

Scala For Big Data Engineering – Why should you care?
The thought of learning Scala fills many with fear, its very name often causes feelings of terror. This suggests it’s either doing something very good, or very bad! The truth is Scala can be used for many things; from a simple web application to complex ML (Machine Learning). Moreover, it unusually fully incorporates two programming paradigms: OOP (Object Orientated Programming) and FP (Functional programming).
In this blog series I will break down some of the barriers and myths hindering mere mortals from learning Scala, and hopefully set some of you on the path to FP enlightenment within your data projects
What is Scala and who uses it?
The name Scala stands for “scalable language.” The language is so named because it was designed to grow with the demands of its users. Scala was born in the early 2000’s, with its growing commercial popularity only beginning to accelerate in more recent years. One of the catalysts for this being Microsoft Azure’s heavy investment in Data Engineering tools such as Databricks & Spark: Spark is actually written in Scala under the hood. So, even if you are writing your notebooks in Python or SQL syntax, Scala fuels the underlying engine driving your needs.
Other popular software/frameworks written Scala include Kafka, akka and play.

So what companies are actually using Scala? Here are some of the biggest names:

Why are these companies using Scala over other languages? A great quote I read, though somewhat dramatic, articulates this nicely: “Scala has taken over the world of ‘Fast’ Data”. This one sentence precisely illustrates one of Scala’s main strengths: Efficiently and quick processing data. If we look at these companies, they all have one thing in common, they are all continually processing huge amounts of data.
An example of how popular Scala based Software can be used within your data architecture is illustrated below. It is using many common Microsoft Azure data tools, including Storage Blobs, PowerBI and SQL databases, with Spark Streaming acting as a middleman between the data sources and destinations. This is just one example of how this technology could be used to enhance your data architecture.
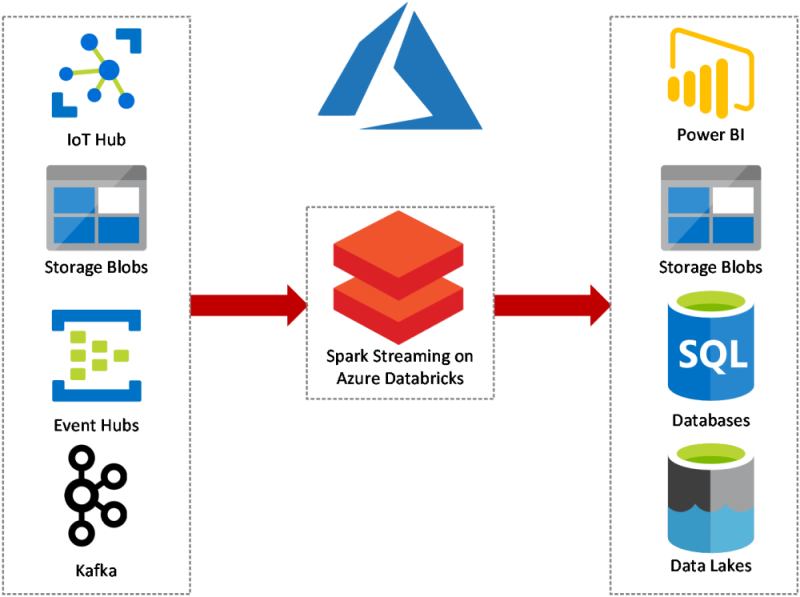
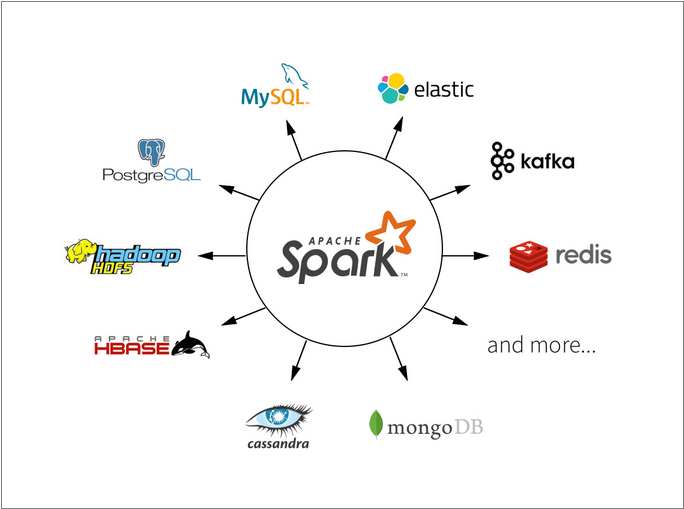
Here we have used Spark as an example data processing tool. Spark is a great tool to learn. In particular as it can connect to a variety of popular data tools
But still, why bother? Although I’m biased as a huge Scala fan, there are many reasons to learn Scala:
Professionals want to learn and use transferable, portable skills in their day job, and Scala is multipurpose, meaning you can use if for anything from a simple web app to ML
Provides the opportunity to learn Functional Programming, allowing for easy transition into other languages such as Haskell, F# and even Erlang (if you’re crazy enough)
It has a solid community behind it
It is Type safe
In reference to my last point above “Type Safety”. There may be some of you wondering what is meant by this. In short, Type Safety means you are not able to set something to a type it is not. For example, you cannot turn an int into a string, or in more layman’s terms, you can not turn a cat into a dog:

Type safety means that the compiler will validate types while compiling and throw an error if you try to assign the wrong type to a variable. If I write a function that expects an int, then try to treat it like a string, it’s going to tell me I’m wrong immediately, rather than discovering my mistake further downstream. As all developers know – the later you catch a bug, the more costly it is to fix!
Scripting languages, such as Python and JavaScript do not throw an error until the code is run, by which point it could be in production and cause you a world of pain (although if you’re not testing your code before release, that’s a whole other problem).
What FP (Functional Programming) and what does it have to do with Scala?
In short FP is a popular programming paradigm. It is not as commercially popular as its brother OOP (Object Orientated Programming) and is perceived as more difficult to learn. This said FP lends itself nicely to data processing & engineering, thus why software, such as Spark and Kafka, are written in Scala.
Scala can be written as both OOP and FP. This is equally both a blessing and a curse. For those coming from the worlds of OOP languages such as C# and java, this functionality enables an easy transition between the two paradigms. However, Scala has been labeled somewhat of a “Kitchen sink language”, meaning every possible feature is added without necessarily questioning why. For a programmer this means many ways to do the same thing, and sadly, equally, many ways to get it wrong!
The below illustrates some of the core FP Concepts, these are the bread and butter of FP languages.

In the next entry in this series I will cover some of the FP Concepts with code examples of how they are effectively used for data processing
Thank you for reading