From Data Collection to Model Deployment: 6 Stages of a Data Science Project
KDnuggets
JANUARY 23, 2023
Here are 6 stages of a novel Data Science Project; From Data Collection to Model in Production, backed by research and examples.

KDnuggets
JANUARY 23, 2023
Here are 6 stages of a novel Data Science Project; From Data Collection to Model in Production, backed by research and examples.

databricks
JANUARY 23, 2023
This is a collaborative post from Databricks and Census. We thank Parker Rogers, Data Community Advocate, at Census for his contributions. In this.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

KDnuggets
JANUARY 23, 2023
Get your hands on these gems to learn Python, data analytics, machine learning, and deep learning.
Ascend.io
JANUARY 23, 2023
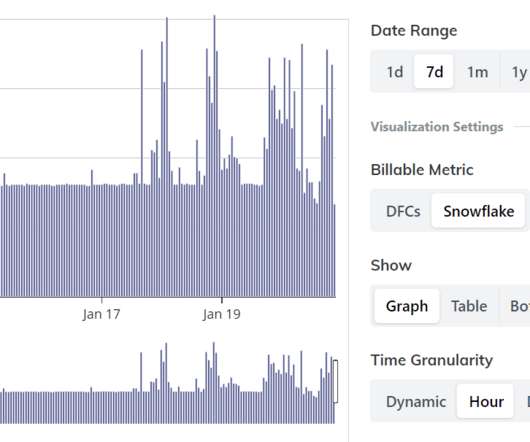
Welcome to the first product update of 2023! Our engineering team has been busy with customer-driven requirements you can read about in our release notes , but this week let’s highlight two key new capabilities that enhance your intelligent data pipelines. New Data Plane Usage Report As your data workloads grow, it becomes increasingly important to balance the costs of data pipelines against the new business value being created.

Speaker: Timothy Chan, PhD., Head of Data Science
Are you ready to move beyond the basics and take a deep dive into the cutting-edge techniques that are reshaping the landscape of experimentation? 🌐 From Sequential Testing to Multi-Armed Bandits, Switchback Experiments to Stratified Sampling, Timothy Chan, Data Science Lead, is here to unravel the mysteries of these powerful methodologies that are revolutionizing how we approach testing.
KDnuggets
JANUARY 23, 2023
JupyterHub is a multi-user, container-friendly version of the Jupyter Notebook. However, it can be difficult to setup. This blog post will make you less likely to run into issues in this 15+ step process.
Edureka
JANUARY 23, 2023
The use of data by companies to understand business patterns and predict future occurrences has been on the rise. With the availability of new technologies like machine learning, it has become easy for experts to analyse vast quantities of information to find patterns that will help establishments make better decisions. Data mining is a method that has proven very successful in discovering hidden insights in the available information.
Data Engineering Digest brings together the best content for data engineering professionals from the widest variety of industry thought leaders.

dbt Developer Hub
JANUARY 23, 2023
Testing the quality of data in your warehouse is an important aspect in any mature data pipeline. One of the biggest blockers for developing a successful data quality pipeline is aggregating test failures and successes in an informational and actionable way. However, ensuring actionability can be challenging. If ignored, test failures can clog up a pipeline and create unactionable noise, rendering your testing infrastructure ineffective.

Acceldata
JANUARY 23, 2023
Learn about the differences between data observability vs. data monitoring and why data observability is a better choice for optimizing the modern data stack.

Tweag
JANUARY 23, 2023
Tweag is a big supporter and user of Nix and NixOS. In our experience, however, we have seen that it is hard to maintain a Nix codebase as it grows. Indeed, the only way to know if a Nix expression is correct is to evaluate it, and when an error occurs it can be hard to locate the root cause. This is more of a problem with bigger codebases, such as the ones we write.

Snowflake
JANUARY 23, 2023
Marketing data integration is the process of combining marketing data from different sources to create a unified and consistent view. If you’re running marketing campaigns on multiple platforms—Facebook, Instagram, TikTok, email—you need marketing data integration. Why? Because being able to assimilate data from different channels and across multiple marketing touchpoints gives you visibility into the overall impact of a campaign, event, or another marketing effort.

Speaker: Anne Steiner and David Laribee
As a concept, Developer Experience (DX) has gained significant attention in the tech industry. It emphasizes engineers’ efficiency and satisfaction during the product development process. As product managers, we need to understand how a good DX can contribute not only to the well-being of our development teams but also to the broader objectives of product success and customer satisfaction.
Lyft Engineering
JANUARY 23, 2023
By Sara Smoot , Alex Contryman and Yanqiao Wang Lyft hosts a dynamic marketplace connecting millions of people to a robust transportation network. In order to offer high value and quality service for both riders and drivers we need to make complex optimization decisions in near-real time. The environment can change quickly with traffic, events and weather, making these decisions even more challenging.
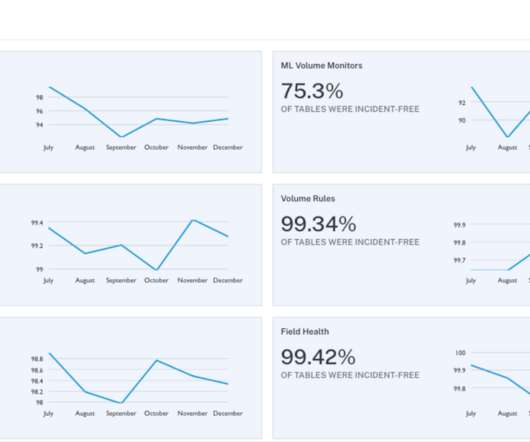
Monte Carlo
JANUARY 23, 2023
Data lineage , an automated visualization of the relationships for how data flows across tables and other data assets, is a must-have in the data engineering toolbox. Not only is it helpful for data governance and compliance use cases, it also plays a starring role as one of the 5 pillars of data observability. Data lineage both accelerates a data engineer’s ability to understand the root cause of a data anomaly, as well as the potential impact it may have on the business.

Precisely
JANUARY 23, 2023
In its most recent Data Trust Survey, analyst firm IDC reports that just over a quarter (27%) of data practitioners fully trust the data with which they routinely work. As enterprises forge ahead with a host of new data initiatives, data quality remains a top concern among C-level data executives. In its Data Integrity Trends report , Corinium found that 82% of respondents believe data quality concerns represent a barrier to their data integration projects.

DataKitchen
JANUARY 23, 2023
What is data lineage? Data lineage traces data’s origin, history, and movement through various processing, storage, and analysis stages. It is used to understand the provenance of data and how it is transformed and to identify potential errors or issues. Data lineage can also be used for compliance, auditing, and data governance purposes. Data lineage has a long history, starting as a tool for compliance and auditing in mainframe systems, evolving to address the challenges of understandin

Speaker: Aarushi Kansal, AI Leader & Author and Tony Karrer, Founder & CTO at Aggregage
Software leaders who are building applications based on Large Language Models (LLMs) often find it a challenge to achieve reliability. It’s no surprise given the non-deterministic nature of LLMs. To effectively create reliable LLM-based (often with RAG) applications, extensive testing and evaluation processes are crucial. This often ends up involving meticulous adjustments to prompts.
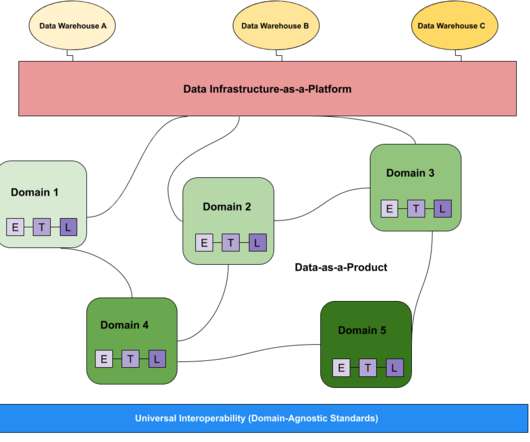
Monte Carlo
JANUARY 23, 2023
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs data lake” is right at the top of that list. But which is better? And more importantly, which one is right for your organization? In this post we compare and contrast the data mesh vs data lake to illustrate the benefits of each and help discover what’s right for your data platform.

Expert insights. Personalized for you.






Let's personalize your content