Polars vs Spark. Real Talk.

Real talk. Polars is all the rage. People love Spark. People use Spark for small data, but data is too big for Pandas. Spark runs on a local machine. Polars runs on a local machine. What do I choose, Spark or Polars? Does it matter?
I’ve written about Polars at different points, here, and here when discussing wider topics. I mean honestly, I think Polars is the best tool to come out in the last 5 years of Data Engineering. But I find it unwaveringly boring. Which is why it’s so popular.
It’s boring for anyone who has used Pandas, Spark, or other Dataframe tools a lot. Sure, it can be a cool breeze in the face of some poor sap who’s been chained down to Pandas by some boss hanging around from a bygone era. You know what I’m talking about.
But honestly, overall, if you’re just an average engineering piddling around with datasets on your machine, what should you choose? Spark or Polars. Let’s talk some real talk.
How do you compare Polars and Spark?
I think for some reason there is some context missing a lot of Data Engineers talk about Polars vs Spark and if you should replace Spark with Polars, that’s usually the question. That’s like asking if you can replace Snowflake with Databricks, or vice versa. It’s the context, my friend. Also, although Polars and Spark may look like the same thing on the surface, most assuredly they are not.
Maybe if I draw you a picture.
Simple enough for you? Look ma, how smart I am.
The real question you should be asking.
So when you are asking Google, hey, Spark vs Polars. You’re not asking the right question. That question needs context in the best case and a better understanding of what each tool is good at answering.
Let me put it another way, to make it even more clear.
- If you can replace Spark with Polars, you shouldn’t have been using Spark.
- If you can replace working Polars pipelines with Spark, then you’re wasting time.
Polars and Spark are complementary to each other and each should be used in the correct context.
And if we are going to be good little Data Engineers worthy of the crumbs we eat that fall from the tables of our overlords, then we should be able to discern a few things about Polars and Spark, and when to use each tool in the correct context.
When to use Spark, and when to use Polars.
Spark is a distributed processing framework built to run on large clusters of machines, processing Big Data. Polars is a tool that right now, is made for single node/machine processing. These are not the same things. Do people mix and match them and confuse the topic? Why yes, they do.
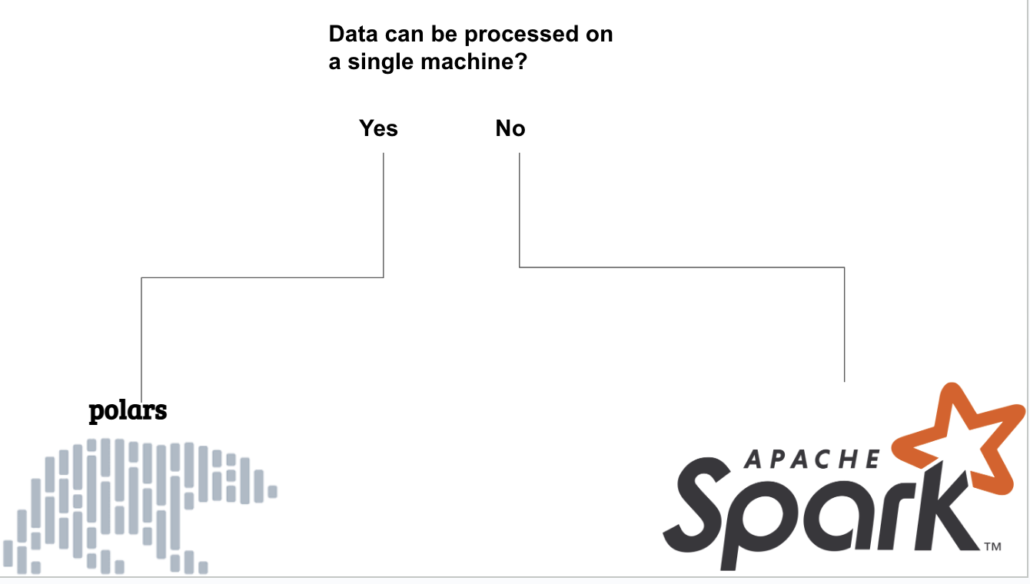
Sure, I know it isn’t always that simple, but wait, maybe it is. Is it? Think about it. If you’re running Spark on a single machine/node to process data because Pandas choked on your data size, that’s all find and dandy, but that’s like using a sledgehammer when you needed a hammer. I mean CAN you do it? Yes. Lots of people do it. I do it.
Spark is complex and has a lot of overhead. If you are processing data on a single machine, use Polars, that’s what it was made for. You can pip install the darn thing for crying out loud. You can’t pip install Apache Spark, my fair-weathered friend.
Let’s also be honest about a few things.
- Spark has been around for a long time.
- Polars has not been around for a long time.
- Spark’s features and functions probably outstrip Polars, but the average use case wouldn’t notice.
- Polars is easier to install and use on any platform basically.
- Polars is going to Rust or Python.
- Spark is going to be Scala or Python.
- (the future ain’t Scala in case you didn’t notice)
Spark has a lot of overhead when running on a single node, I mean it wasn’t made to do that. Polars is going to be faster on a single machine. I mean I could spend a bunch of time comparing the features between Polars and Spark, and maybe I will if enough people ask for it. But, I don’t see the point. It’s boring.
Boring I say. Polars works fine for its use case. Spark works for its use case. Do you want save money and try to process data on a single node in an efficient and fast manner? Use Polars. You crunch’n 100TB+ datasets on a cluster? Guess what, you’re stuck with Spark for now.
Spreading the truth