What’s New in Apache Kafka 3.3
Confluent
OCTOBER 3, 2022
Apache Kafka 3.3 includes KRaft mode, improves partition scalability and resiliency while simplifying Kafka deployment, as well as updates to Kafka Streams, Connect, and more.

Confluent
OCTOBER 3, 2022
Apache Kafka 3.3 includes KRaft mode, improves partition scalability and resiliency while simplifying Kafka deployment, as well as updates to Kafka Streams, Connect, and more.

KDnuggets
OCTOBER 3, 2022
Projects like this are not only beginner friendly, but they add a little bit of fun to your studies or career.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
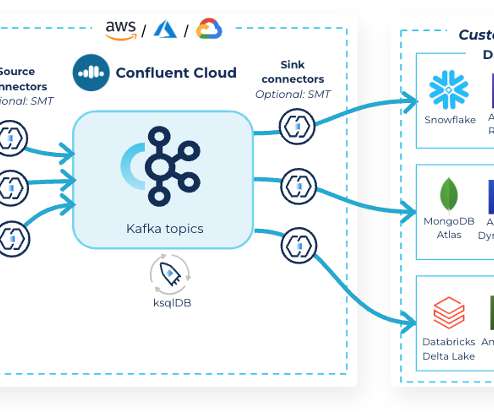
Confluent
OCTOBER 3, 2022
Announcing Confluent for Startups! Get started with Apache Kafka, leverage our data streaming expertise, and set your business up with the best infrastructure for scale and success.
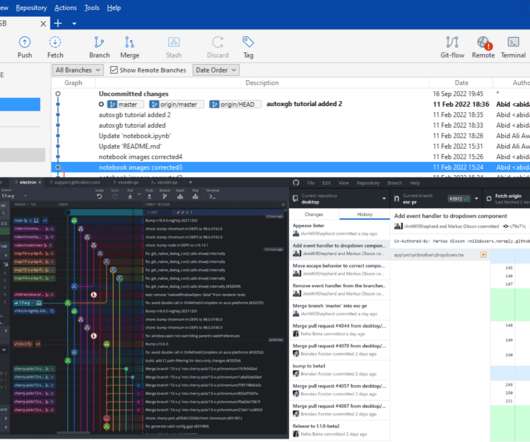
KDnuggets
OCTOBER 3, 2022
Learn about beginner-friendly Git GUI clients and perform Git-based tasks using an interactive user interface.

Speaker: Timothy Chan, PhD., Head of Data Science
Are you ready to move beyond the basics and take a deep dive into the cutting-edge techniques that are reshaping the landscape of experimentation? 🌐 From Sequential Testing to Multi-Armed Bandits, Switchback Experiments to Stratified Sampling, Timothy Chan, Data Science Lead, is here to unravel the mysteries of these powerful methodologies that are revolutionizing how we approach testing.

Propel Data
OCTOBER 3, 2022
In Snowflake, you allocate “virtual warehouses” (computing clusters) to execute the SQL database commands that you run on the data platform.

Cloudera
OCTOBER 3, 2022
Tell us if this sounds familiar. You’ve found an awesome data set that you think will allow you to train a machine learning (ML) model that will accomplish the project goals; the only problem is the data is too big to fit in the compute environment that you’re using. In the day and age of “big data,” most might think this issue is trivial, but like anything in the world of data science things are hardly ever as straightforward as they seem. .

Expert insights. Personalized for you.






Let's personalize your content