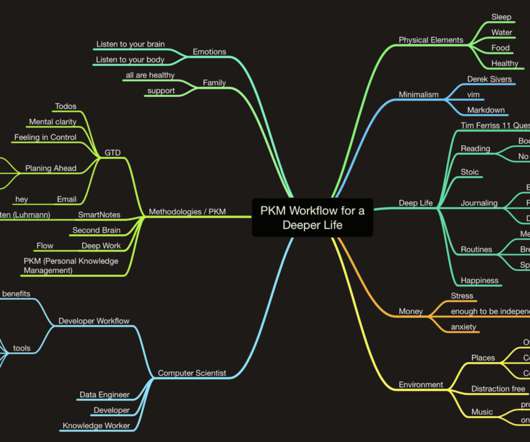
Personal Knowledge Management Workflow for a Deeper Life — as a Computer Scientist
Simon Späti
APRIL 6, 2022
With burnout and mental stress at every level of our lives, I find my Personal Knowledge Management (PKM) system even more valuable. As a human, I forget lots of things. As a dad, I have more responsibilities with remembering all things related to my kid. As a developer and knowledge worker, I re-use code snippets or create new things. That’s why a PKM system such as a Second Brain to store all of it in a sustainable way is crucial to me.


































Let's personalize your content