Authored by: Zelal Gungordu and Delaine Wendling.
1 Background
Relevance tuning is the process of making incremental changes to a search algorithm to improve the ranking of search results to better meet the information needs and preferences of users. Ideally, each such change would improve the quality of results, which can be measured using engagement metrics by running online experiments.
Until recently, relevance tuning for event search at Eventbrite was entirely manual. We manually tuned the weights/boosts for different relevance signals used in our search algorithm1. We used offline search evaluation to measure the impact of changes against a test set using well-known search metrics such as precision@k, recall@k, mean reciprocal rank, expected reciprocal rank, and normalized discounted cumulative gain2. Finally, we ran online experiments to measure the impact of changes on engagement metrics such as click-through rate (CTR)3 and order conversion rate (CVR)4.
There are a number of drawbacks to manual relevance tuning as summarized below:
- When we pick the different values to try out for a given weight/boost in an experiment, there’s no mechanism for us to verify that those are the best values to try. Consequently, when an experiment variant wins, there’s no way for us to verify that the value we chose for that variant is in fact the optimal value for that weight/boost. All we know is that the winning value did better than the other one(s) we tried.
- Once we pick a value for a given weight/boost through experimentation, we generally do not go back and try to fine-tune the same weight/boost again at a later time. Consequently, manual tuning doesn’t offer us a mechanism to capture any impact of changes in our index contents and/or user behavior, due to seasonality and/or trends, on the relative importance of relevance signals.
- Our search index includes events from over a dozen different countries. However, a manual tuning-based approach to search relevance is very much one-size-fits-all. For in-person events, we apply a geo-filter to make sure we only return events for the given user’s location. However, when it comes to ranking events, we use the exact same relevance signals with the exact same weight/boost values for any location. Consequently, there is no mechanism to capture the differences in content and/or user behavior between different countries or regions that may have an impact on the relative importance of relevance signals.
Now that we have summarized the manual approach to relevance tuning and its drawbacks, let’s discuss how automating relevance tuning can address these concerns.
1.1 Automating Relevance Tuning
Automating relevance tuning involves applying machine learning techniques to tune the weight/boost values of relevance signals through a technique called Learning to Rank. Learning to Rank (LTR), also known as Machine-Learned Ranking (MLR), is the application of machine learning (ML) in training and using models for ranking optimization in search systems5. Instead of manually tuning weight/boost values for relevance signals, the LTR process trains an ML model that can learn the relative importance of signals from the index contents and training data, which consists of relevance judgments (i.e., search queries mapped to correctly-ranked lists of documents). The resulting model is then used at query time to score search results.
LTR can leverage either explicit relevance judgments (using manually labeled training data) or implicit judgments (derived from user signals such as clicks and orders). Using implicit judgments is a better fit for us for the following reasons:
- Curating explicit judgments at a scale to support effective LTR can be very time-consuming and expensive.
- Our search index is fairly dynamic in that we have new events created on a regular basis while old events get purged as they become obsolete. Typically, the index contents change completely every six months. If we were to use explicit judgments, we would need to gather them on a fairly regular basis to make sure they don’t go stale as the index contents change.
- Using implicit judgments based on user signals allows us to train a model that optimizes relevance to improve user experience rather than someone’s perception of relevance expressed through explicit judgments. Note that user signals may give us clues beyond whether an event is relevant to a search query based on its title and description. We may be able to determine how much other factors like event quality, date, and location weigh in on users’ decisions to engage with an event.
By using implicit judgments based on user signals, we essentially introduce a self-learning feedback loop in our search system where our users’ interactions with search results help the system self-tune its results to improve future user experience.
Now that we have defined what we mean by automating relevance tuning, let’s go back to the drawbacks we listed in the previous section for manual relevance tuning and explain how LTR using implicit judgments help us address those concerns.
- LTR frames relevance tuning as an optimization problem. We essentially optimize relevance against an objective function6 while trying to maximize the value of our chosen relevance metric7. Consequently, the model learns through the training process the optimal weight/boost values for the relevance signals within the problem space we define during training, which consists of the training data derived from implicit judgments, the index contents and the list of features we choose for our model (i.e., relevance signals).
- Using implicit judgments based on user signals help us capture the latest trends in user behavior. We have the ability to automate training new models on a regular basis – on a cadence determined by business needs – to capture the latest trends in user behavior as well as our index contents.
- Instead of a one-size-fits-all approach to relevance tuning, we can train different models for different locations (countries or regions) as long as there’s sufficient user traffic to help derive reliable relevance judgments for those locations. This is possible because LTR using implicit judgments is completely language-agnostic, since the training data is derived from user signals.
1.2 Deriving Relevance Judgments from Implicit Feedback
We have talked about using user signals to derive implicit relevance judgments. Note that using raw user signals to derive relevance judgments is prone to a number of problems.
- Users are more likely to click on higher ranked search results than lower ranked ones because they intuitively trust the search system’s judgment on relevance. This is known as position bias.
- Using a simple metric like CTR results in search results with fewer user interactions leading to less reliable judgment outcomes than those with more interactions.
- If search never surfaces certain events in the first place, users will not get a chance to interact with them. So, those events will never get a chance to accrue user signal data.
For these reasons, rather than using raw signals, it is common to use click models to derive relevance judgments from user signals. Click models are probabilistic models of user behavior that aim to predict future user behavioral patterns by analyzing historical signal data8. They provide a reliable way to translate implicit signals into unbiased relevance judgment labels.
2 Our Approach to Automating Relevance Tuning
In this section, we summarize our approach to automating relevance tuning for event search.
We use the OpenSearch LTR plugin for automating relevance tuning. This is an open-source plugin available for all OpenSearch distributions. It’s also one of the plugins supported by Amazon OpenSearch Service. With this plugin, judgment list generation, training data preparation, and model training take place outside of Amazon OpenSearch Service. Once a model is trained, it is deployed to OpenSearch and stored in the same OpenSearch cluster as the search index. Using the model at query time involves performing a request with a special query type supported by the LTR plugin called sltr query – which takes the query keywords and the name of the model to use to score results. This is done within the context of an OpenSearch rescore query. In this case, the query part of the request is used to retrieve and rank results using the BM25 scoring function in the usual way9. Then, the top k results following BM25 ranking are rescored/reranked using the LTR model specified in the sltr query. The LTR model is used only in the rescoring phase because it’s a more expensive scoring technique than BM25 scoring.
2.1 Using the OpenSearch LTR Plugin
As mentioned earlier in this section, with the LTR plugin, judgment list generation, training data preparation, and model training takes place outside of Amazon OpenSearch Service. This section explains training data preparation and model training. The best resource to understand how to work with the LTR plugin is the documentation for the Elasticsearch LTR plugin. The OpenSearch LTR plugin is just a fork of the Elasticsearch plugin. In this section, we will summarize some of the information from that documentation. The reader is advised to read the documentation itself if interested in finding out more about the plugin. Another good resource for this plugin is the hello-ltr Python repo that illustrates how to use the Elasticsearch LTR plugin.
Training Data Preparation
This section of the plugin documentation explains the key concepts used by the LTR plugin. There are two types of input that are required for LTR training data preparation:
- Judgment lists: Judgment lists are collections of grades for individual search results for a given set of search queries. The following is a sample pseudo-judgments list for event search:
# qid:1: jazz
# qid:2: valentines
#
# grade (0-4) queryId # docId title
4 qid:1 # 7555 Jazz Concert
2 qid:1 # 6238 Hip Hop Concert
4 qid:2 # 8125 Valentine's DayThis sample file follows the LibSVM format commonly used by LTR systems. Note that the exact format we use is flexible (as long as the code we use to parse the judgments list file is in line with the format requirements). The information required for each judgment tuple consists of the search query in question, the document ID in question and how relevant that document is to that query, i.e., grade. In this sample, we are told that the event with the ID 7555 is very relevant to the search query jazz. The event title is included in the judgment only for human-readability purposes.
- Features: Features are essentially the relevance signals we use in our search algorithm; e.g., title match, description match, event quality boost, etc. The LTR plugin expects features to be expressed as OpenSearch queries. For example, to use title match as a relevance signal we include a feature like the following:
{
"query": {
"match": {
"title": "{{keywords}}"
}
}
}Once we have defined our judgments list and features, the next step is logging features, which essentially means computing scores for each relevance feature based on the index contents. The resulting scores are used to annotate the judgments list to indicate the score for each feature in each judgment tuple. The resulting file would look something like the following snippet, assuming we have two relevance features: title_match and description_match.
4 qid:1 title_match:12.3184 description_match:9.8376 # 7555 jazz
2 qid:1 title_match:0 description_match:2.3624 # 6238 jazz
4 qid:2 title_match:9.6778 description_match:5.7859 # 8125 valentinesThis is the training data that is used to train an LTR model.
Training an LTR Model
The OpenSearch LTR plugin supports two libraries for training LTR models:
- RankLib: RankLib is a Java library that includes implementations of eight different LTR algorithms. It is relatively old and does not enjoy the same widespread use as the second option.
- XGBoost: XGBoost is an optimized distributed gradient boosting library that is very popular. It’s designed to be highly efficient, flexible and portable. It supports multiple languages, including a Python package.
We use XGBoost for LTR training. Note that XGBoost offers a variety of hyperparameters that can be tuned to improve model performance in a given problem space. A good rule of thumb is to start with the default values and apply some mechanism like grid search combined with cross validation to tune a subset of hyperparameters. Here’s a sample blog post that illustrates the process of hyperparameter tuning with XGBoost. The XGBoost hyperparameters for LTR are documented here.
Uploading an LTR Model to OpenSearch and Using it at Search Time
Once we train an LTR model, we upload it to our OpenSearch cluster. Note that one can upload and store multiple models on the cluster. The LTR plugin’s sltr query that’s used at search time takes a particular model as an argument. Hence, it’s possible to create and store different models for, say, different geographical regions, and then use the model corresponding to the given user’s location at search time.
2.2 LTR Architecture
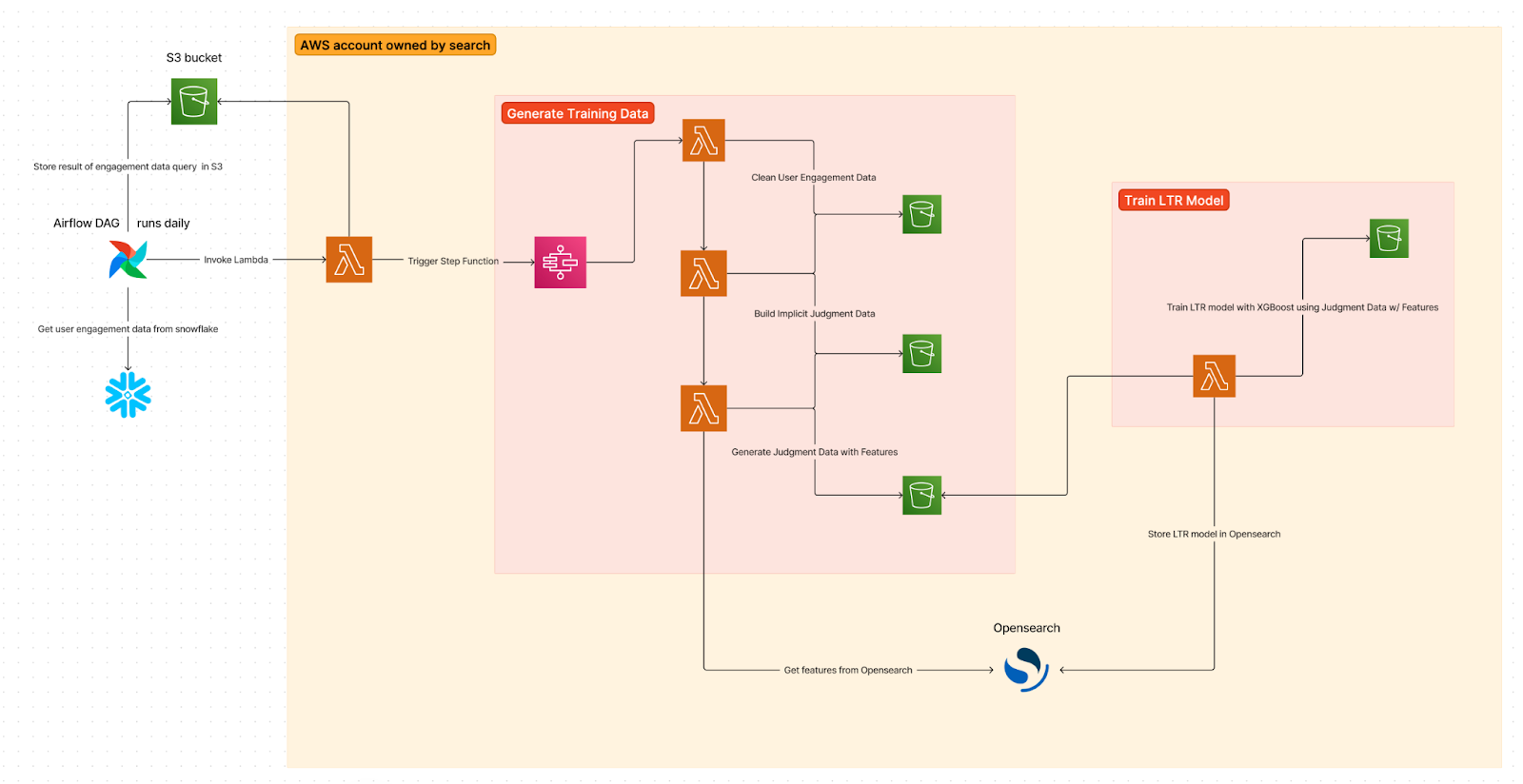
We use an Airflow Directed Acyclic Graph (DAG) to pull user signal data from a Snowflake table and transform it into a format from which we can generate implicit judgments. The DAG runs daily and invokes a Lambda function that triggers a Step Function. This Step Function orchestrates the invocation of three Lambdas that clean and reformat the user signal data, generate implicit judgments and call OpenSearch to compute the feature scores for each event mentioned in the implicit judgements. This process runs automatically every day.
We have a separate Lambda function that trains the LTR model and stores it in OpenSearch, as well as S3 for backup purposes. This Lambda function utilizes training data (implicit judgments with features) from a range of dates determined by the parameters passed to the Lambda to train the model. Once the model is uploaded to OpenSearch, it can be used at search time. Note that prior to rolling out a new model on our production systems, we perform offline evaluation against a test set using the well-known search metrics mentioned in Section 1. This helps us tune the rescore query window size used to decide how many of the top k search results we should rescore using the LTR model. It also helps us tune the rescore query weight used to weigh the relevance scores returned by the model while computing the overall relevance scores for search results. Finally, we run an online experiment where we start using the new model as part of search in one of the experiment variants and track our usual engagement metrics to measure the impact on user experience.
3 Future Work
We are still at the start of our journey for automating relevance tuning. We have many areas where we plan to iterate to improve our current approach.
One of the initial areas where we plan to invest in is improving our feature set. Currently, we use a limited number of features that consist of lexical features. We plan to expand this set to include embedding-based features to capture the semantic understanding of search queries.
So far, we have assumed that the LTR model would be used for requests with an actual search query. However, there’s a considerable amount of traffic on our site where the request lacks a search query. We call these requests queryless searches. For example, most of the traffic coming from the home page and other browse surfaces falls in this category. We plan to train separate models for queryless traffic since, without a search query, other relevance signals like date and event quality would have a bigger impact in ranking outcomes.
Another area of future work is to figure out when it would make sense to train location-specific models. Would it only make sense to have such models for different countries/regions, or is there enough variation in user behavior and/or index contents across multiple large metropolitan areas even within the same country to warrant them having their own models?
Note that so far we have focused on training generalized models of relevance. However, personalizing search results to better meet users’ specific information needs and preferences has proven to improve user engagement and satisfaction. Search personalization is an area we plan to focus on in the near future. Last but not least, traditional LTR approaches like the one we’ve described in this post are supervised ML approaches. They require handcrafted features based on query, document, and how well the two match each other. Over time, heavily engineered features can result in diminishing returns. Another future area of work is to augment the current approach with a neural LTR model. The advantage of neural LTR systems is that, instead of relying on handcrafted features, they allow feature representations to be learned directly from the data. This slide deck provides an overview of neural LTR. Tensorflow Ranking is a library that provides support for neural LTR techniques built on the Tensorflow platform. Generally speaking, neural LTR is recommended to be employed alongside traditional LTR systems in an ensemble setting (as opposed to replacing them) because the strengths of the two approaches are believed to complement each other.
- We use around two dozen relevance signals in our search algorithm, ranging from field boosts to ranking functions based on event quality, sales status, location and date.
- This blog post does a very nice job of explaining these metrics with easy-to-follow examples.
- Click-through rate (CTR) is the ratio of the number of clicks to the number of impressions.
- Order conversion rate (CVR) is the ratio of the number of orders to the number of clicks.
- There is a vast amount of literature on LTR. For a quick overview, see this Wikipedia page and this blog post.
- For more on objective functions used in LTR, see this blog post.
- For more on metrics typically used in LTR, see this Wikipedia page.
- For a thorough overview of click models, see Click Models for Web Search by Chuklin, Markov, and de Rijke.
- BM25 is OpenSearch’s default similarity function used to calculate relevance scores.