
It is amusing for a human being to write an article about artificial intelligence in a time when AI systems, powered by machine learning (ML), are generating their own blog posts. DoorDash has been building an internal Machine Learning Workbench over the past year to enhance data operations and assist our data scientists, analysts, and AI/ML engineers. In this article, we'll explain how DoorDash has accelerated ML development velocity through constructing a streamlined environment for automating ML workflows. We also shed light on how we drove value by taking a user-centered approach while building this internal tool.
Importance of ML at DoorDash
ML is involved in a wide range of applications in the tripartite symbiosis of customers, Dashers, and merchants to whom DoorDash caters. From using the right image on merchant store pages to suggesting appropriate substitutes when Dashers are unable to find a suitable replacement for an out-of-stock item, there are opportunities aplenty for which manual solutions are inefficient, expensive, or implausible.
As shown in Figure 1, data science intersects ML in multiple ways and is paramount to DoorDash's success. Therefore, it's critical for the data and engineering teams to have comprehensive support throughout the ML process. An internal ML workbench facilitates collaboration and information sharing between these teams and also speeds up and streamlines execution of ML projects.
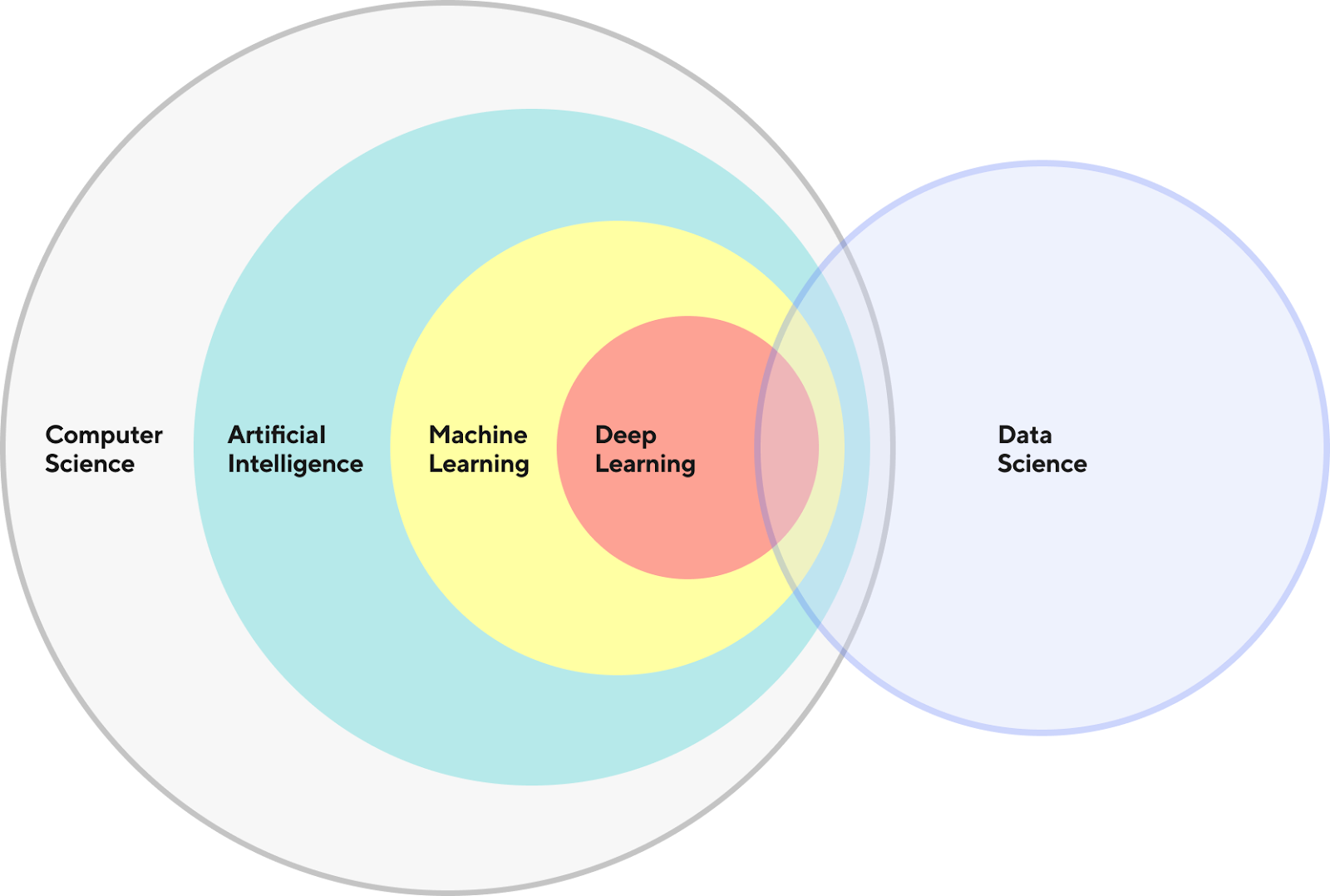
The concept of an ML Workbench
Our vision for ML Workbench was to create a centralized hub to provide a space for accomplishing tasks throughout the machine learning lifecycle, such as building, training, tuning, and deploying machine learning models in a production-ready environment. The idea was to create a one-stop shop for users to collect data from different sources and then clean and organize it for use by machine learning algorithms.

Workbench Evolution
ML Portal motivation and backstory
The ML platform team started by building a simple UI to automate the model testing process through a web application called the ML Portal. Data scientists could use this app — ML Portal — to test their models easily using a browser and a few mouse clicks.
This came from preemptive thinking after we observed that the manual testing process wasn't scalable, slowing ML development and generating repeated questions about putting together the Python script. As we saw users readily adopt this simple automation, we realized that simple tools can help our customers increase model development velocity over the long term.
We soon started adding more functionality to this UI. Some of the initial features included:
- Ability to view all models
- Ability to test model predictions
- View features that constitute a model
We observed ML Portal’s utility as adoption grew and decided to double down on this effort. We continued iterating on our initial prototype, which we created using a Python Flask and HTML framework.
ML practitioners told us that they perform a number of daily tasks that we decided to incorporate into the UI tool to accelerate and streamline their daily workflow. As we reached a critical mass of adoption, users started to put in feature requests for the UI; we knew we needed to improve both our technology stack and our information architecture to make meaningful incremental improvements to their workflows.
At the same time, we were conducting user satisfaction surveys and gathering improvement reviews each quarter that verified how useful the ML Portal was becoming. All of this prompted creation of The ML Workbench: A Homepage for ML Practitioners at DoorDash. Setting an initial ambitious goal to drive model development velocity, we soon assembled a team that included both design and engineering.
Workbench goals
- Internally grow a solution optimized to boost the productivity and velocity of DoorDash teams running ML-powered operations
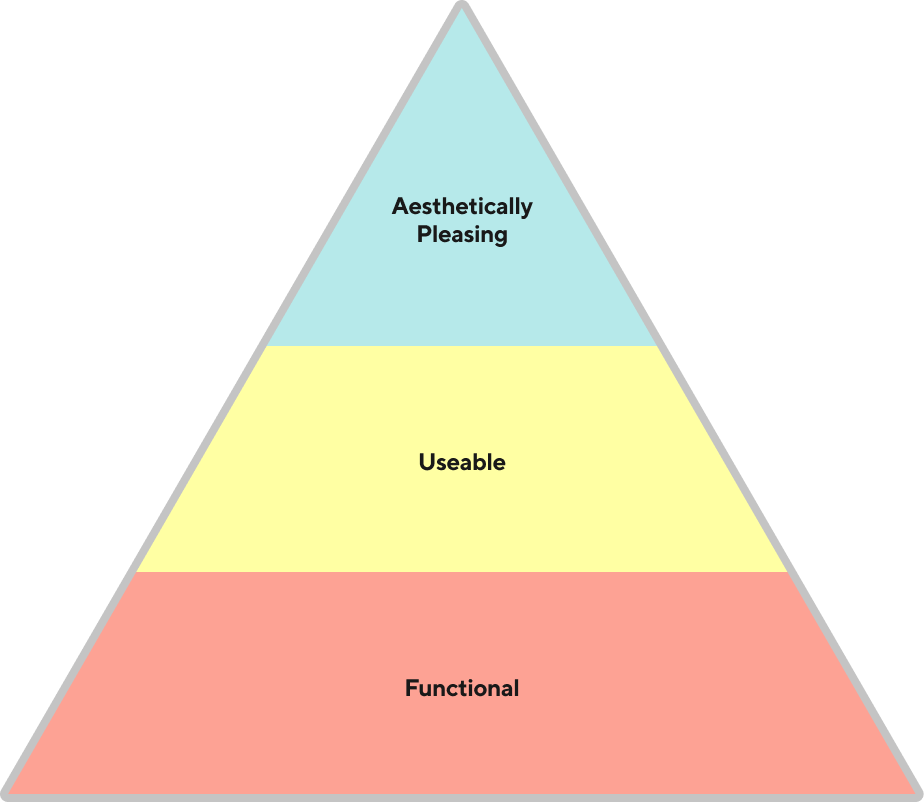
- Build a best-in-class internal tool that’s functional, useable, aesthetically pleasing, and integrates seamlessly into DoorDash's growing internal tools ecosystem
- Reduce reliance on third-party apps
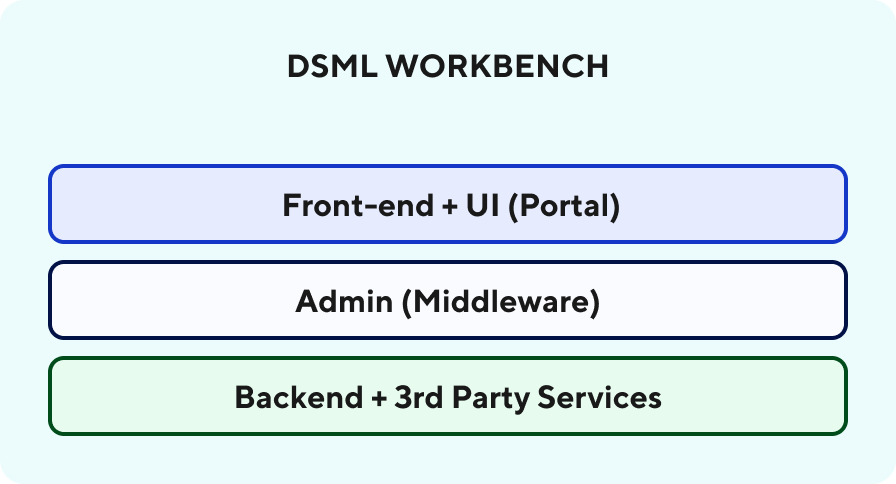
Workbench development strategy
We took our usual crawl-walk-run product development approach, instilling design thinking to prioritize our sequence of operations:
Phase 1 (Q1-FY23)
- Drive research to understand user pain points, current usage
- Establish a product development process with cross-functional partners
- Craft a short-term vision for the ML Workbench (MLW)
Phase 2 (Q2-FY23)
- Design solutions for key experiences and friction areas identified during research
- Run user tests with the first few versions of engineering builds
- Optimize workbench performance, aiming for better velocity and productivity
Phase 3 (Q3-FY23)
- Develop a feedback mechanism through product surveys
- Use feedback to inform long-term vision
- Extend capabilities and capture more of the ML lifecycle through feature adds and enhancements
User research
Despite our ambitious goals, we quickly learned that we couldn’t have the workbench support all four phases (Figure 2) from the get-go. We conducted interviews across multiple teams, including Search, Ads, ETA, and more that focused on each participant’s role, how they were using ML Workbench, their team’s goals, and their current pain points. We organized major user tasks using a jobs-to-be-done framework and categorized users into three buckets:
I. Admins (ML platform engineers)
- Provide maintenance and support across ML platform
- View ML models and associated input variables — features — across predictors and use cases for quick debugging
- Set up connectors that allow users to interact with other services on ML platform
II. End users (Data scientists, data analysts, other data users)
- Develop ML models end-to-end and explore currently available datasets
- Deploy shadow models
- Monitor models in production
- Make test predictions
- Track model data such as features, training runs, shadow models, and metrics
III. Operators (product managers, business leads)
- Review key signals and metrics
- Supervise ML team performance and efficiency
Key findings
Based on our conversations with users and their use of working prototypes in their day-to-day workflows, we surmised:
I. Which pages received the most traffic
- “I use it for looking up information on predictors, features and sometimes for testing and deployment — not for model training yet.”
- “I frequently check Pipeline Runs and Sensor Ticks, but, often verify with Dagit.”
II. The phase of the ML lifecycle during which the workbench was most used
- “We don’t touch ML Portal during feature development work. After the feature has been deployed to production and uploaded to Redis, we start using ML Portal to check the feature.”
III. The key issues in available capabilities
- “I’ve never clicked into the fabricator source on ML Portal. I didn’t know all this source information was inside.”
- “I love feature search. Would be really helpful to have a dropdown box as we’re typing feature search keywords (contextual search).”
As we spoke to users, we realized that this also was an opportunity for us to observe what DoorDash’s ML pipeline looked like. Through capturing the complicated landscape better, we could identify where MLW could be most effective and perhaps slide in as an alternative for a third-party tools.
Setting a vision and scoping out a launch-ready MLW v1
Our research guided us toward what we wanted to solve, transforming into a vision of a full-scale ML Workbench, in the form of a design prototype that would be our north star. From here, we defined the first version and focused on:
- Setting a strong foundation for a scalable workbench by building the front-end from scratch in React, consistent with Prism, our internal components and design system
- Integrating MLW in the existing internal data tools suite that includes tools such as Experimentation Platform and Metrics Platform
- Reducing time on-task for key experiences to speed velocity directly and to boost productivity through making MLW actions and capabilities easily discoverable
- Creating a 45-day concept-to-production timeline to iterate consistently on new and existing workbench capabilities

Subscribe for weekly updates
Use Case
Problem: Feature Upload Status
Model owners often perform daily checks to ensure feature freshness. The old flow involved a few too many steps using a command-line interface, as outlined below, to check if features were being uploaded on time to the chosen feature store.


Problem: Feature values serving lookup:
As fabricator adoption grew, data scientists and ML engineers needed to ensure that the features they created were correct. Even simple tasks such as a spot check for created values required going through a tedious process from their local machines to query the feature stores in production.


Solution
By enabling MLW to integrate with the feature stores, we let users directly query the production data via a simple user interface. This greatly reduced an ML practitioner’s operational overhead to query the feature stores to ensure the features they are generating using. Moreover, for feature upload status spot checks, we made the process much easier and quicker by enabling MLW to interact with the feature upload service and its tables, ensuring direct interaction with the feature service from the UI.

Testimonials
Since deploying ML Workbench, our engineering and data science teams have given great feedback about how it streamlined their processes and created a much better user experience.
“These improvements are huge! New platform is already saving me time because I can send it to my xfn to check features values (for pick score) and they can validate that the features are correct & make sense.”
– ML Engineer, New Verticals
“While technically this functionality may have existed in the old platform, the UI was so difficult to work with (that) I wasn't able to use it as a tool to accelerate my own work or get extra eyes on it to improve the quality of my work.”
– Software Engineer, Consumer Growth
What’s next?
As we continue to scale our efforts with a customer-obsessed approach, we are looking into the following areas of focus:
- Drive and diversify adoption: DoorDash’s ML Practitioners already need and actively use ML Workbench, but now we want to add more personas to its user base
- Improve observability: As we head into 2024, we seek to leverage ML Workbench to improve feature and model observability to increase user confidence in the platform tools
Traditionally, developing internal tools for developers has focused solely on automation, often at the expense of user experience. With ML Workbench, we challenged ourselves to develop user empathy and balance the goals of velocity and productivity with a focus on the user. Rather than limiting ourselves to niche workstreams, we wanted to create a positive impact on as many data users as possible. We took the time to understand the pain points that engineers and data scientists face, prompting us to create both a functional solution and one that our users would find easy and delightful to use. As we scale this tool to capture other phases of the ML lifecycle going forward, we'll continue to prioritize our user-centric philosophy to drive adoption and propel ML development.
Acknowledgements
We would like to express our gratitude to Karan Sonawane and Prajakta Sathe for getting the UI development process going and making the project move from a blank slate to something tangible. We are also thankful to Andrew Hahn and Hien Luu for their guidance and assistance in the collaboration between Design and ML Platform. This was the first project between the two teams and their mentoring enabled us to navigate hurdles in the journey. We also appreciate Hanyu Yang and Steve Guo for making sure the ML Workbench was complete at the time of launch. Lastly, we are thankful to Swaroop Chitlur and Kunal Shah for their input on the implementation approach, engineering structures, and ensuring the ML Platform delivers value where it matters.











