Just an illustration – not the truth and you certainly can do it with other technologies.
TL;DR
After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality.
- the selfserve platform based on a serverless philisophy (life is too short to do provisioning)
- the building of data products (as code) : we are building data workflows not data pipelines
- the promotion of data domains where the metadata on the data life cycle is as important as your data
- The old data governance should become a data governance-as-code (DataGovops) to scale
In the previous episode
It was very focus on the organisation and data teams. We set the stage with 3 team topologies :
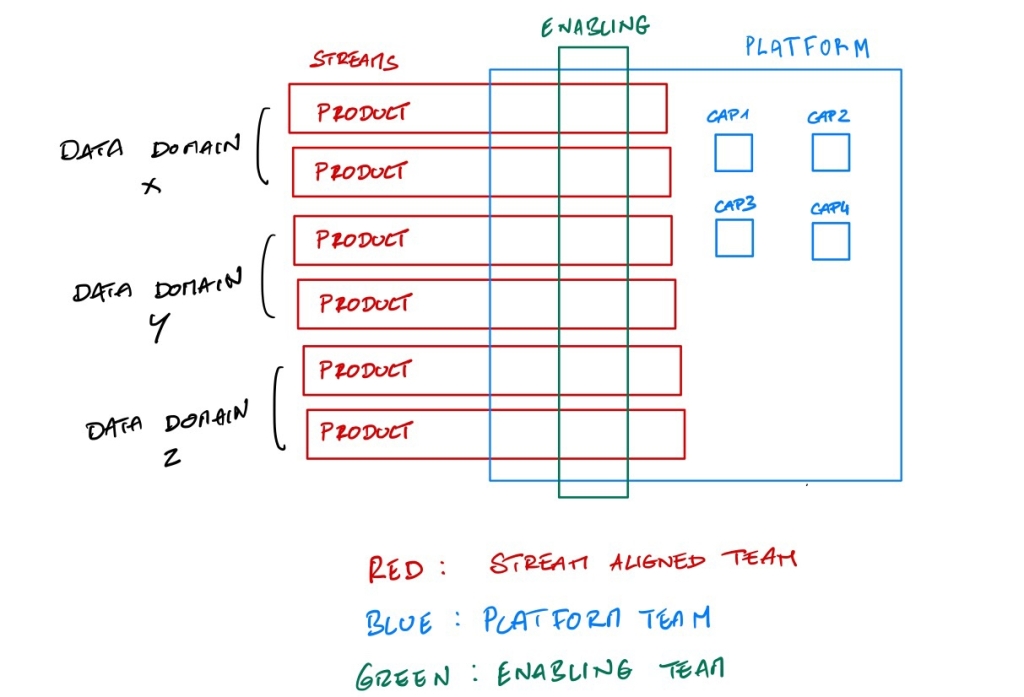
- We have independant stream aligned teams organized by data domain teams building data products
- We have a platform team building “data services as a platform” to ease the life of the stream aligned teams
- We have the enabling team to handle / facilitate subjects like Data Governance
The next step is how from a technology point of view :
- How about the self serve platform ?
- How do we build data products ?
- How can we interoperate between the data domains ?
- How do we govern all these data products and domains ?
It will be illustrated with our technical choices and the services we are using in the Google Cloud Platform. There are certainly many other ways to do the same with another technologies. More than the technology chosen, it is more interesting to talk about the spirit behind these choices.
1. The self-serve data platform or the “serverless way of life”
In this article “How to move beyond a Monolithic Data Lake to a distributed Data Mesh” Zhamak Dehghani describes in the introduction the 3 data platform generations (the data warehouse, the data lake and the data lake but in the cloud “with a modern twist”). With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services.
To illustrate that, let’s take Cloud SQL from the Google Cloud Platform that is a “Fully managed relational database service for MySQL, PostgreSQL, and SQL Server”. It looks like this when you want to create an instance. You can choose your parameters like the region, the version or the number of CPUs.
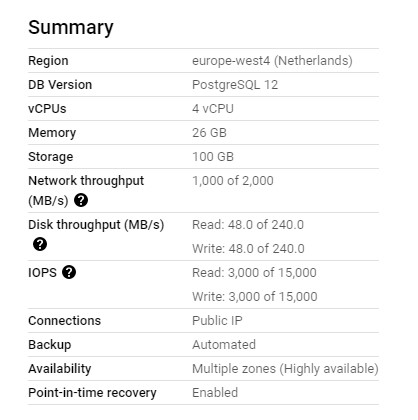
It looks nice but it is really not ! This is really the dark side of the data. As soon you have started to think about the server configuration, you are starting to lock yourself. And in a Data Mesh organisation, you will have “mini” platforms for each independant team. The next problem will be the diversity of these mini data platforms (because of the configuration) and you even go deeper in problems with managing different technologies or version. You are starting to be an operation or technology centric data team.
To get out of this, you have to move to another stage : the serverless stage.
In this stage, you will never think about the configuration. If you look at the BigQuery service (the cloud data warehouse in the Google Cloud Platform), you can start to write, transform and query your data without any provisioning. This is really for us the definition of a self serve platform.
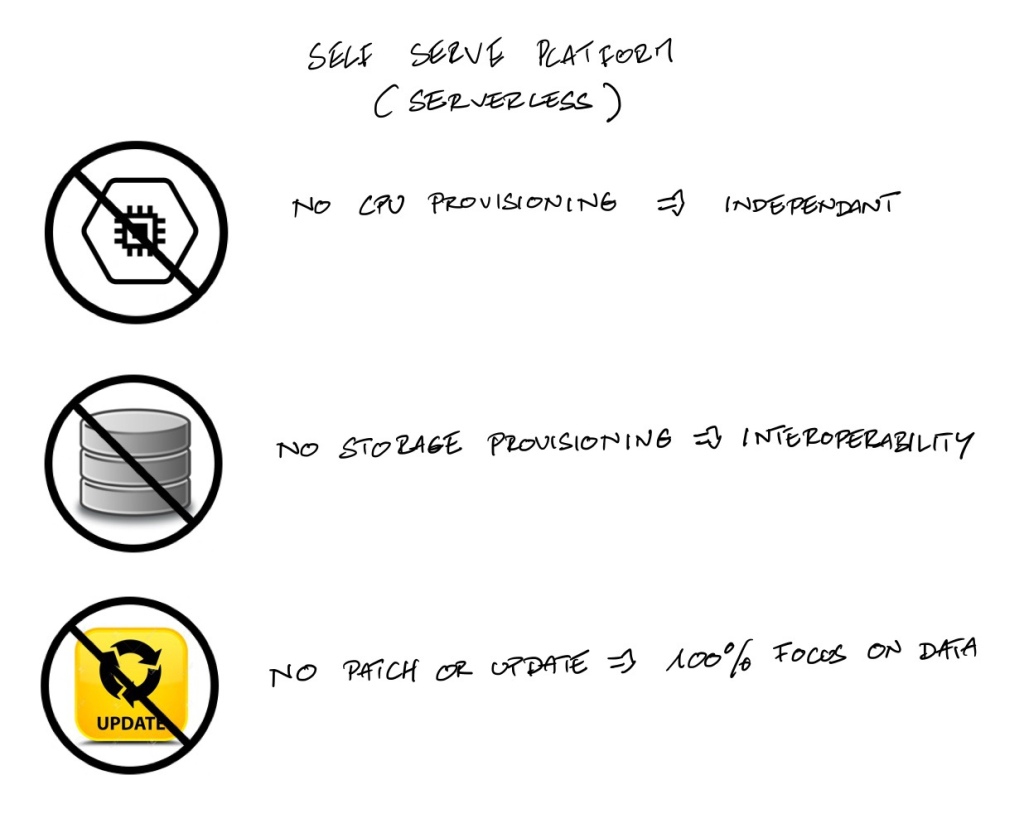
It is not only a technical debate on what is more powerful or not, it is a choice in your priorities. The “serverless way of life” is where you do not need to manage or think about the capacity of the insfrastructure even if it is managed for you. We want everything Serverless (and we can be extreme with that by eliminating many technologies) because :
- We want every teams to be as independant as possible versus we have to do some provisioning for the compute.
- We want interoperability for any data stored versus we have to think how to store the data in a specific node to optimize the processing.
- We are Data Teams versus we have to patch the server with the latest version and do the tests.
2.How to build Data Products or never call me Data Pipeline any more
You have this interesting schema in her second article on Data Mesh by Zhamak Dehghani : “Data mesh introduces the concept of data product as its architectural quantum. Architectural quantum, as defined by Evolutionary Architecture, is the smallest unit of architecture that can be independently deployed with high functional cohesion, and includes all the structural elements required for its function.”

- Code : all the code necessary to build a data product (data pipelines, API, policies). Data As Code is a very strong choice : we do not want any UI because it is an heritage of the ETL period. We want to have our hands free and be totally devoted to devops principles.
- Data & Metadata : the data of the data product in many possible storages if needed but also the metadata (data on data)
- Infrastructure : you will need compute & storage but with the Serverless philisophy, we want to make it totally transparent and stay focus on the first two dimensions.
As you can see, this is in the code part where you are building your data pipelines, a misnomer because this is an over simplification.

The proper term should have been “Data Workflow” because a workflow is not linear : you have conditions and many different steops. When I first saw this graphic presenting Google Cloud Workflows (their latest service to manage workflows), it was obvious “This is what a data engineer should do !”. He/She is managing triggers, he/she needs to check conditions (event type ? is safe ?) and he/she has different actions to execute (reading, calling a vision API, transform, create metadata, store them, etc…). What you have to code is this workflow !
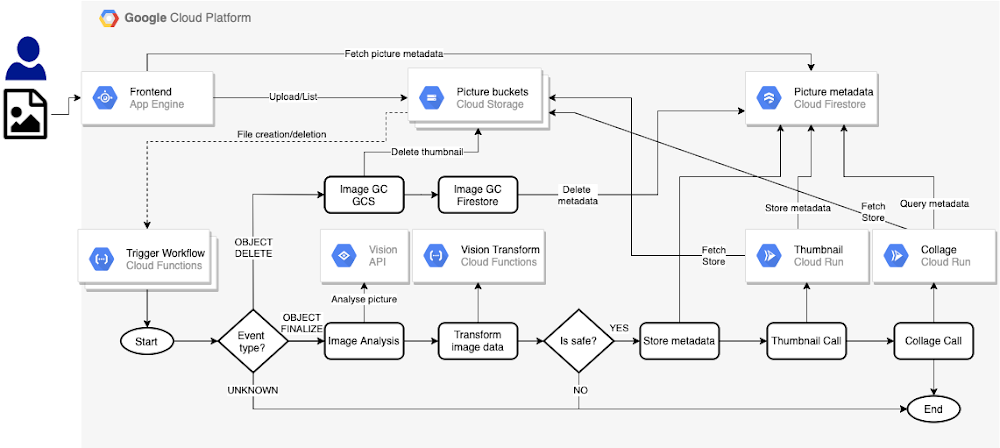
The beauty of using this serverless service is that you can really “call” any block you need (all serverless too – no infrastructure provisioning) like a Lego game. The other benefit is you can also use parameters and build a generic workflows to be re-used. You will be able to make some improvements and it will be applied to every data workflows using this generic / template workflow.
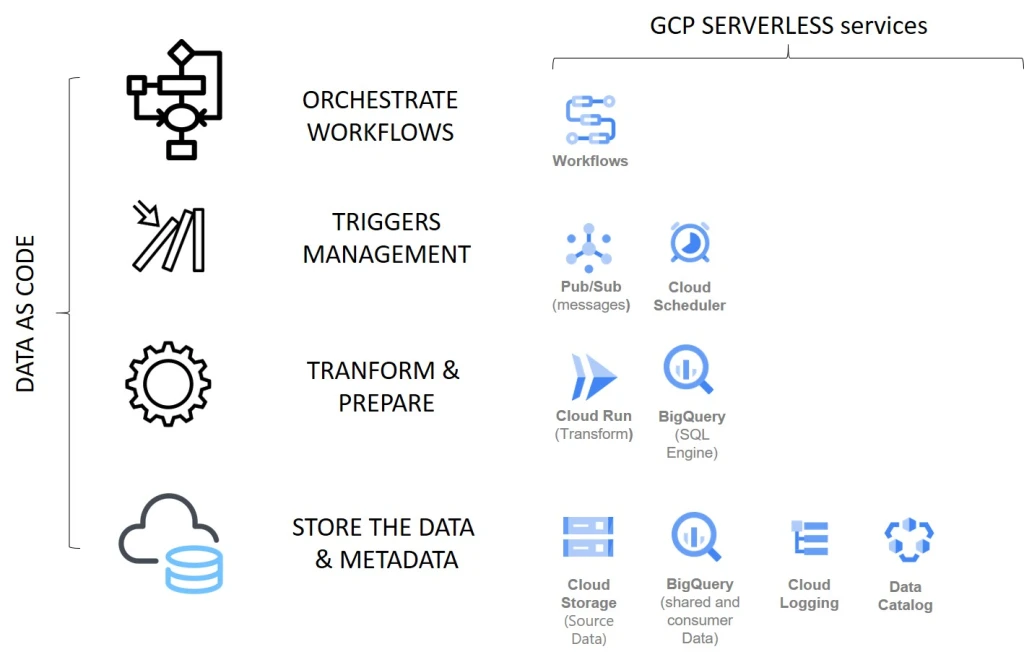
And of course, because everything is code, you have all the devops tools. This is the only way to best fast and still deliver quality. It is a huge shift in skills needed (will talk about that in part 3) but this is the only way to fully “accelerate” (like the title of this book where devops is a key part). Below, this is the list of all the most serverless services used for building data products.
3.Data Domains interoperability or Data Domains development of usage ?
In my previous article, I got this comment about the fact that data domains could become data silos managed by functional departement focusing only on their needs. And more precisely, the concern was about data like “products” or “customers” where you need to have a transversal approach. The way you have designed your data domains could help to handle the problem but at the end we should be very focus on the level of usage and the way these data domains interact together.
The core idea of Data Mesh is how you can develop the data usages and remove the centralized and monolitich data warehouse where you have very less access.
In her first article, Zhamak Dehghani has this very powerful graphic
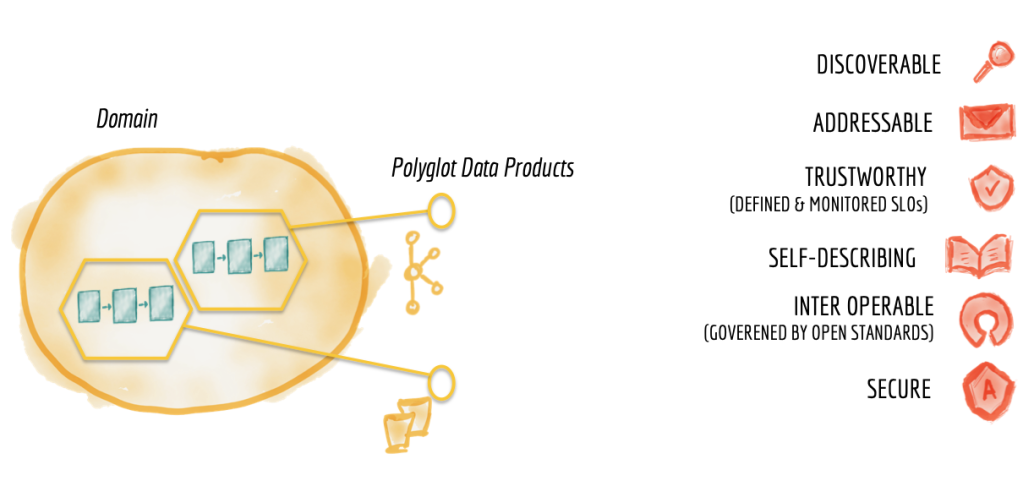
You have 6 “rules” to be compliant with if you are building data domain and data as a product. If you look at it closely, all these 6 attributes are one common goal : develop usages
- Discoverable : it helps to know what exists and what can use (aka Data Catalog)
- Addressable : the adress and location of every data asset
- Trustworthy : the data asset is monitored to know if we can use it
- Self-Describing : well documented with examples
- Inter operable : meaning you can cross different datasets together
- Secure : the access management is defined so you can have users
We don’t need just the data but all the metadata to be able to use this data. In this excellent article, Prupalka explains that “We’re fast approaching a world where metadata itself will be big data”.
To be precise, we don’t need every metadata but we need all the metadata throughout the data life cycle and how you have the right exposition to develop interactions and usages.
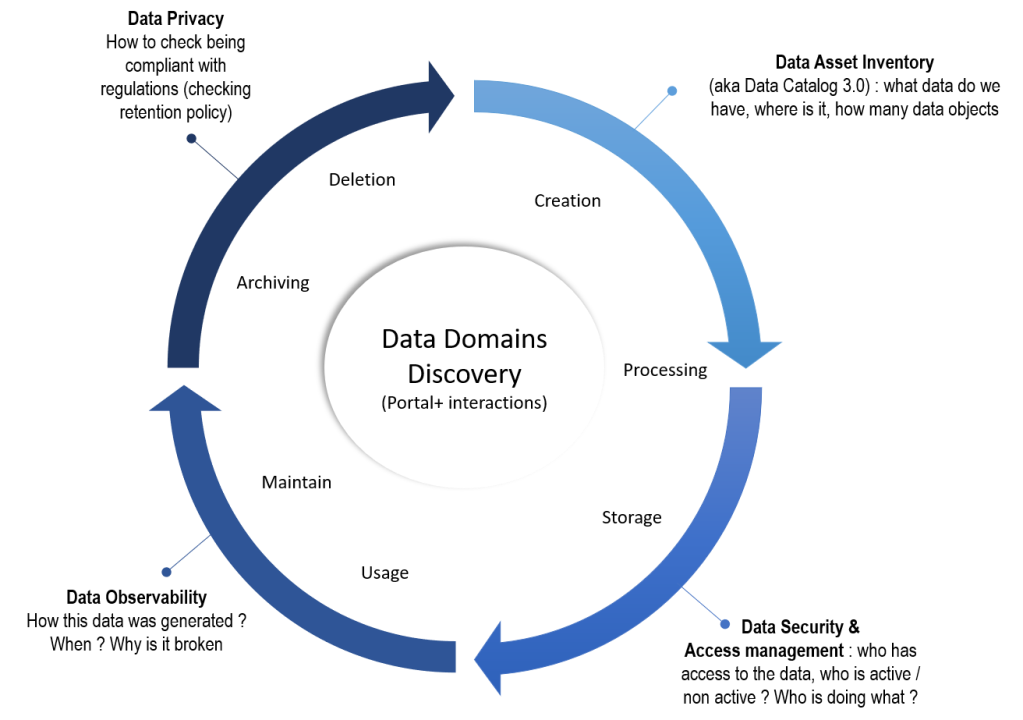
- At the center, you have a portal for the discovery of data domains : this is the place to find everything about your data (a solution bought that we will personalize and fuel with the relevant metadata)
- Data Asset Inventory : a more suitable term than just data catalog, this is all the data related to the creation of a data object. It gives an anwser to what do we have , where is the data (its address) how many objects do we have ?
- Data Security & Access management : who has access to this data ? who are our active users ? who are our non active users ? Who is doing what ?
- Data Observability : How this data was generated (lineage) ? When was it generated ? Why is it broken ?
- Data Privacy : to illustrate that you have to archive your data when needed (right to oblivion for example)
The portal (Data Domain Discovery) is the accelerator to develop transparency and the promotion of each data domain and at the end the usage of each data domain. This is also where you can calculate KPI about the usages and check the level of interoperability and usage of each data domain. I see a good orientation if we can really measure the success of these data domains based on the level of usage. It will re-inforce the data as a product approach.
4.Federated Computational Governance or Automated Governance-As-code (DataGovOps)
In her second article, Zhamak Dehghani defines the governance like this (one of my favorite part ) ” a data mesh implementation requires a governance model that embraces decentralization and domain self-sovereignty, interoperability through global standardization, a dynamic topology and most importantly automated execution of decisions by the platform“.
Automatize or have your Data Governance policies by default is the only solution to cope with 3 factors :
- the increase of data volume and more kinds of data (like photos, sounds, videos)
- more users if you want to develop the usage
- new regulations every day
if not the volume of work is too important and you will have to prioritize subjects like regulation. The data security can be chaotic and the visibility and control is drowned in a (data) lake.
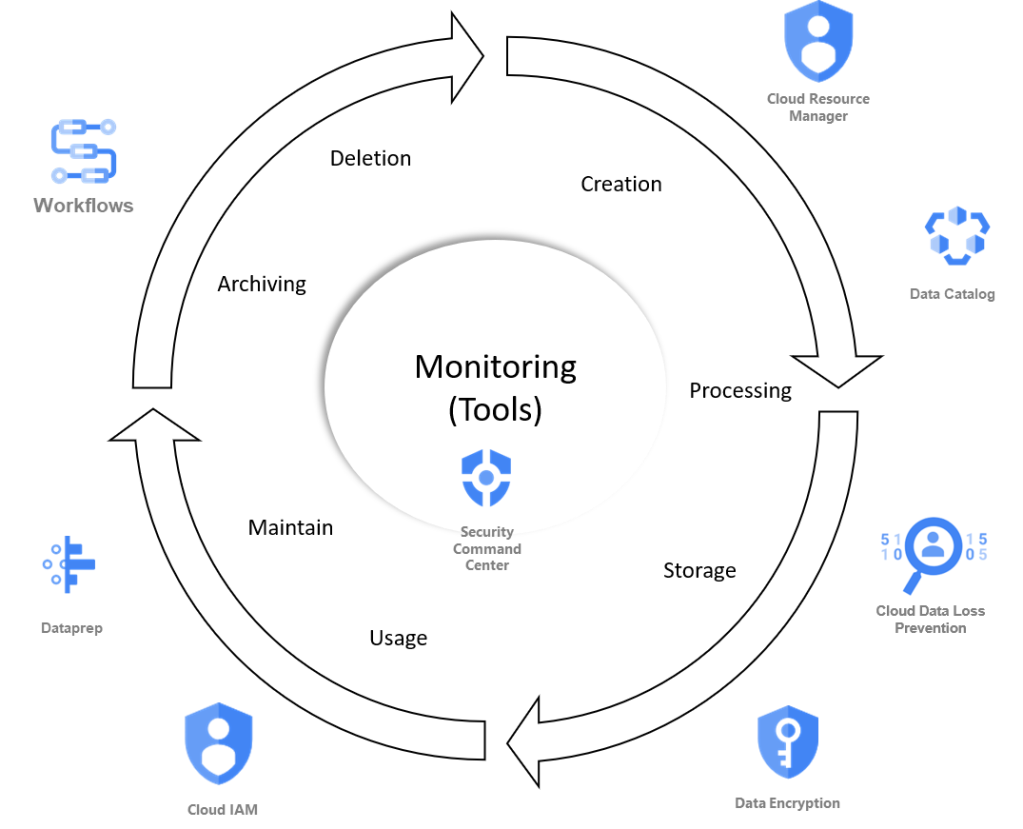
The number of subjects to automatize is not short.
- Creating the project or space for each data domain to collect or transform the data : each data domain is always coming with the right services and the same security heritage.
- Data Cataloging for each new data using templates to collect all the needed metadata : each dataset has the same template with the same metadata created by data product as code.
- Classification of this data to be able to apply the right policies (security, protection, retention, etc..) : especially for sensitive data to detect them
- Users creation and Access management : ideally, the rights are defined based on attributes coming from the referential of your users
- Data Protection (encryption, key management) : all data store and in transit are encrypted with a key rotation
- Data profiling : How to assess the profil of each column for each table to be able to detect if something has changed
- Data quality : how to apply data quality check automatically based on business rules ?
- Data Lineage : every data produced can be analyzed (by column and row) to understand their origin.
- Data retention and deletion : How to be compliant with regulations without doing any manual tasks ?
- and the most important one Data Monitoring (including alerting and automatic actions) : if there is a suspect export of data, the task is terminated based on rules before ending.
We have 3 kinds of automation :
- By default : services like data encryption is a good example, you have a default mode where data is automatically encrypted.
- Configuration with a cloud service : Google Cloud DLP can detect 120 infotypes but you have to configure it and define what will be the actions
- Fully custom made with code : data lineage can be a full custom made based on steps included in the code to trace the different steps and transformations.
This is here you need a platform team (for automation) and the enabling team (to make the link with data governance) to manage these topics : these teams will work on automatizing every step of the data life cycle to enforce the data governance policies. For each subject, this team will have more and more anwsers on how to automatize it. you will find a list of services we are using in the Google Cloud Platform (I am sure you will find the same services in any cloud provider more or less)
- Ressource Manager to centrally manage all your projects and heritage rules
- Data Catalog : more a central to manage your medata and your different templates
- Cloud Data Loss Prevention : not yet activated but will be to detect sensitive infotype for regulations
- Identity and Access Management : used together with BigQuery and the data Catalog, the hardest part will how to automatize the policy attached to each data
- Encryption at rest and in transit : part of the the security in the GCP
- Data profiling with Google Cloud Data Prep is today our main option to study to automatize this task
- Data quality : will be a mix between our data discovery portal (to collect the business rules) and transform them to data quality rules to be executed using Cloud Data Prep for example (a possible choice to study)
- Data Lineage will be certainly a full custom made but based on decoding the code used in Google Cloud Workflows
- Data retention & deletion : should be guided by the data discovery portal and the data domain owner, we will have to define automatic jobs to apply the policy. We could define data workflows to do this task
- Monitoring : we will have our own tools but we are also looking Security Command center center to automatize remediation
We have still a lot of work to do but you have an idea on how do we consider automatizing the data governance.
Conclusion
At first, when you are reading the two articles on Data Mesh by Zhamak Dehghani, you have your attention on the idea of distributed data domains vs the monolithic Data Lake and data as a product. But in this “revolution”, you have another one with the self serve platform for each data domain, the architectural quantum of a data product and the computational policies embedded in the mesh. These 3 components are the “How” you need to move toward a data mesh. It is a huge shift and I will talk about the change management part and the skills needed in part 3.
