Replacing Pandas with Polars. A Practical Guide.

Photo by Stone Wang on Unsplash
I remember those days, oh so long ago, it seems like another lifetime. I haven’t used Pandas in many a year, decades, or whatever. We’ve all been there, done that. Pandas I mean. I would dare say it’s a rite of passage for most data folk. For those using Python, it’s probably one of the first packages you use other than say … requests?
You know, Pandas feels like Airflow, everyone keeps talking about its demise, but there it is everywhere … used by everyone. Sure it’s old, wrinkled, annoying, slow, and obtuse, but it’s ours, and that makes it the words of Gollum … precious.
We should probably get to the point already. Everyone is talking about Polars. Polars is supposed to replace Pandas. Will it? Maybe 10 years from now. You can’t untangle Pandas from everywhere it exists overnight. Do you still want to replace Pandas with Polars and be one of the cool kids? Ok. Let’s take a look at a practical guide to replacing Pandas with Polars, comparing functionally used by most people. My code is available on GitHub.
Gentle Introduction to Polars … and Pandas.
I’m sure you highly informed people don’t need me to give you a background on what exactly Pandas and Polars are and do, but let’s not assume everything. Here’s what we can say about them both.
- Both tools are heavily used via Python.
- Both tools are used to manipulate data by legions of people.
- Both tools are Dataframe based (aka that’s why people use them).
- Both tools try to give aggregated-based operations on Dataframes.
- Both tools try to give options for the read-and-write complexity of different data sources.
- Both tools are used to transform data sets.
I mean for better or worse that’s why the data world fell in love with Pandas. It makes working with data easy, or easier than most other options available. We, humans, are lazy beings, eating potato chips on the couch, we want life to be filled with luxury and fine things. That my friend is why Pandas rose to power and defeats all others trying to dethrone it.
Will Polars be the one to step into the ring, and throw the knockout punch? Who knows. I can say it will depend on how easy it is to replace Pandas with Polars.
If it were always a simple question of “what’s faster,” the software world would look much different than it does today. In the end, there are fickle and biased humans at the end of the line, the consumers of this software, and they don’t always follow reason or logic … aka what’s faster.
Let’s move on.
Side-by-side functionality, Pandas vs Polars.

I’ve been curious about this myself, and I think it’s a good exercise in understanding to find out what the average data user will find when trying to replace Polars with Pandas. Sure, we all know Pandas is slow, runs out of memory, and the like. We know that Polars is fast and able to deal with larger-than-memory data sets, etc, but that I not what I want to focus on today.
I will try to mention some of those nice Polars features later if time permits. But, let’s simply compare normal, everyday things that folks do in and with Pandas, try them with Polars and find out what we find out. That begs the question, what should we try?
- Reading and writing CSV files.
- Reading and writing Parquet files.
- Renaming, adding, or removing a column, and also transforming one column into a new one.
- Aggregations and Grouping.
Let’s get started!
Reading and writing CVS files.
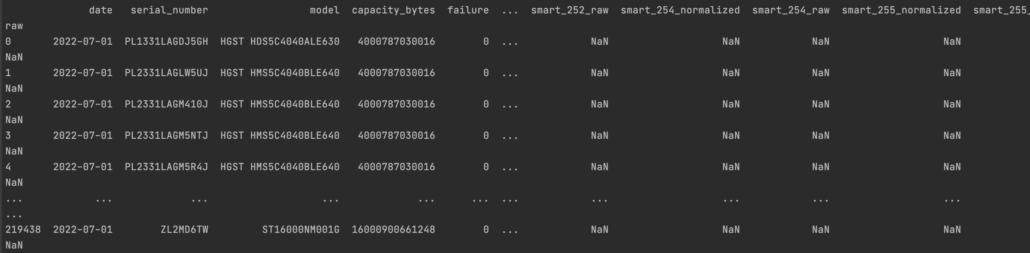
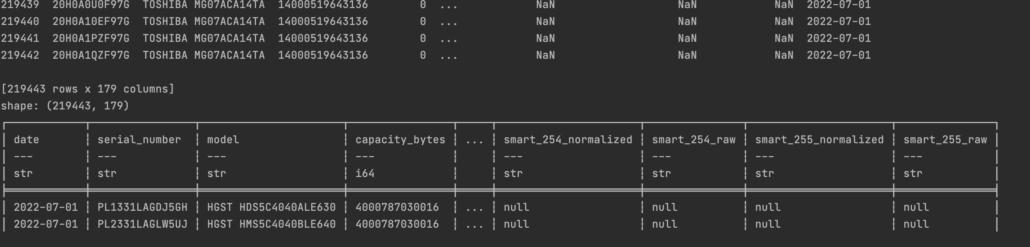
Well, the formatting is much nicer and contains more info in Polars.
Pandas.
Polars.
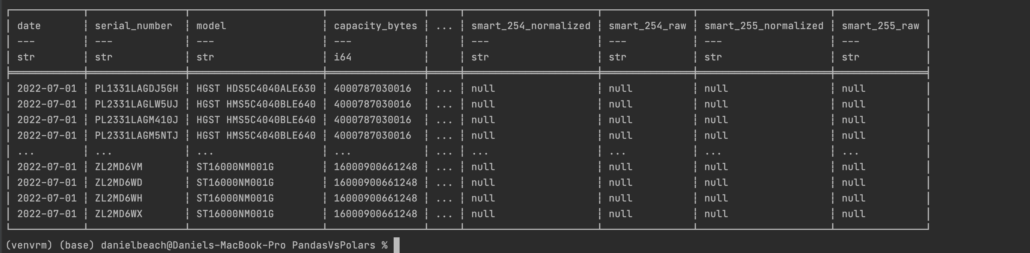
Having the nice format and data types at your fingertips with Polars is very nice. Especially when trying to explore new datasets, probably seems small detail but is very helpful.
Reading and writing Parquet files.
Parquet files have become very common these days, when exploring and munging data it’s very common to read and write local parquet files. Let’s see it in action. Let’s read our CSV file, write it to parquet with a partition, and then read it back again.
Something interesting happened. According to the Polars documentation there is no option to write parquet files with a partition column(s) … which kinda defeats the purpose of parquet files. It isn’t clear if we should just import pyarrow and write the Polars Dataframe to a PyArrow dataset and use the functionality there.
The documentation also says “Use C++ parquet implementation vs Rust parquet implementation. At the moment C++ supports more features.” So I guess we can set that to True and pass the partition columns? Polars should be more clear and get with the game. Parquets are important and deserve first-class support or clear documentation. I would assume we would use the options listed in the PyArrow write_table functionality listed here.
Polars gives the option to “pyarrow_options Arguments passed to pyarrow.parquet.write_table.” If you look at the docks for PyArrow write_table no mention of partitions. Those docs in turn mention ParquetWriter, but those docs have no mention of partitions either.
At this point let’s suffice it to say, Polars doesn’t match Pandas with the ability to write partitioned parquet data sets … at least not without some anticks apparently.
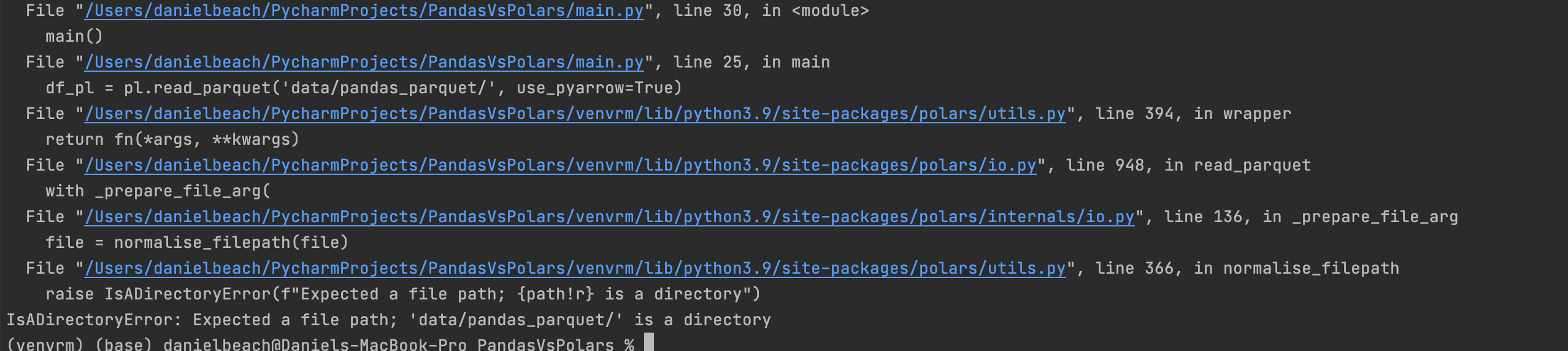
Also, it’s worthy of note IF you try to write to a newly appointed, non-existentParquet directory like this … in Polars … pl_df.write_parquet('data/polars_parquet/')

Funny as it sounds, you must remove the offending, trailing / to get Polars not to puke. This is probably because Polars, with no partitions (arg) for parquets, is going to try to write a single parquet file for whatever you are writing. Blah.
Again, the output is what I expected … except that I’m a little miffed that Polars and parquets with partitions is such a deal.
BTW, it’s worth noting that trying to read the directory of Parquet files output by Pandas, is super common, the Polars read_parquet()cannot do this, it pukes and complains, wanting a single file.
Yikes, enough of that. Time to move on.
Renaming, adding, or removing a column. With transformation as well.
Ok, I’m glad to try something else now. What about the trivial task of renaming, adding, or removing columns from Pandas vs Polars. This is very a very common task when munging data.
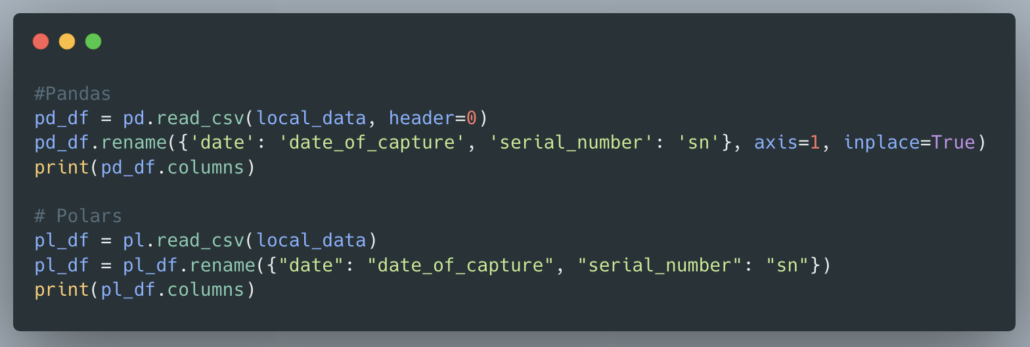
Not much to see, how about adding and removing columns?
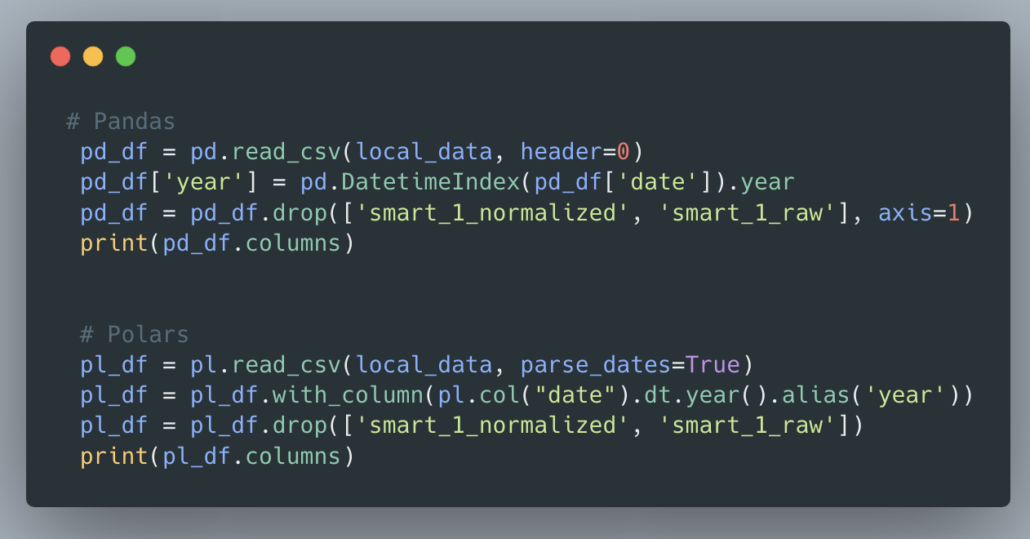
Pretty much what you would expect, I do enjoy the PySpark style of renaming columns with with_column.
Aggregations and Grouping.
This is probably one of the other most common steps to take with a Dataframe, Pandas or Polars, doing some aggregation and grouping. Let’s see how they work out.
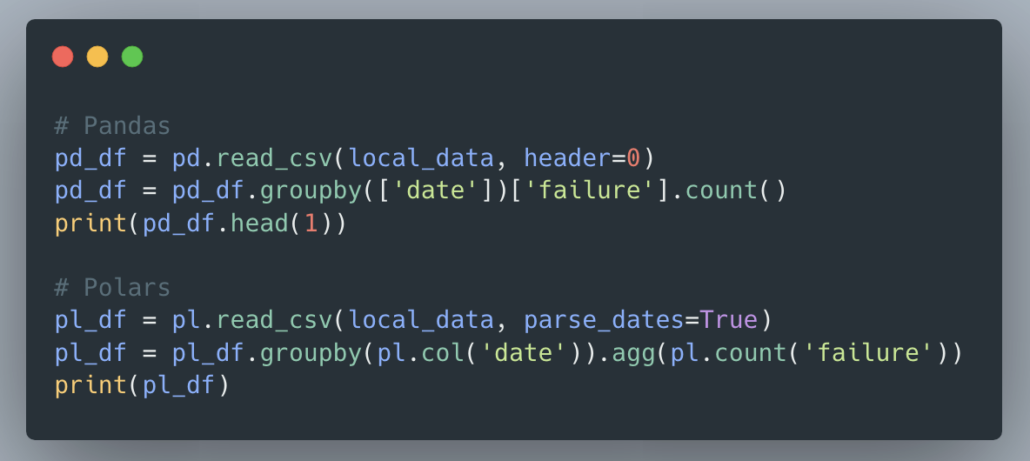
The results are the same for both.
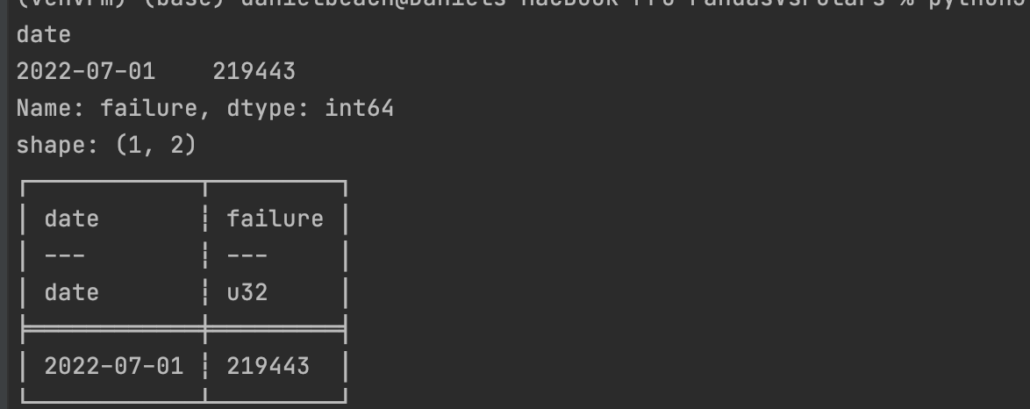
Not much to say there, pretty much the same.
Thoughts on replacing Pandas with Polars.
I’m not sure what to think, will Polars really come to replace Python? Probably not anytime soon. I don’t think it’s necessarily a problem with Polars per say, but just that Pandas is so embedded everywhere and it’s hard to back out of those decisions once they get spread throughout a code base.
Now, if you’re using Pandas for simple data munging on your local laptop, could Polars be the better choice? Of course, it has way better speed, seems to be more Pythonic to write, and won’t blow up on memory if you start to use the scan options. I was taken aback a bit by its inability to write and read parquets with partitions, as this feature seems to be kind of an obvious one.
Overall someone could with very little trouble, and a day of work, replace Pandas with Polars, and the code would run faster, look better, and probably not drive so many people crazy like Pandas and it’s strange syntax. Part of the allure of Polars from my point of view is that it “flows” better than Pandas, Pandas can just be plain awkward to write.
One comment on your blog – using actual code and console output text excerpts rather than screenshots of your IDE would be a lot more readable.