
Traditional Software Development Lifecycle (SDLC) makes assumptions about the organization of work that are no longer always true in Low and No Code working patterns. Practices centered on software engineering principles can create a barrier to entry for teams with skilled data wranglers looking to take their infrastructure to the next level with cloud-native tools like Matillion for the Snowflake Data Cloud.
With the “Data Productivity Cloud” launch, Matillion has achieved a balance of simplifying source control, collaboration, and dataops by elevating Git integration to a “first-class citizen” within the framework.
In Matillion ETL, the Git integration enables an organization to connect to any Git offering (e.g., Bitbucket, Github) to allow advanced workflows. In the latest previews of Matillion Designer, we can see that source control is seamlessly incorporated. Best Git practices can be adopted by learning as few as three new concepts: branch, commit, and merge.
That begs the question, if it is so easy to learn, “Why formalize a concept like ZDLC?” The next-generation Matillion Designer SaaS offering balances accessibility with a very minor learning curve on Git. For Matillion ETL, the Git integration requires a stronger understanding of the workflows and systems to effectively manage a larger team.
When a new entrant to ETL development reads this article, they could easily have mastered Matillion Designer’s methods or read through the Matillion Versioning Documentation to develop their own approach to ZDLC.
This article aims to provide a perspective to help infrastructure administrators appreciate that enabling many small teams on modularized efforts can be faster and achieve better results than building one very large development team with many governance constraints.
What is Zero-Code Development Life Cycle (ZDLC)?
Zero-Code Development Life Cycle (ZDLC) is the recognition that Matillion for Snowflake is a new breed of ETL tool that allows a full spectrum of users and use cases to operate concurrently on the same platform for the same organization. An analytics program’s maturity curve is not navigated by all members at the same rate. By separating teams and individuals across multiple projects in Matillion and allowing varying scales of governance and control to be applied across those projects, process bottlenecks in both delivering analytics and in maintaining a pipeline of growing talent are solved.
ZDLC is a time-honored practice among data professionals who have grown their careers with the productivity tools available to most business users, such as Microsoft Excel and Access. The hallmarks of this method are modular design and effective organization skills.
This method of managing analytics workflows and data products is particularly effective when ownership of specific segments of work is contained to one person. In contrast, SDLC is the best approach when multiple team members are working on the same code “files” or “jobs.”
This is typical when code-bases support monolithic software programs, that is, the platform or program is created as a single functional unit rather than multiple functional modules, each related but independent of each other.
The overhead of managing a Github repository and workflows to branch, commit, and merge code changes is relatively low compared to the benefits. When many developers are contributing small, incremental changes to the same code base, “control” is the most important focus to maintain quality. In a budding Analytics Engineering environment, speed to insight is more highly valued.
This can be achieved by “widening the aperture of users who can make data business-ready.” This is a key component of the “Data Productivity Cloud” and closing the ETL gap with Matillion. Instead of building a single monolith, enable multiple teams to take ownership of a project and an aspect of the ETL.
Data literacy is increasing fast, and team members capable of administrating a business unit’s transactional system can also perform the cloud ETL of that system data to a Snowflake database via Matillion. Decoupling the component pieces and empowering multiple teams on separate Matillion projects are the hallmarks of ZDLC development.
In this blog post, we’ll discuss use cases for Zero-Code Development Life Cycle (ZDLC) in Matillion.
When Is ZDLC Better Than SDLC?
Analytics platforms have highly repeatable functional stages that lend themselves to being broken down into separate functional processes. In transactional applications, the data is subject to a myriad of business rules updating and changing the entire corpus of system data at any time.
In analytics applications, however, a body of batched data (or even streamed data) extracted from the transactional systems moves inexorably in one direction; from ingestion to data product. Jargon such as “directed acyclic graph” used by software engineers is unhelpful and even damaging to the business stakeholder conversations. Every Excel user knows better than to create “circular references” in their formulas. “Cyclic graphs” are unheard of in analytics.
Exceptions exist for machine learning which is fundamentally based on iterative passes at data refinement and selection. Complex data sharing practices across a large organization with critical dependencies may also merit the rigor of software development and governance.
The highly repeatable and uni-directional flow of data means that a simple approach can be taken with analytics while still maintaining basic rigor to protect the integrity of the workflows built. In addition, breaking the human and data workflows into modular components enables this simplification.
Modularity Is Key
Designing independent modular teams and processes is key to the ZDLC approach. Small teams of 2-5 analytics engineers responsible for the data products in a company’s business unit is a prime example.
This is one of many excellent use cases for Matillion ETL for Snowflake, where the baseline licensing begins at five concurrent users for the lightest-weight implementation.
In this scenario, a business unit has a team of dedicated analysts and/or analytics engineers responsible for creating data products to drive decision-making for the business unit. To further illustrate, let’s assume this is a marketing analytics team who leverages data from several transactional systems.
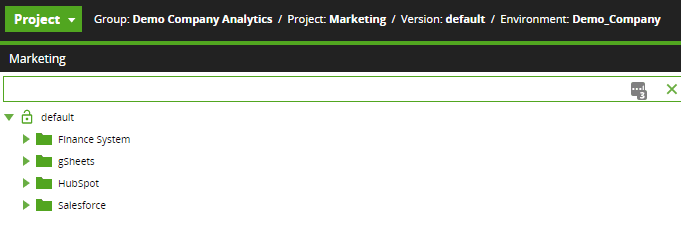
For example, HubSpot and Salesforce Customer Relationship Management (CRM) data is used in their analysis. A financial system provides targets and sales figures on a monthly basis. Finally, several Google Sheets are managed as reference data in their architecture.
A software engineer may approach this as a single effort. Their design may conflate the ingestion of all systems into a single scheduled process. This creates a critical dependency on all steps of the workflow executing without error. Errors always arise. A common example is a column name change on a Google Sheet.
Allowing reference data from a spreadsheet to be included in analytics processes is a powerful way to accelerate input from organization members who have key knowledge but no transactional system to capture that information.
A simple spreadsheet allows non-technical users to contribute to the overall program. However, this flexibility does have a cost. An innocent change on a column name from “Metric_Percent” to “Metric %” may be enough to throw an error in processing.
In the monolithic approach, the entire process fails. Naturally, this could be overcome in a software engineering approach with advanced error handling, but there is a development and maintenance cost with every advanced software pattern feature implemented. The trade-off is rigor versus the speed from inception to insight achieved in low-code patterns.
In contrast, the ZDLC pattern would first have these “Extraction” or “Ingestion” processes separated for each system into their own effort. Keeping them separated for scheduling and execution means that failure in one area does not sink the entire ship.
At the completion of the run, the isolated error can be diagnosed and re-run without having to repeat steps that did complete successfully. In Matillion ETL for Snowflake, this is very easy to accomplish using basic organizational principles.
The Matillion Hierarchy
Work is organized in a clear hierarchy in Matillion. When logging in, the first dialog box displays Project Groups and Projects. These are two simple levels that can map to many organizational structures. Project Groups can align to business units and Projects to process stages.
Likewise, the Project Groups could separate development methods and teams with Projects aligning to process steps or business units. The overarching theme of Matillion is the integration of data and people, allowing many styles of development and technical proficiency to operate within the same visual coding metaphor.
Following along with our example, the marketing analytics team wants to create a Matillion project to ingest HubSpot and Salesforce Data. The Matillion for Snowflake administrator creates a project for the team within the overall company’s analytics Project Group. The admin configures the project to connect to a dedicated marketing database on Snowflake.
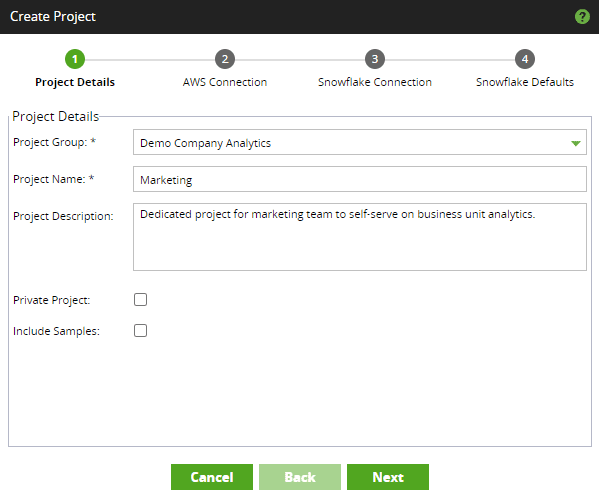
The result is a space dedicated to the marketing team’s analytics efforts which are logically and physically separated from peer departments and IT engineering teams. This isolation enables their modular design to be suited to their data needs as well as their style of development.
Other teams may pursue a code-heavy approach with dynamism and scripting, but the overhead of IT-heavy practices will not block the marketing team. They can simply ingest, process, and derive data products and analysis using a powerful cloud-native infrastructure.
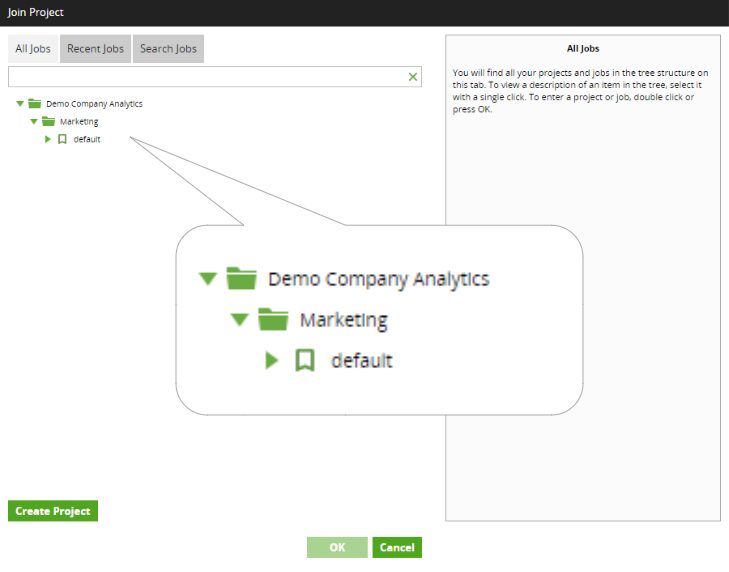
Navigation within their project begins with the decision on how to break down the work among their team members. Remembering that the key to ZDLC is modularity and breaking work and workflows apart among team members so that the overhead of branching and merging code is eliminated.
One scenario could be multiple team members who will each work on ingesting and processing data from one of the source systems. Matillion provides a simple folder system to organize the orchestration and transformation jobs for each effort.
Data Modeling
The process to prepare data for consumption by the data visualization layer follows a highly-repeatable pattern.
- Data is extracted from a Source System and loaded into Snowflake. Many labels are used to describe this: RAW, LOAD, LAND, etc. This step aims to create an identical copy of what appears in the Source System without any transformational changes applied. This is key for quality assurance steps to validate that data is at least making it into Snowflake in an unadulterated fashion.
- The first transformations applied should be corrections to data types and column names. This stage is often referred to as SOURCE because it is a high enough quality that later analytics can be based on these tables. Consistent naming conventions are applied to both tables and columns. A common data type transformation is to convert date fields that were loaded as strings into actual DATE or DATETIME data types.
- The most common final stage is a curation of reports that are designed for the specific business intelligence tool to be used. This is often called CURATED, or REPORT, or even DATA WAREHOUSE.
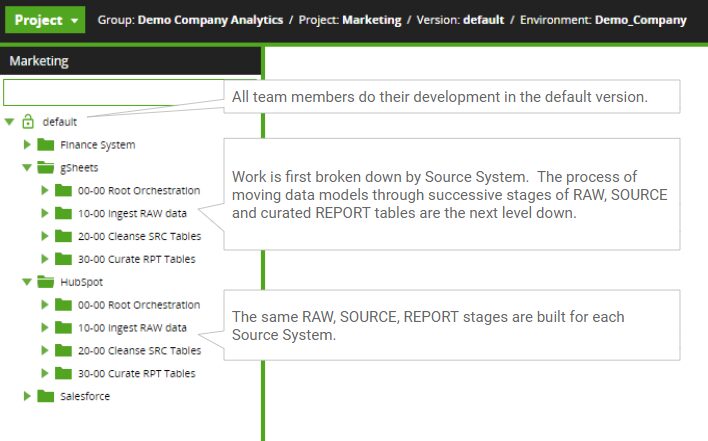
RAW, SOURCE, and REPORT are only an illustration of the wide variety of data modeling activities. As more advanced patterns are applied, additional data staging could allow for Data Vaults, Star Schemas, and other popular designs. In this example, we will only illustrate the most common RAW, SRC, and RPT stages.
Development Life Cycle
The steps taken so far have led to the decision on how to move your workflows from a DEVELOPMENT state to a PRODUCTION state. In Matillion, this can be accomplished in several ways. The most common is to implement separate Matillion instances for DEV and PROD.
This enforces separation from your unstable, in-progress workflows to your stable, functioning workflows. It also enables a distinction between a lighter-weight server used for development and a more robust-sized server for production. There are many other states in SDLC, including Quality Assurance (QA), System Integration Testing (SIT), etc. These are all unnecessary in a modular, code-light ZDLC approach.
In addition to separate servers, another code-light approach would be to use the same server and separate DEV and PROD through versioning and separation of Environments. The example we will follow will assume two separate servers for DEV and PROD. Consider the Environment approach, where production runs are batched and executed outside of development hours.
Versioning In Matillion
An integrated versioning system is built directly into Matillion. This can be accessed from the Project Menu:
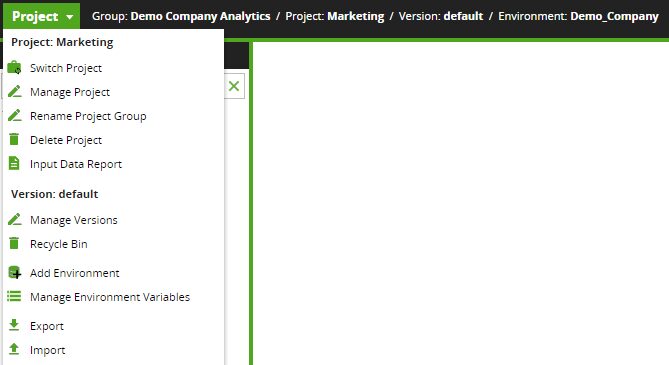
“Default” is an intuitive label for the version that exists by “default.” In ZDLC, teams can perform their development together in the default version. This is an excellent way to teach new members how to perform basic Extract-Load-Transform (ELT) work. Everyone can easily navigate through other folders to observe patterns of loading data, data modeling, and curating data products.
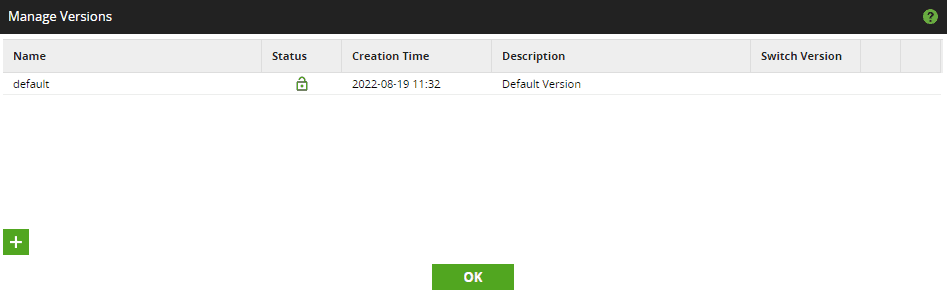
When one of the efforts has reached a stable development stage and is ready for promotion to a Production environment, a new version of the default workflows can be saved. This process includes a few simple steps.
- Conclude development on a stable set of workflows for a given effort. For Illustration, we will say that the workflows for Hubspot analytics are ready to be promoted to production.
- Cut a new version of the default version and label it with a new version (e.g., Hubspot 1_0_0 – as an aside, the triple-digit versioning is a convention to describe major versions, minor versions, and hot fixes, respectively.)
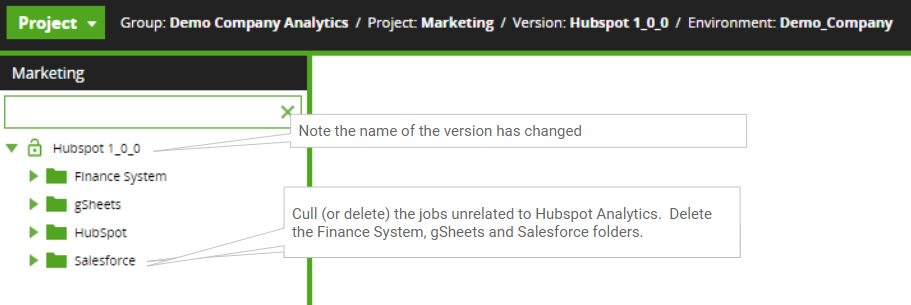
- Open the new version and validate that you are indeed in the correct version. The version label “Hubspot 1_0_0” should be the top-level “folder” in the navigation pane.
- Cut or delete the jobs that are unrelated to Hubspot. The workflows should be developed so that all jobs necessary for “Hubspot” are in the “Hubspot” folder. There should not be any dependencies across top-level folders.
- Export the versioned workflows from the DEV Server
- Import the versioned workflows into the PROD Server.
Let’s follow through with these steps referencing the corresponding screenshots below. Cut the new version:
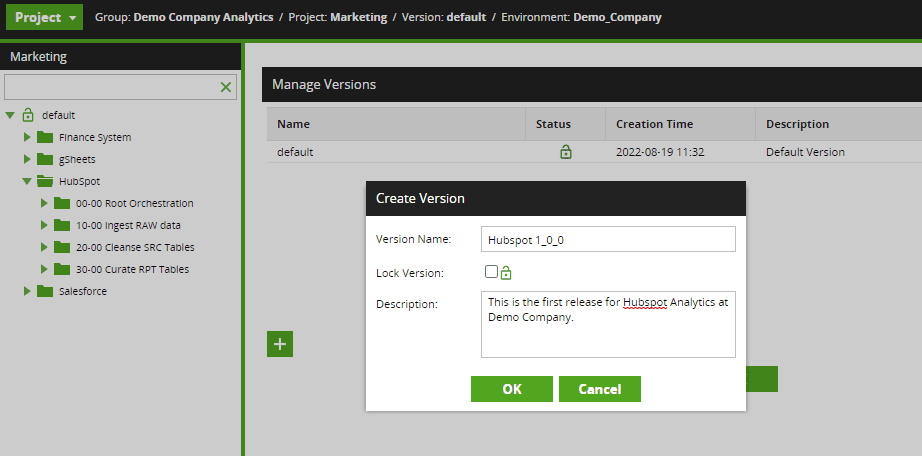
Open the new version, validate the version label, and cull unrelated jobs:
At this point in the process, additional testing can be done by running the versioned workflow. This can be done manually, or it can be scheduled to observe testing for one or more cycles. If scheduled, edit the schedule to use the newly created version.
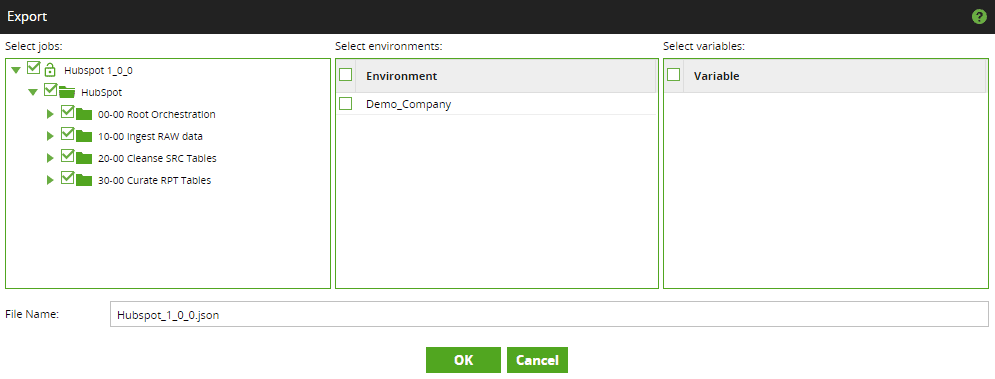
The export feature is available from the Project Menu. Select the jobs to be exported. Typically this will include all jobs once unrelated jobs have been culled. If variables or environments are to be included in the export, those can be selected as well. Provide a name consistent with the version for the JSON file name.
The best practice on the target production server will be to leave the default version empty. Several different efforts will be imported onto the production server as separate versions. To prepare for import, create a new version from default.
The name of this new production version will match the name of the export just created. In this example, the production version’s name will be “Hubspot 1_0_0”. There will be no jobs in this new version. Import the JSON file that was just exported:
The new version can now be scheduled on the production server by simply updating the version name in the existing schedule.
Need help understanding Matillion or which development life cycle is best for your organization?










