn more:

