Apache Showdown: Flink vs. Spark
Why we chose Apache Flink for the Saiki Data Integration Platform.

Big Data Engineer

Big Data Engineer
Saiki is Zalando’s next generation data integration and distribution platform in a world of microservices. Saiki ingests data generated by operational systems and makes it available to analytical systems. In this context, the opportunity to do near real time business intelligence has presented itself and introduced the task of finding the right stream processing framework. In this post, we will describe the evaluation and decision process, and show why Apache Flink best fulfilled our requirements, as opposed to Spark.
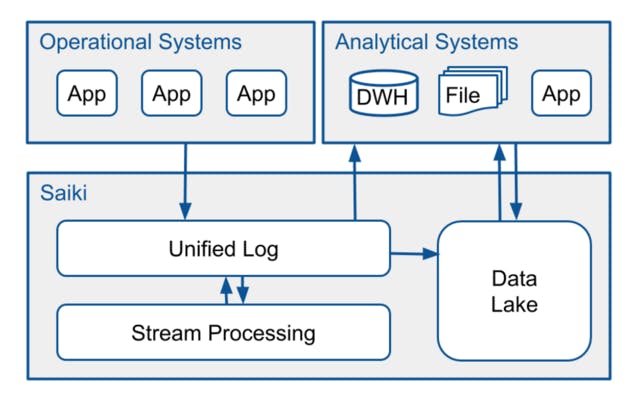
Zalando’s operational systems continuously produce events and publish those to Saiki’s unified log (Apache Kafka). From there, Saiki stores them on a data lake (Amazon S3 based) or pushes them directly to consuming analytical systems. The data lake is a centralised, secure, cost efficient data storage solution and is accessed for retrieval by our data warehouse (Oracle) and other analytical systems. This architecture enables us to do near real time business intelligence for, but not limited to, the following use cases:
Business process monitoring. A business process, in its simplest form, is a chain of business events. These represent actions performed within the whole Zalando platform. For example, when a customer places an order, the business event “ORDER CREATED” is generated by the responsible microservice. When said order is successfully processed and the pertaining shipments sent, the event “PARCEL_SHIPPED” is generated. Our team needs to monitor these business processes in order to quickly detect and act on anomalies. Continuing the example - one anomaly could be that the aforementioned events occurred within an unexpected high time interval, exceeding a previously specified threshold.
Continuous ETL. As our Oracle data warehouse struggles with increasingly high loads, we need to relinquish some of its resources by doing a part of the ETL in a different system, to secure our future growth and our ability to scale dynamically. The main cost factor is the joining of data belonging to different sources, e.g. order, shipping and payment information. As this information is written to our unified log via event streams, we want to join these into an integrated stream. Another aspect to consider is that we want to provide this data integration not only for the data warehouse, but also for other analytical downstream systems.
For the evaluation process, we quickly came up with a list of potential candidates: Apache Spark, Storm, Flink and Samza. All of them are open source top level Apache projects. Storm and Samza struck us as being too inflexible for their lack of support for batch processing. Therefore, we shortened the list to two candidates: Apache Spark and Apache Flink. For our evaluation we picked the available stable version of the frameworks at that time: Spark 1.5.2 and Flink 0.10.1.
Requirements
We formulated and prioritised our functional and non-functional requirements as follows:
First and foremost, we were looking for a highly performant framework with the ability to process events at a consistently high rate with relatively low latency. As more and more of our operational systems are migrating to the cloud and sending data to Saiki, we aimed for a scalable solution. The framework should be able to handle back pressure gracefully (i.e. spikes in throughput) without user interaction. For both of our use cases, we expected the need to use stateful computations extensively. Therefore storing, accessing and modifying state information efficiently was crucial.
We were also looking for a reliable system that would be capable of running jobs for months and remain resilient in the event of failures. A high availability mode where shadow masters can resume the master node’s work upon failure was needed. For the stateful computations, we require a checkpointing mechanism. Thus, the re-computation of a whole Kafka topic would not be necessary and a job can resume its work from where it left off before a failure.
Further important aspects for us were the expressivity of the programming model and the handling of out-of-order events. For the former, a rich and properly implemented operator library was of relevance. The programming model should enable simple but precise reasoning on the event stream and on event times, e.g. time when an event occurred in the real world. The latter aspect assumes imperfect streams of events, with events arriving to the system not in the order they occurred. It implies that the system itself can take care of out-of-order events, thus relieving the user from additional work.
Other notable functional requirements were the “exactly once” event processing guarantee, Apache Kafka and Amazon S3 connectors, and a simple user interface for monitoring the progress of running jobs and overall system load.
The non-functional requirements included good open source community support, proper documentation, and a mature framework.
Spark vs. Flink – Experiences and Feature Comparison
In order to assess if and how Spark or Flink would fulfill our requirements, we proceeded as follows. Based on our two initial use cases we built proofs of concept (POC) for both frameworks, implementing aggregations and monitoring on a single input stream of events. Due to its similarity in requirements regarding state handling and due to time limitations, we did not implement POCs for the join operation.
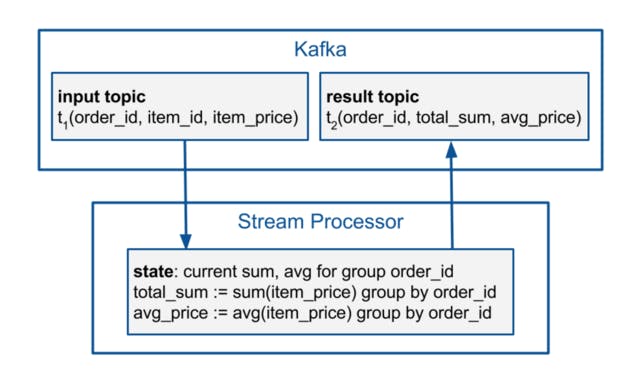
For the aggregation use case, events containing information on items belonging to orders are generated and published to a single Kafka topic. These are read by the stream processing framework. The result contains the summed item prices and the average item price for each order. The result is written back to a different Kafka topic. We use the state to store and update the current sum and average item price for each order.
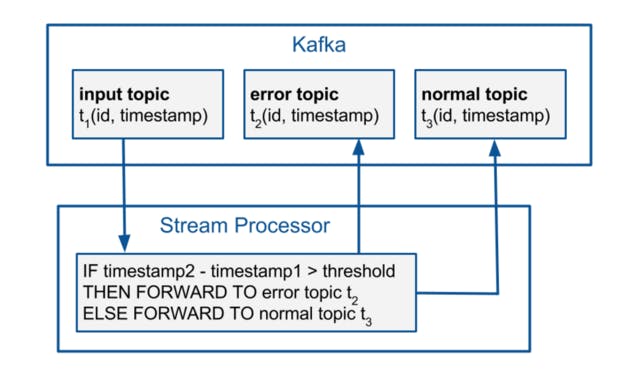
For the monitoring use case, the generated input stream contains pairs of correlated events. The first event in the pair represents the previously mentioned “ORDER CREATED” business event and the second “PARCEL_SHIPPED” event. The time difference between the timestamps of the first and last event is set to a random number of days. The events are differentiated according to the time difference and a threshold. The event stream is split into two streams: Error and normal. The error stream contains all events for which the specified threshold has been exceeded, while the normal stream contains the rest. These streams are then written back to Kafka.
The aggregation use case has been implemented successfully for both frameworks. Implementing the monitoring use case has been more intuitive in Flink, mainly because of the existence of the split operator, for which there was no equivalent in Spark.
Regarding the performance of both frameworks, Flink outperformed Spark for our stream processing use cases. Flink offered a consistently lower latency than Spark at high throughputs. Increasing the throughput has a very limited effect on the latency. For Spark, there is always a trade off between throughput and latency. The user must manually tune Spark’s configuration depending on the desired outcome. This of course also incurs redeployment costs. Our experiences were consistent with the Yahoo! benchmark.
Spark 1.5.2 and Flink 0.10.1 state implementations were dissimilar and delivered expectedly different results. Spark implements the state as a distributed dataset, while Flink employs a distributed in memory key/value store. With increasing state, Spark's performance constantly degrades, as it scans its entire state for each processed microbatch. It remains reliable and does not crash. Flink only has to look up and update the stored value for a specific key. Its performance is constantly high, but it may throw OutOfMemoryErrors and fail the computation. This is due to the fact that it could not spill the state to disk. This issue has been discussed and addressed by the software company data Artisans. The current 1.0.0 version offers the possibility to use an out-of-core state based on RocksDB.
Based on our experiences, we summarised and assessed the features most relevant to our requirements of Spark and Flink in the following table:
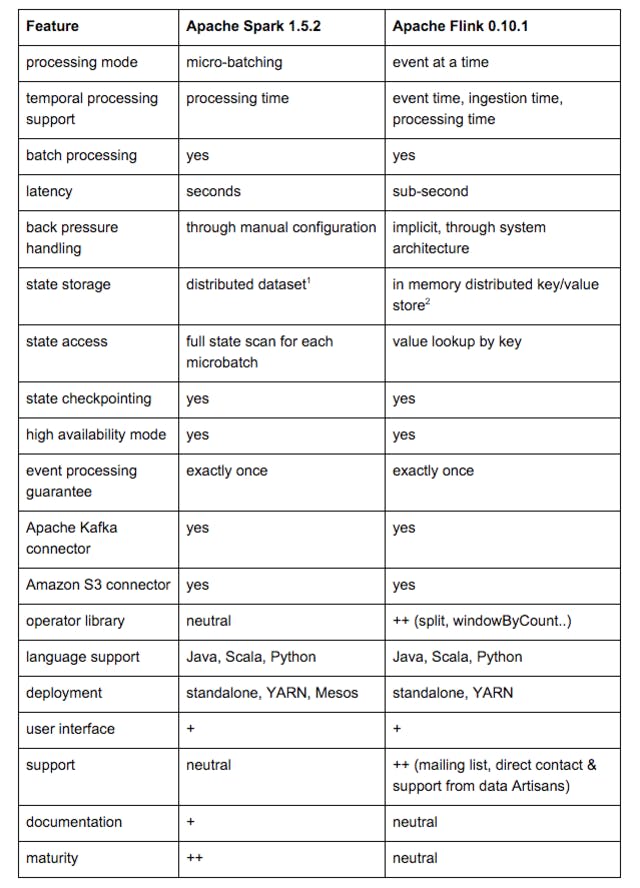
Notes: 1. After our evaluation, Spark 1.6 introduced a key/value store for the state. 2. The current Flink 1.0.0 version offers the possibility to use an out-of-core state based on RocksDB.
Flink for Saiki
Why did we end up choosing Apache Flink to be Saiki’s stream processing framework? Here are our reasons:
- Flink processes event streams at high throughputs with consistently low latencies. It provides an efficient, easy to use, key/value based state.
- Flink is a true stream processing framework. It processes events one at a time and each event has its own time window. Complex semantics can be easily implemented using Flink’s rich programming model. Reasoning on the event stream is easier than in the case of micro-batching. Stream imperfections like out-of-order events can be easily handled using the framework’s event time processing support.
- Flink’s support is perceivably better than Spark’s. We have direct contact to its developers and they are eager to improve their product and address user issues like ours. Flink originates from Berlin’s academia, and a steady flow of graduates with Flink skills from Berlin’s universities is almost guaranteed.
Our team is currently working on implementing a solution for near real time business process monitoring with Flink. We are continuously learning from the Flink community and we’re looking forward to being an active part of it. The release of Flink 1.0.0 has only strengthened our efforts in pursuing this path.



