

Understanding Azure Synapse Analytics
You might have seen that I’ve been pretty busy recently, digging into the new Azure Synapse Analytics preview, announced back at Microsoft Build 2020. I’ve explored the spark engine, SQL serverless/On-Demand and various other bits… but I’m still getting the same question of “Cool!…. but what actually is it?”. One of the problems here is that Azure SQL Data Warehouse was rebranded as “Azure Synapse Analytics”… but it’s not the same as the full workspace. Having two products, both talked about in Marketing, one generally available, one still in preview - it’s no wonder people are still confused!
I’ve put a video together to try and explain the marketing and cut down to what exactly Synapse Analytics is, but I’ll outline it a little here too.
Ok, so firstly the marketing slide, the one that you’ve seen everywhere, including blogs of our own:
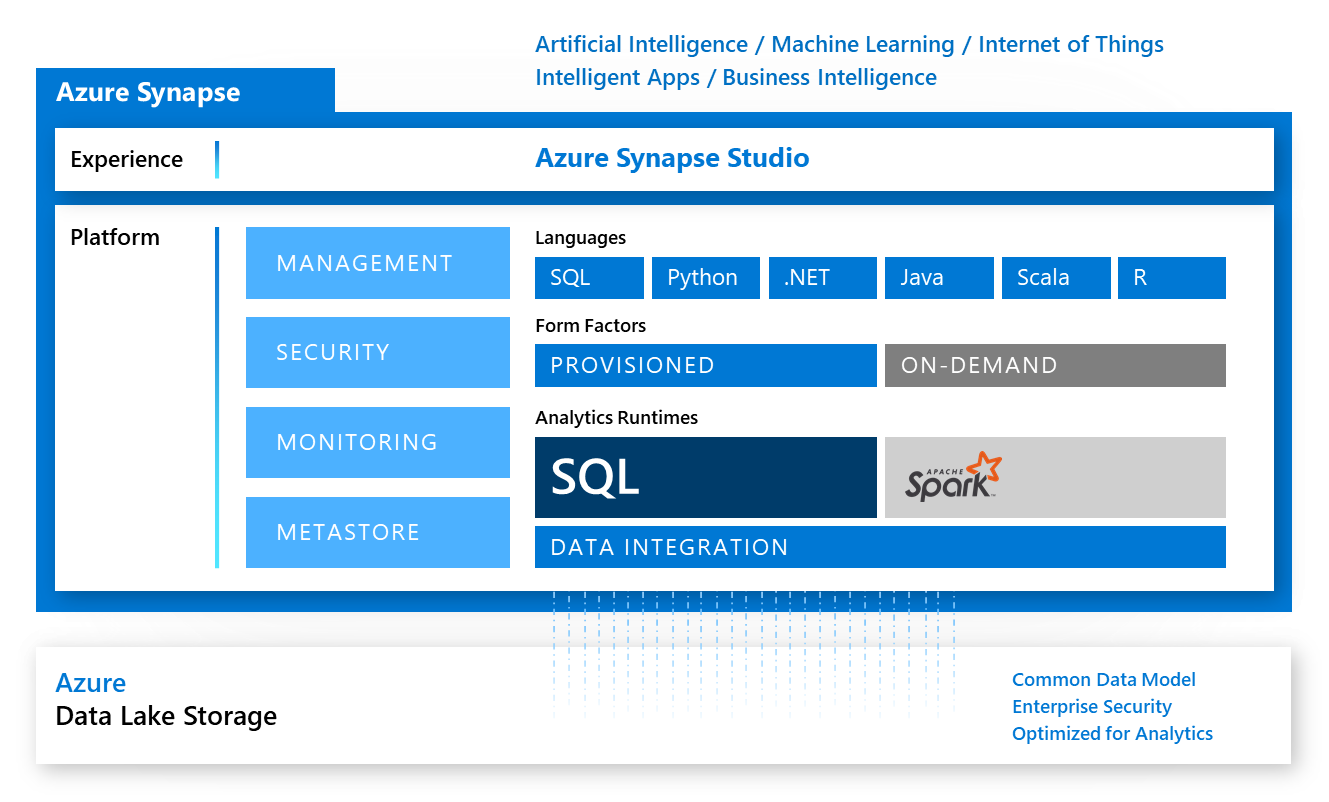
Microsoft’s Azure Synapse Overview Slide
This gives us a great overview of everything that might be inside, but doesn’t really help us know what’s actually possible. When I first looked into it, I immediately said “Oh! Spark On-Demand, Great!” - but that’s not the case, our form factors and analytics runtimes aren’t quite so compatible.
I’ve pulled it out and simplified it a bit, so we can see exactly what’s available in the current Synapse Analytics workspace:
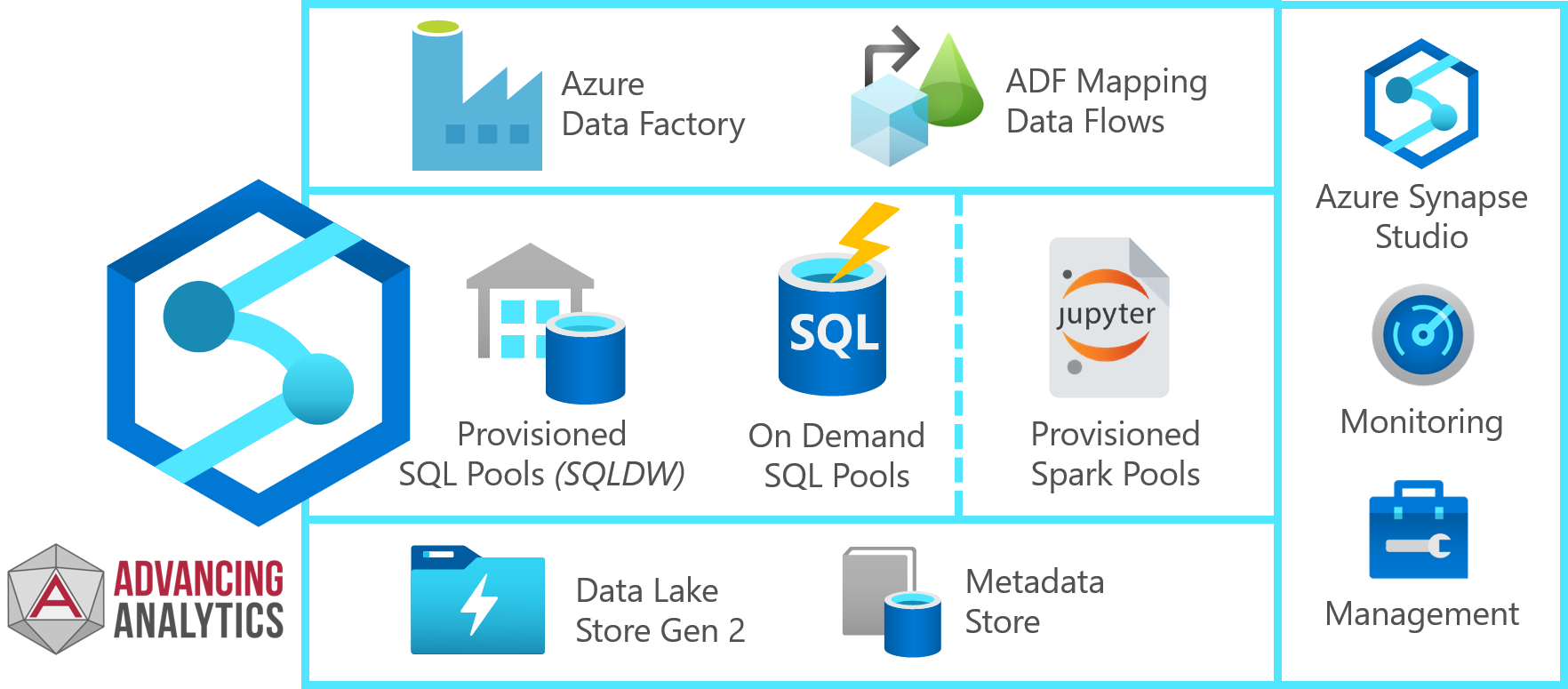
Elements inside Azure Synapse Analytics
In this case, we can see the clear separation of our different runtimes - two for SQL and one for Spark.
SQL Runtimes
So what are our two SQL Runtimes? The first - “Provisioned SQL Pools” is our old friend Azure SQL Data Warehouse in it’s new home. This should be very familiar for existing users - decide your desired number of compute nodes (DWUs), spin up a cluster, distribute tables and you’re away. This is charged by the hour, depending on the largest size of DWU used within each hour.
The other, is something of a new beast - SQL On-Demand. This allows for an infrastructure-free querying layer on top of your lake - and I’m impressed to say that the response times are FAST. With On-Demand we’re charged by Terabytes read rather than infrastructure uptime - so there’s no concept of scaling, sizing etc. We’re therefore going to have to keep usage in mind as it could easily spiral out of control if we’re repeatedly running heavy queries.
Essentially, we’re expecting to see people starting off with SQL On-Demand while they try to figure out usage levels, then - once usage is over a certain level - switch over to a provisioned cluster for economies of scale.
Spark Runtimes
This is another new element, which has also caused a bit of confusion. Synapse Analytics Workspace has a spark engine built in, along with notebook support, but this is not Databricks, it’s a spark runtime based on the vanilla, open-sourced spark project. If you’re a Databricks regular and you’re just switching over, you’ll probably find it a little jarring. There are a lot of additional quality-of-life enhancements within Databricks that are not in the Synapse Spark Pools - although we’re very much still in preview. A very interesting development here is that Synapse Spark supports C# as a first-class language, we can write Spark.NET directly within the notebooks, which isn’t possible within Databricks currently.
Spark Runtimes are charged by spark pool uptime - this idea of Spark Pools is fairly new, but essentially each workload has it’s own spark session which can be sized independently. As with other spark implementations, the cluster has a “time to live” built in. So with a 15 minute idle time defined, you can run a query and your pool will deallocate 15 minutes later - if another query attempts to use the spark pool within this time, it won’t have to wait for the cluster to start and the time to live will be reset.
Azure Synapse Analytics Evolution
Hopefully we’re now clear on what’s inside Azure Synapse Analytics Workspace, but let’s quickly address the confusion between some of the components that already existed. Azure SQL Datawarehouse is directly implemented as Azure Synapse Analytics - Provisioned SQL Pools, which is a bit of a mouthful. This is the same SQLDW we know and love, now part of a wider platform experience.
The Orchestration elements of Synapse can also trace their lineage back - we see a large amount of Azure Data Factory V2 implemented within Synapse. Currently, we don’t know whether that means Data Factory is going to move to a new home within Synapse, or we’ll see two versions of the product, one integrated and one external.
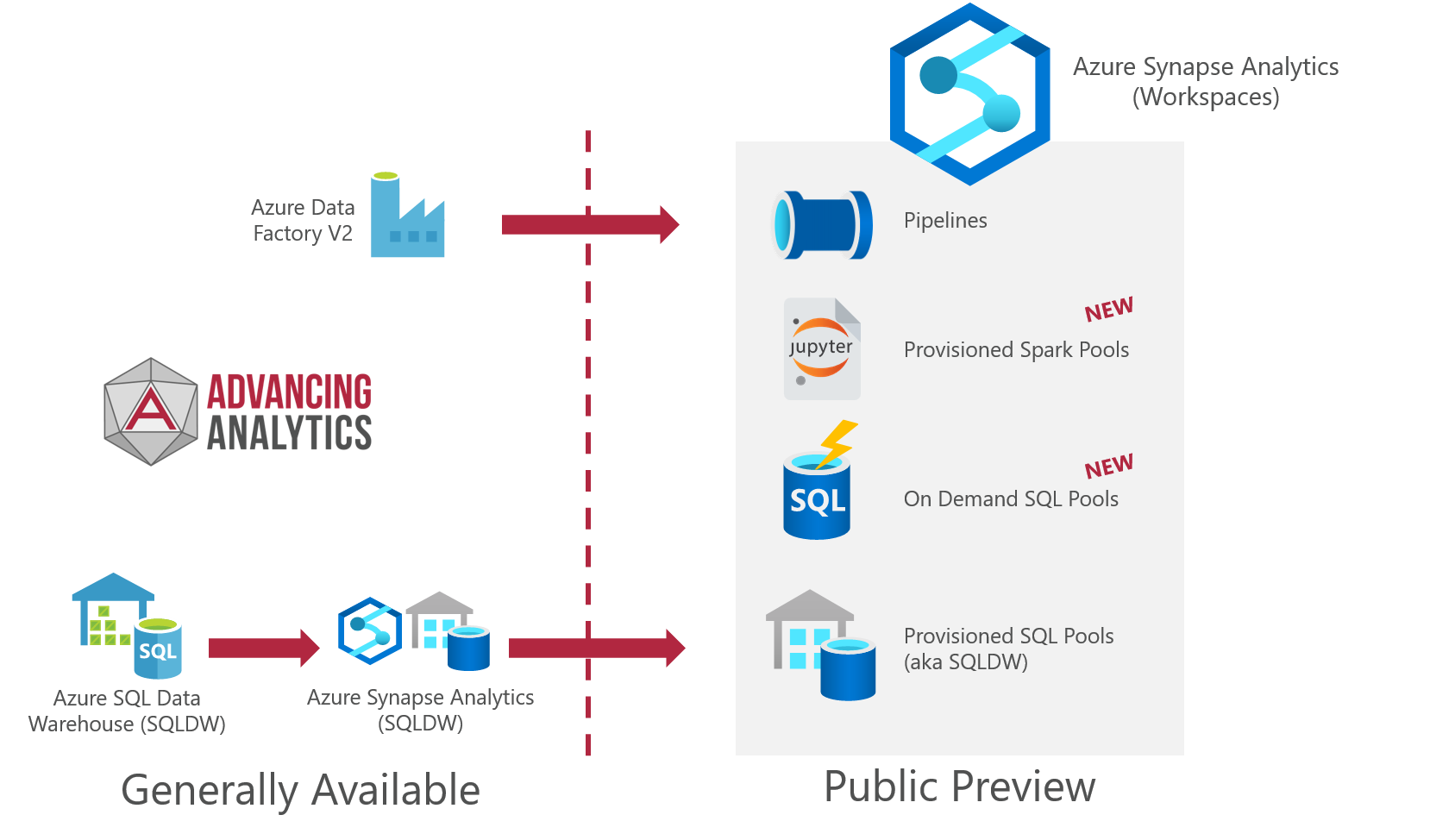
This overview has simplified things a lot, maybe we’ve oversimplified it, but hopefully it’ll help people to understand where we are currently and where we’re heading to.
We’d love it if you’d subscribe to our youtube channel - we’re posting videos exploring Synapse, Databricks and Advanced Analytics in many forms, come and join the fun!

Data Platform Microsoft MVP You can follow Simon on twitter @MrSiWhiteley to hear more about cloud warehousing & next-gen data engineering.