

Azure Synapse Analytics - Microsoft's Flagship Lakehouse Now in Preview
Today’s the day! There’s much buzz & excitement as we FINALLY get to see Azure Synapse Analytics in public preview, ready for us all to get our hands on it. There’s a raft of other announcements that come hand & hand with it too.
What’s that? You thought Azure Synapse Analytics was already available? You’ve been using all year and don’t see what the fuss is about??
I’m expecting this to be the common reaction. The marketing story for Synapse has been… interesting… to say the least. I’ve been asked several times in the last week exactly what the new story is and, given today’s news, I thought I’d clarify.
Azure SQL Data Warehouse
Our good friend Azure SQLDW has been around for several years. It was the evolved, cloud form of the Parallel Data Warehouse appliance and brought massively parallel processing (MPP) to the cloud in spectacular form.
Back in November, it was rebranded as Azure Synapse Analytics, effective immediately. We saw a shift in all documentation, architecture diagrams and portal references to this new entity “Synapse Analytics”, which was essentially the exact same SQL Data Warehouse we know and love.
The Bigger Picture
The grand vision for Azure Synapse Analytics is a fair bit bigger than the rebranding would suggest. The application that was Azure SQL Data Warehouse is a huge part of it, but much like the traditional SQL engine is just a part of SQL 2019’s Big Data Clusters, SQLDW is just a part of the overall Synapse vision.
The aim is to provide a single pane-of-glass for analytics in Azure, one that combines the huge power of the massively parallel SQL engine, with that of a managed spark cluster. A tool that has built-in orchestration in the form of Data Factory, and direct links into the data science services of Azure Machine Learning Services. To top it all off, there’s a SQL On-Demand service in case you want to run queries without spinning up your Warehouse, much like Azure Data Lake Analytics of old.
That central hub of analytics ties in strongly with the branding – Synapse sitting in the middle of a whole host of services, sucking in the data ready for analysis.

So with today’s public preview announcement, that’s what we’re seeing become available for trialling out – the Synapse ecosystem, which is a whole lot more than just Azure SQL Data Warehouse (which yes, is already GA).
The official view of what Synapse is, an image you’ve probably seen a thousand times by now is:
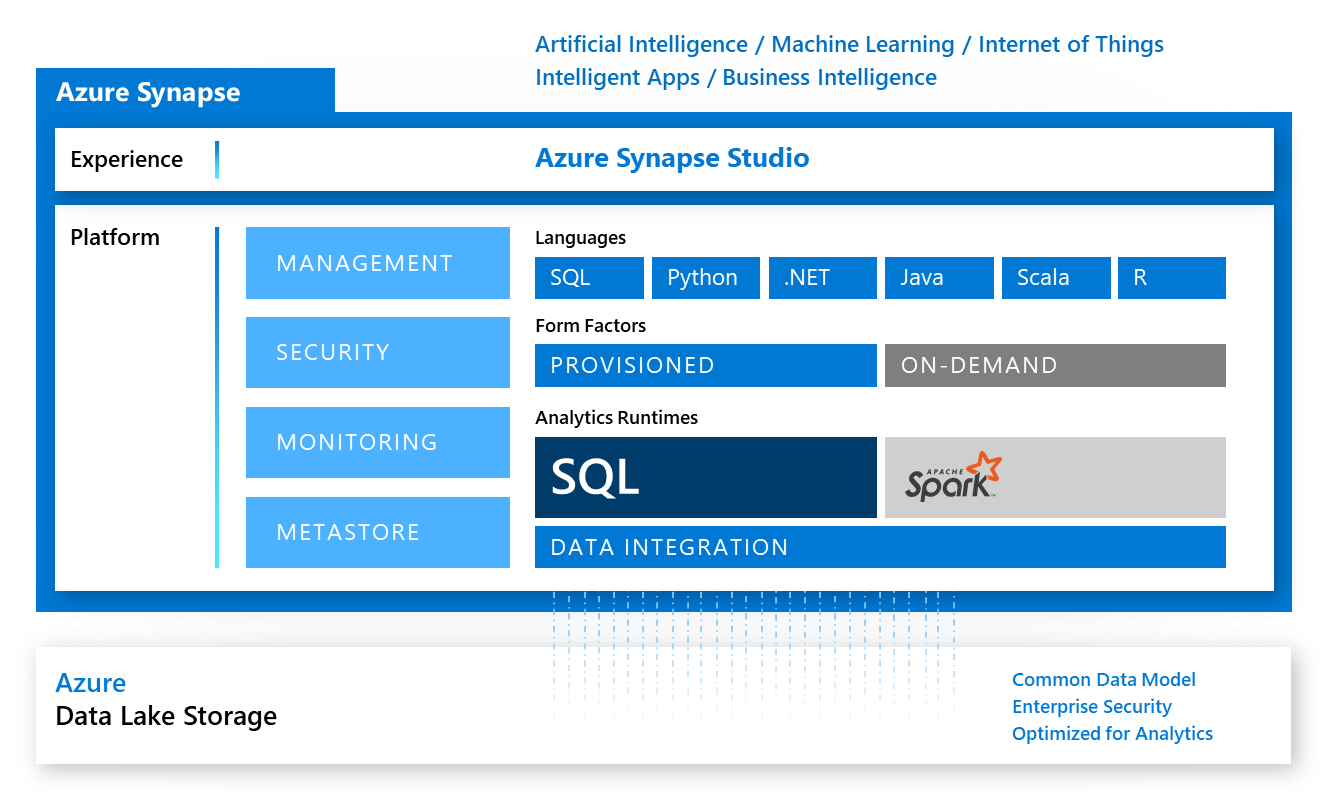
However, this still isn’t too clear, certainly not to swim through the number of different features and the different release paths. My quick visual of the current state looks like this:
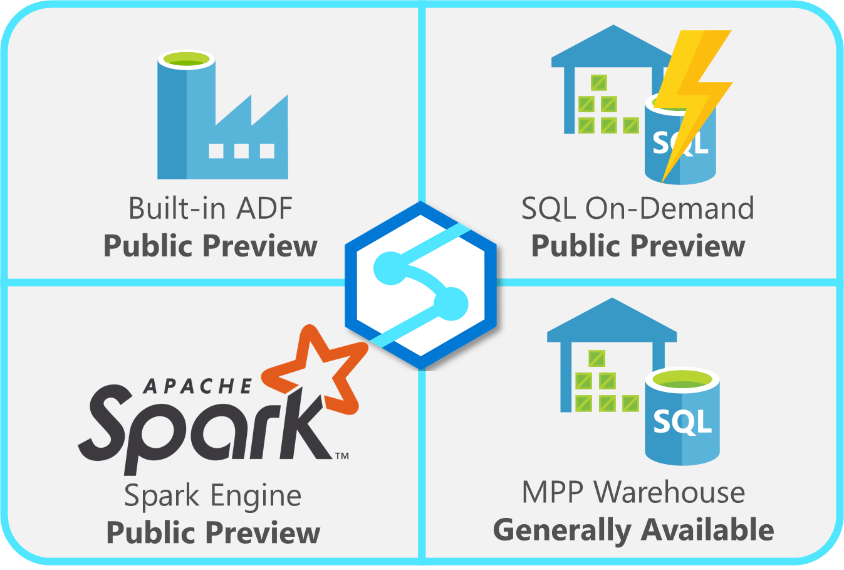
For a Microsoft view of things, James Serra posted his viewpoint a couple of days ago, over on his blog, albeit, before todays Public Preview announcements.
Azure Synapse Link
To be honest, having announced Synapse last November, it’s of no great surprise that we’re now seeing the public preview announcement in time for Microsoft Build. What is a much bigger surprise, is that it was coupled with the public announcement of another preview Synapse Integration – Azure Synapse Link!
This is a killer feature, aimed at carving away a significant chunk of ETL processes. The premise is that a huge amount of reporting is operational and would be done directly on our source systems if they were:
Not constrained by compute and would be unaffected by huge analytics queries
Designed to perform well when queried
The initial target is CosmosDB as our operational store, although there are plans to cover all manner of available operational systems. As applications make rapid changes to the data within the store, there is an asynchronous transfer of data into an analytical store, ready to do the heavy analytical lifting. In this case, it’s managed column store and works effectively as a contained, managed data lake that can be queried by distributed query engines – enter Synapse Analytics.
From Synapse we can write spark or SQL queries directly on top of the analytical store, without worrying about building large, complicated ETL pipelines.

Microsoft are terming this “HTAP” – Hybrid Transactional/Analytical Processing (the best of both OLTP and OLAP worlds).
I’d argue that there is still a real need for integration workflows and analytical data models to take care of the more complex stuff, and to abstract our less data-savvy users away from transactional data models. But thinking back on the number of times I’ve argued over including operational data into a warehouse and suffered through the elaborate solutions required to deliver the necessary latency, if Synapse Link provides the magic wand to keep Warehousing for real analytical data, but provide operational reporting under the same platform – surely that’s a win?
What do you think?
We’ll be delving into the depths of the now-public Synapse preview over the next few weeks and sharing our thoughts, especially compared to the Azure Databricks service that we work with so closely, but we’d love to hear what you think. What do you want out of the tool? Are there use cases you’d love to implement but don’t know if it fits? What are your concerns?