or why you should have a look at Data Observability !
This article is the second part on how Airbnb is managing data quality : “Part 2 — A New Gold Standard”. The first part can be found here and it was just good principles about roles and responsabilities.
The second part is really how they do it and all the steps to have a “certification”. They name it Midas, the famous king who can turn everything into gold (with a not so good ending). Welcome to this strange way of managing data quality !

- Strange data quality dimensions
The list given in the article were :
- Accuracy: Is the data correct?
- Consistency: Is everybody looking at the same data?
- Usability: Is data easy to access?
- Timeliness: Is data refreshed on time, and on the right cadence?
- Cost Efficiency: Are we spending on data efficiently?
- Availability: Do we have all the data we need?
It looks like a game where you have to find the errors…
- “Correct ?”… Could be very different from one person to another !
- “Consistency” has nothing to do that about everybody looking at the same data, it is more about the consistency of your data compare to the past.
- “Usability” is interesting but it won’t help about data quality.
- Timeliness : the only correct one 🙂
- “Cost efficiency” could be years of discussions with your finance departement about the Data ROI.
- “Availability” : it is not all the data we need, it is just if the data is… available.
2. Strange certification : turning all your data into gold
If a data has all these data quality dimensions checked and OK, you will have this approval.

Humm it could be difficult to reach and maintain this level (with the data quality dimensions defined earlier)… and your final user could look like this trying to find gold for years.

Normally, you should clasiffy your data with a gold, silver and bronze tag based on the importance or crititicy of the data. And then focus first your attention on “gold” data to reach the right data quality level. Solving a data quality problem is not just about the data itself, it could be due to processes or what is happening in the source. Focusing your effort on what it is important will leverage your “data quality management service” team.
3. Data quality Validation, review, lots of manual tasks… or the Everest north face of Data Quality

If you take each step, it looks logic and solid. Of course you must document everything and have many validations. But why to have it apart from your data development process. The data quality validation should not be done on top of everything, it is totally integrated in your data pipepline process. The other point is about scaling. You will need an army to be sure that the process is applied because everything is manual.
The “other” approach developed by concept like #DataOps or #DataObservability is about these 3 fucntions.
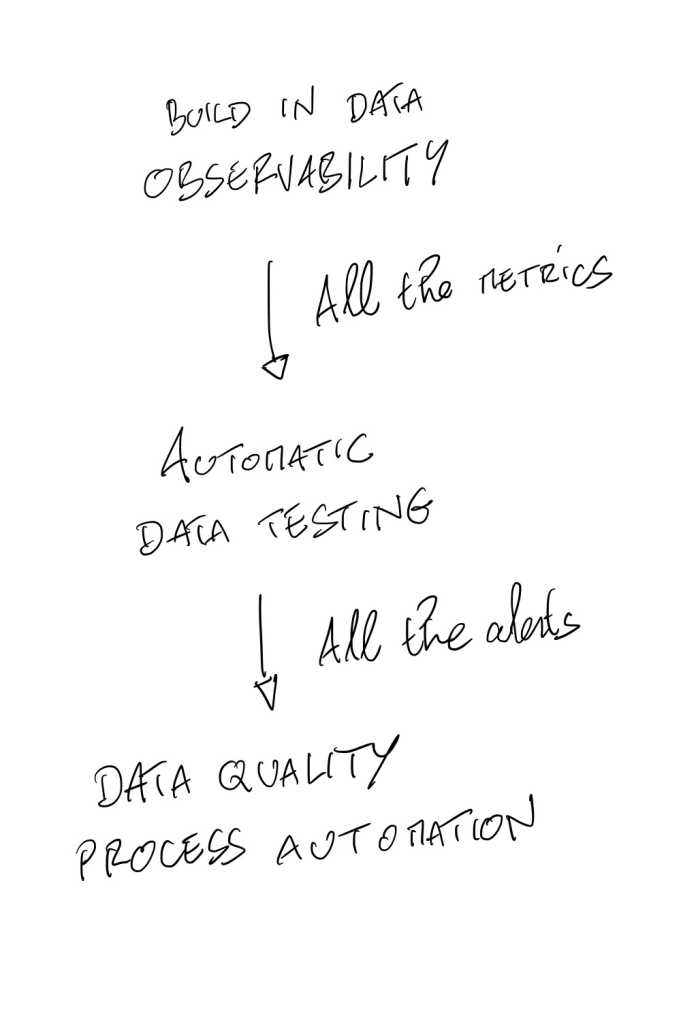
Data Observability must be “build-in” in your data platform : any data you have will be observed. Every data pipeline has automatic data testing by default. All the alerts has a clear process with automation too (self recovery actions).
Conclusion
The articles ends with “ requires substantial staffing from data and analytics engineering experts (we’re hiring!)” and “quality takes time“…
It does take time but how do you use this this time in is the most important question and hiring is one thing, keeping them is another topic espescially when you spend time on borring tasks.
In Google now, you have a list of questions when you are looking about a subject. I just pick this one.

