
Picture yourself in the bustling world of a leading streaming platform, where countless users rely on personalized recommendations for their next binge-watching adventure. Behind the scenes, a team of data wizards tirelessly crunches mountains of data to make those recommendations sparkle. As one of those wizards, we’ve seen the challenges we face: the struggle to transform massive datasets into meaningful insights, all while keeping queries fast and our system scalable. But then, a game-changer emerged – DBT (Data Build Tool). With DBT’s materializations, our data transformations underwent a magical transformation themselves. It was as if we found the ultimate spellbook to simplify our work and unleash its full potential.
In this blog, we’ll whisk you away on an enchanting journey through DBT materializations. Together, we’ll unravel the secrets behind efficient, reusable, and high-performing data models that will revolutionize how you wield your data.
So grab your wands (or keyboards), and let’s cast a spell of mastery over data transformations like never before. 🪄
In this blog, we will cover:
- What is DBT?
- Understanding Materializations
- Exploring DBT Materialization Strategies
- Use Cases and Best Practices of DBT Materializations
- Limitations and Considerations of DBT Materializations
- Hands-On: Implementing Materializations in DBT
- Conclusion
What is DBT?
In the vast realm of data engineering and analytics, a tool emerged that felt like a magical elixir. Its name? DBT, the Data Build Tool. Think of DBT as the trusty sidekick that accompanies data analysts and engineers on their quests to transform raw data into golden insights. It’s an open-source command-line tool, crafted with love by a community of data enthusiasts. Now, imagine being part of a team at a streaming platform, like the ones you rely on for endless entertainment.
Every day, this team, much like an army of sorcerers, weaves their spells to wrangle colossal amounts of data. That’s where DBT swoops in, casting its spell and empowering the team to build data models in a version-controlled, organized, and repeatable manner.
With DBT, the tangled web of data transformations becomes untangled, and the once-daunting task of building data models becomes as effortless as flicking a wand.
So, whether you’re a seasoned analyst or a curious apprentice, DBT awaits to make your data journey more enchanting and your outcomes truly magical.
Understanding Materializations
Let’s demystify the concept of DBT materializations in simple terms. Imagine you have a large dataset that you need to transform and analyze for insights. Data transformations can be time-consuming and complex, often requiring repetitive calculations.
DBT materializations provide a solution to this challenge. Think of them as pre-calculated results or summaries of your transformed data. These materializations act like ready-to-use building blocks, enabling faster query performance. Instead of recalculating the transformations every time you run a query, you can leverage the pre-calculated materializations to get instant results.
Moreover, DBT materializations can handle incremental updates. As your source data changes, you can update the materializations incrementally, rather than starting the entire transformation process from scratch. This saves time and resources by only updating the necessary portions of the transformed data.
In simpler terms, DBT materializations make your data transformations more efficient and faster. They provide a shortcut by pre-calculating and storing intermediate results, allowing you to speed up your queries. Additionally, they offer a way to keep your transformed data up to date without redoing the entire transformation process.
By using DBT materializations, you can streamline your data workflows and focus on gaining insights rather than spending excessive time on repetitive calculations. It’s like having a toolbox of pre-calculated data pieces that you can use whenever you need them, saving you both time and effort.
Exploring DBT Materialization Strategies
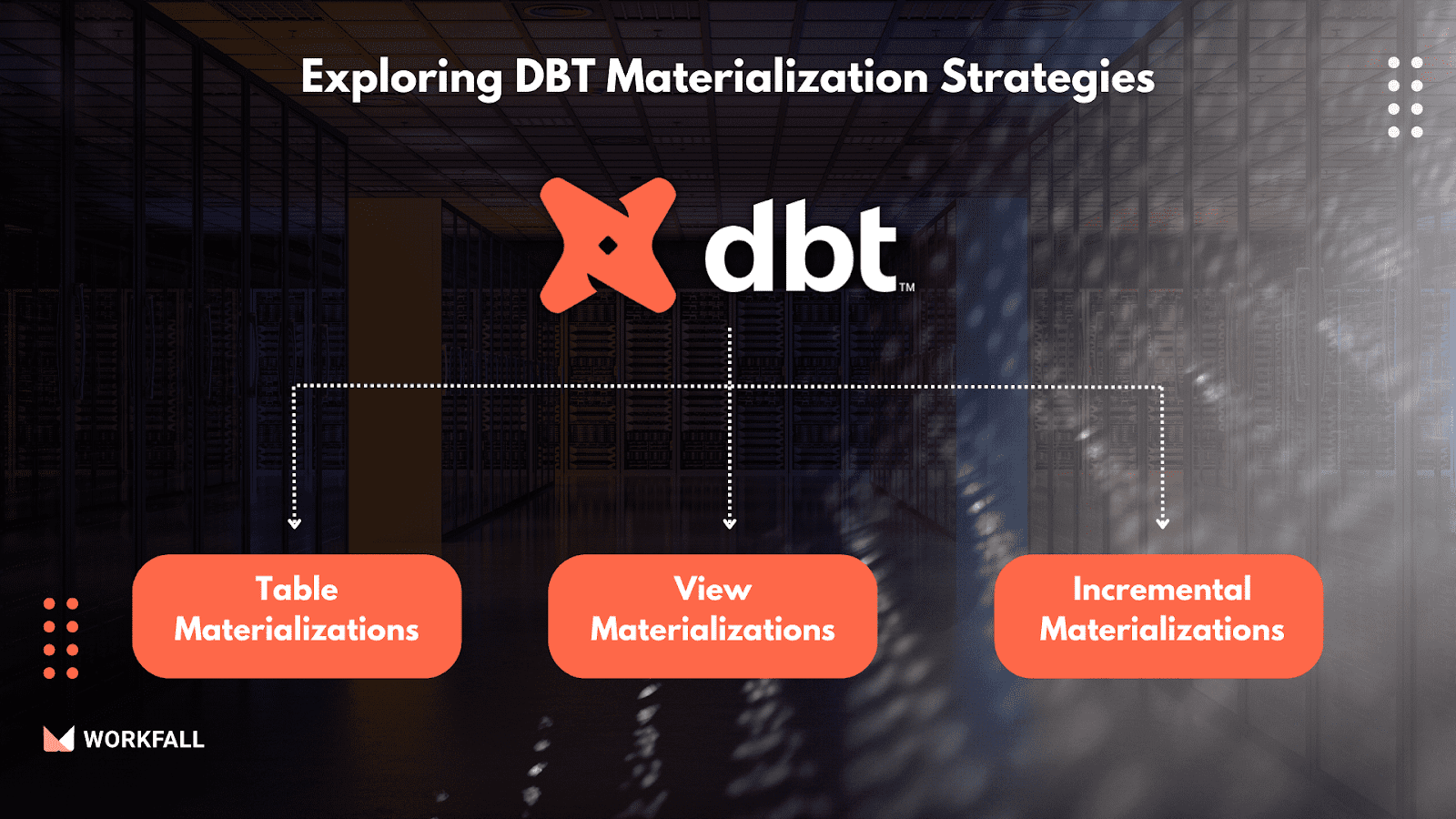
Now that we understand the power of DBT materializations, let’s explore the different strategies available to us. Think of these strategies as different approaches to building and storing the pre-calculated results of our transformed data.
Table Materializations

This means storing the transformed data as tables in a database. It’s like having a set of ready-to-use tables that you can query directly for faster results. Table materializations are great for situations where you frequently access the same data or need to join multiple tables together.
The default is “view” but if we change it to “table” then we can see our model is built as a table instead of a view.
Before :
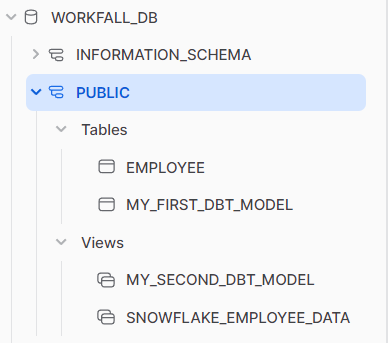
After :

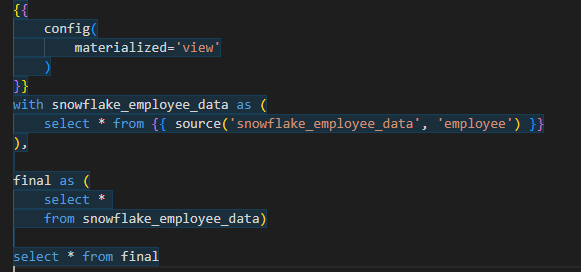
View Materializations
With view materializations, we create virtual views that represent the transformed data. It’s like having a window into the pre-calculated results without actually storing them as separate tables. View materializations are useful when you want to keep your storage footprint small while still benefiting from faster query performance. This materialization is by default.
Command:
{{ config(materialized='table') }}
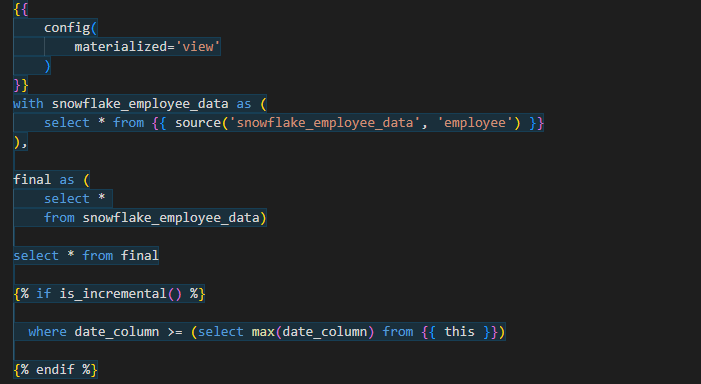
Incremental Materializations
Incremental materializations are another powerful strategy. They allow us to update the pre-calculated results incrementally as our source data changes. It’s like applying only the necessary changes to our transformed data, rather than redoing the entire process. Incremental materializations are particularly beneficial for large datasets that undergo frequent updates, as they save time and resources. We would be discussing this in detail in our next sections.
Command:
{{ config(materialized='incremental') }}
Ephemeral materializations
There are also other materialization options worth considering, such as ephemeral materializations and external table materializations. Ephemeral materializations are temporary and exist only for the duration of a specific query or session. They provide flexibility but don’t persist beyond that specific context. On the other hand, external table materializations allow us to store the pre-calculated results in external systems, such as cloud storage. This can be helpful when working with data across different platforms or when dealing with extremely large datasets.
Command:
{{ config(materialized='ephemeral') }}
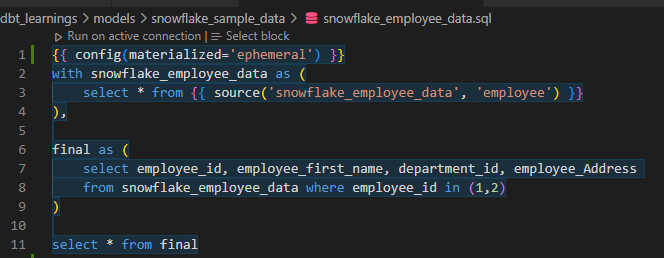
It is configured just like the other styles.
Use Cases and Best Practices of DBT Materializations
- Use table materializations for large datasets that require frequent analysis, speeding up queries and enabling complex calculations.
- Employ view materializations when storage resources are limited, as they provide faster query performance without increasing storage requirements.
- Leverage incremental materializations for constantly changing data, updating only the necessary portions of pre-calculated results instead of recomputing everything.
- Ephemeral materializations are ideal for temporary or ad-hoc analyses, while external table materializations offer flexibility across different platforms or for handling massive datasets.
- Balance query performance and storage requirements when selecting a materialization strategy.
- Test and validate materializations to ensure accuracy and reliability.
- Monitor and update materializations as data sources and requirements evolve to maintain up-to-date insights.
Limitations and Considerations of DBT Materializations
- Storage: Materializations require additional disk space, so consider your storage resources and optimize their usage accordingly.
- Data Freshness: Materializations store pre-calculated results, which may introduce a slight delay in reflecting the most recent changes in your data. Consider the trade-off between query performance and the timeliness of your insights.
- Dynamic Data: Materializations can add complexity when dealing with rapidly changing data. Carefully manage the refresh and update frequency to ensure accuracy and relevance.
- Materialization Selection: Not all materialization strategies are suitable for every use case. Choose the strategy that aligns with your specific requirements, considering query patterns, data volume, and transformation complexity.
- Testing and Validation: Thoroughly test and validate your materializations to ensure accuracy and reliability before relying on them for critical insights.
Hands-On: Implementing Materializations in DBT

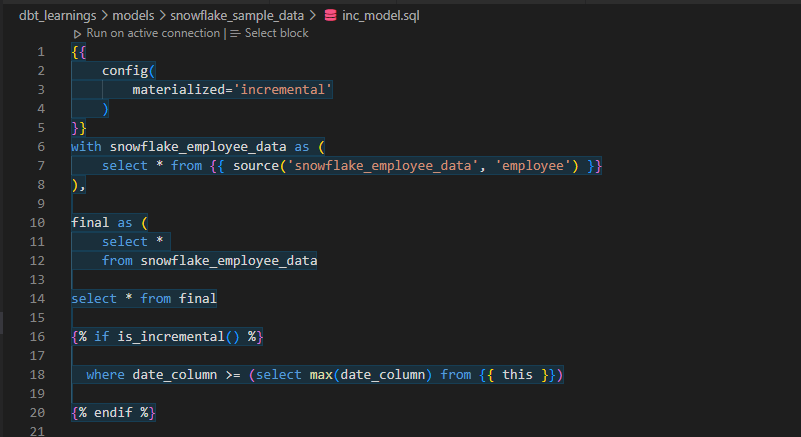
Now, let’s implement an incremental approach. It is used to transform only the new records loaded at some data source.
- Prerequisites: To initiate the DBT CLI on your system, kindly refer to our dedicated blog, which provides a detailed walkthrough on the setup procedure.
Source Table:

- We can see that in date_column there is an entry for 2023-07-07 which is new and we don’t want to transform the entire data but only the newly added row.
Add the config changes to your model.

- Now let us apply a filter using the macro is_incremental() such that the model selects only the newly added row.
- Let’s first check the dataset before executing :

- We can see that the data is loaded only for 2023/07/06. The filter which we have used checks that if there is a new date value that is max, then take that record and add it to the target model table.
After executing the DBT run :
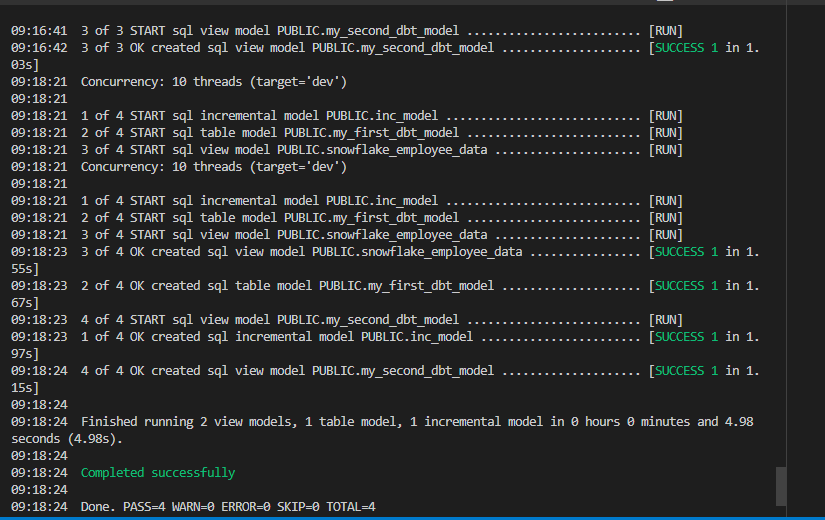
- Change in target model date:

We can see that a new record of 2023/07/07 has been added at the end.
Conclusion
In this blog, we demonstrated how to master data transformations with DBT materializations. In the field of data engineering and analytics, the utilization of DBT materializations has emerged as a potent technique for enhancing data transformations. By harnessing pre-computed, reusable views or tables, DBT materializations facilitate quicker query execution, increased productivity, and streamlined data processes.
Throughout this journey, we’ve explored the different materialization strategies offered by DBT, such as table materializations, view materializations, and incremental materializations. We’ve delved into their practical use cases, best practices, and considerations to make the most of this transformative tool.
While DBT materializations bring numerous benefits, it’s important to be aware of limitations around storage, data freshness, and dynamic data. By understanding these factors, you can navigate the implementation process with confidence and make informed decisions to optimize your data workflows.
In the end, DBT materializations are like magical artifacts, empowering you to unlock the true potential of your data. They provide shortcuts, speed, and efficiency, enabling you to focus on gaining valuable insights rather than getting lost in complex calculations.
So, as you embark on your data journey, remember to harness the power of DBT materializations wisely. Tailor your approach to fit your unique needs, consider the trade-offs, and test your implementations diligently. With DBT materializations by your side, you can transform your data transformations into a seamless, enchanting experience. We will come up with more such use cases in our upcoming blogs.
Meanwhile…
If you are an aspiring Snowflake enthusiast and want to explore more about the above topics, here are a few of our blogs for your reference:
Stay tuned to get all the updates about our upcoming blogs on the cloud and the latest technologies.
Keep Exploring -> Keep Learning -> Keep Mastering
At Workfall, we strive to provide the best tech and pay opportunities to kickass coders around the world. If you’re looking to work with global clients, build cutting-edge products, and make big bucks doing so, give it a shot at workfall.com/partner today!


