Why Do Machine Learning Models Die In Silence?
KDnuggets
JANUARY 5, 2022
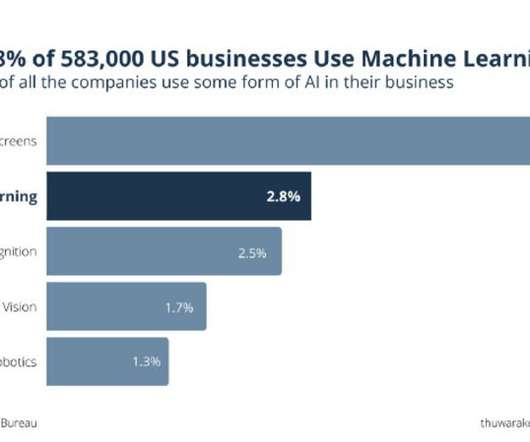
A critical problem for companies when integrating machine learning in their business processes is not knowing why they don't perform well after a while. The reason is called concept drift. Here's an informational guide to understanding the concept well.





































Let's personalize your content