What is Apache Arrow? Asking for a friend.
We’ve all been in that spot, especially in tech. You wanted to fit in, be cool, and look smart, so you didn’t ask any questions. And now it’s too late. You’re stuck. Now you simply can’t ask … you’re too afraid. I get it. Apache Arrow is probably one of those things. It keeps popping up here and there and everywhere.
The only reason I know anything about Arrow is that some years ago, circa 2019 and earlier I stumbled into Arrow and used it to read and write Parquet files (pyarrow that is). Heck, I even used it to tie together Python and Hadoop, Lord knows what I was thinking back then. I’m amazed at how much I used PyArrow back in the day, even to compare Parquet vs Avro.
“Back then it seems like no one used Arrow much, no one was writing about it, using it, or talking about it. At least not that I saw. But oh how times have changed. Arrow seems to be showing up everywhere and is starting to become a backbone for many other tools.”
– me
Apache Arrow creeping into Data Engineering.
Although not super mainstream right now, and probably unknown to a lot of Data Engineers, it does seem like Arrow is starting to sneakily creep in the back door. I see posts here and there popping up in my feeds. I mean it’s almost getting hard to ignore now, especially when all the cool people are talking about it.
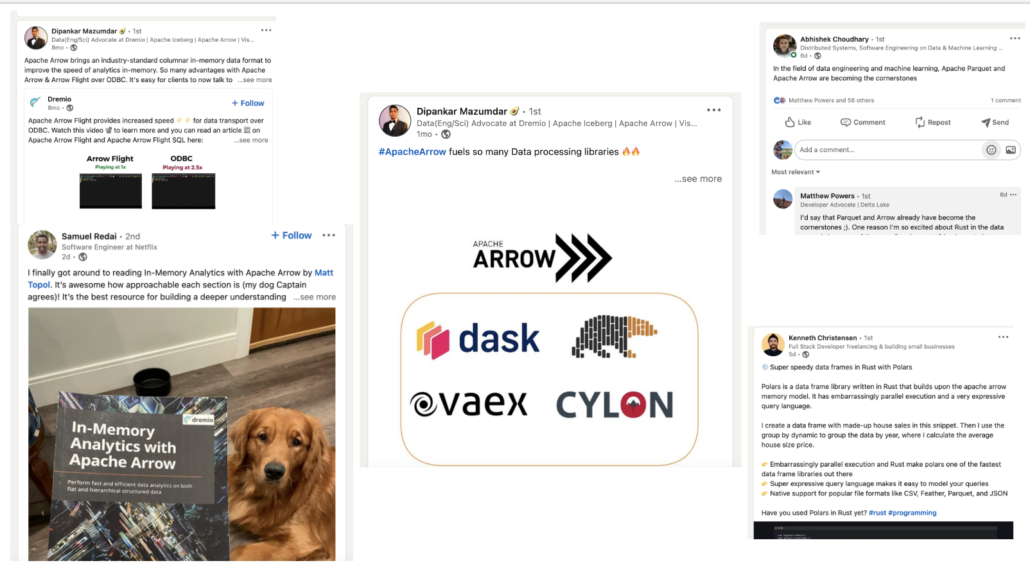
So what is Apache Arrow? Let’s find out.
“A cross-language development platform for in-memory analytics”
– Apache Arrow website.
I think what makes Apache Arrow popular, powerful, and used to build other tools on top of that it’s a format, “Apache Arrow defines a language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs.” So basically all that huff-a-luff for nothing, it’s “just an in-memory data storage format.” So what?
Well, that is the key I would say, also along with the fact that there are libraries for about every language you could want. C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby, and Rust. Quite amazing. So why. have you never heard of it? Probably because it’s a tool made by developers for other developers to use in their projects.
I mean, the likely hood of a Data Engineer using pyarrow to do work in an everyday data pipeline is probably small. I’m sure it’s being done here and there, but probably not a lot. Most folks are simply going to reach for Polars, Pandas, Spark, and the like. It’s just that under the hood you may very well be using Arrow without knowing it.
Main Points of Apache Arrow.
Ok, so we know Apache Arrow is an in-memory data format for “analytics,” which probably just means working on the data and transforming it. It’s probably best to understand Arrow by using it, but I’m going to list a few bullet points, or concepts, that can be found in the documentation.
- “building high-performance applications that process and transport large data sets …”
- “efficiency of moving data from one system or programming language to another.”
- “in-memory columnar format“
- “language-agnostic specification for representing structured, table-like datasets in-memory”
I mean, it must be good if you have a bunch of other platforms building on top of Arrow. It does make me curious, if you have pyarrow, what do Pandas, Polars, etc have over Arrow? Why not just Arrow? Let’s find out.
Trying out Apache Arrow via PyArrow and Rust.
Let’s start out with Arrow by installing pyarrow and trying to run a pipeline that will read a large number of CSV files and convert them to Parquet. We are going to use the Backblaze Hard Drive failures dataset, Q1 data, about 6-7 GBs of data, enough to test Arrow out. So we read a bunch of CSV’s, 6GB’s worth, and do a simple groupBy and agg, and spit the results out to Parquet files that are partitioned. All code available on GitHub.
from pyarrow import dataset, Table, parquet
from datetime import datetime
def read_csvs(file_locations: str) -> Table:
ds = dataset.dataset(file_locations, format="csv")
return ds.to_table()
def calculate_metrics(tb: Table) -> Table:
metrics = tb.group_by("date").aggregate([("failure", "sum")])
return metrics
def write_parquet_metrics(tb: Table) -> None:
parquet.write_to_dataset(tb,
'data/data_out',
partition_cols=['date'],
existing_data_behavior='delete_matching'
)
if __name__ == '__main__':
# Using open source data set https://www.backblaze.com/b2/hard-drive-test-data.html
t1 = datetime.now()
hard_drive_data = read_csvs('data/data_Q1_2022/')
metrics = calculate_metrics(hard_drive_data)
write_parquet_metrics(metrics)
t2 = datetime.now()
print("it took {x}".format(x=t2-t1))
It took it took 0:00:30.635797 to run this code, and it worked, so there’s that.
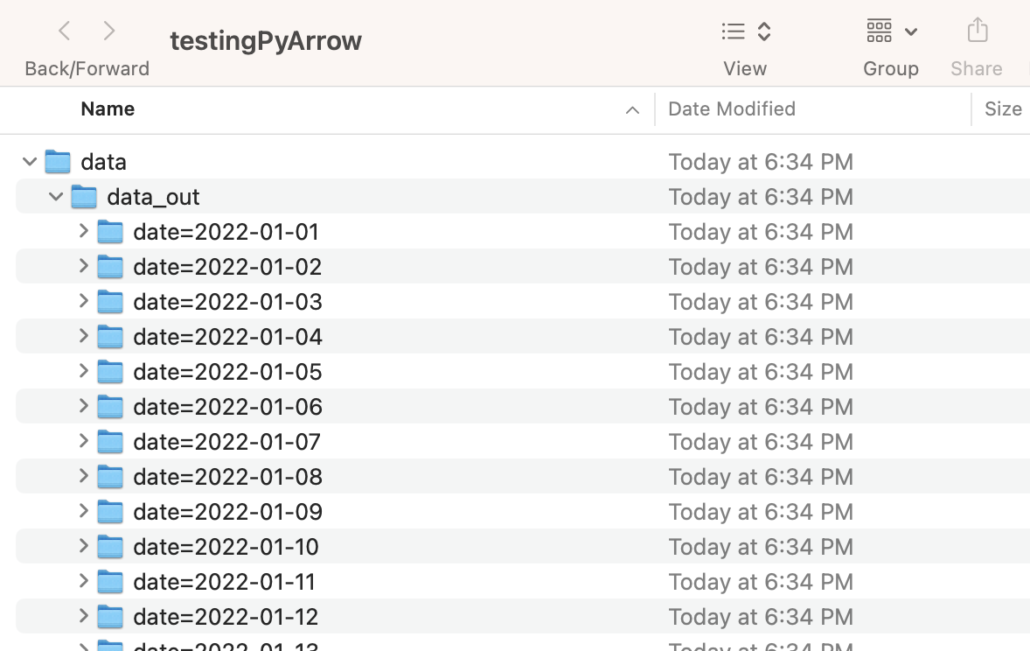
It does make me wonder how PyArrow out of the box would compare to something like Polars, DuckDB, and the like. You know I like making people mad. Oh wait, didn’t I make a New Years’ resolution about not doing that anymore? Oh well. Unfortunately, it looks like Polars doesn’t support writing partitioned parquet data sets unless you send the Polars Dataframe over to the PyArrow function. We have to do it anyway, just to see how well Polars implemented its aggregation and computation functions.
import polars as pl
from pyarrow import parquet
from datetime import datetime
d1 = datetime.now()
q = (
pl.scan_csv("data/data_Q1_2022/*.csv", parse_dates=True, dtypes={
'date': pl.Date,
'serial_number' : pl.Utf8,
'model' : pl.Utf8,
'capacity_bytes' : pl.Utf8,
'failure' : pl.Int32
})
)
df = q.lazy().groupby(pl.col("date")).agg(pl.col('failure').sum()).collect()
parquet.write_to_dataset(df.to_arrow(),
'data/data_out',
partition_cols=['date'],
existing_data_behavior='delete_matching'
)
d2 = datetime.now()
print(d2-d1)Well, look at that Sunny Jim, that’s fast 0:00:09.578644. Fast, fast, fast in typical Polars.
Closing thoughts on Apache Arrow.
There you have it, now you know what Apache Arrow is. If you have more time and want some interesting reading, go over to the Use Cases and do some more reading. Apache Arrow truly is trying to be the Atlas, holding the Big Data world on its back. What it really comes down to is that Apache Arrow provides the following features for other Big Data systems to build on top of.
- Reading/writing columnar storage formats
- Sharing memory locally
- Moving data over the network
- In-memory data structure for analytics
It will be interesting to watch in the future what other data processing tools are built ontop of Apache Arrow!