
Data Journey First DataOps
Putting Problems in Your Data Estate at the Forefront
Welcome to the high-octane world of DataOps, a powerhouse that turbocharges data analytics development and management. This innovative approach merges the agility of Agile Development, the stability of DevOps, and the meticulousness of Statistical Process Controls to enable a dynamic, enriched, and nimble data ecosystem that is truly remarkable.
Historically, automation has taken center stage in the theater of DataOps. But as we navigate ever-evolving seas of data, it’s high time we reset our course. We must adopt a pioneering and exceptionally effective strategy—where we prioritize the intricacies and nuances of the ‘Data Journey’ even before we approach automation.
Welcome to the dawn of a transformative approach—which we proudly call ‘Data Journey First DataOps.’ This is not just an approach; it’s a revolution in which every data, tool, server, and step becomes part of a meaningful story, enhancing our data initiatives’ overall value, impact, and trust.
The Why and How of ‘Data Journey First DataOps’
Let’s start with the ‘why.’ Businesses today are under more pressure than ever. With growing data demands and shrinking timelines, data analytic teams need value delivered quickly without radically altering their established systems. The initial heavy lifting often involved in full DataOps automation might be too time-consuming and disruptive.
| Lots Of Blame And Shame | Teams are panicked when customers find problems and spend time, without a shared context, trying to determine who is responsible. |
| Data Teams Already Have A Ton of Things To Get Done. | Teams are already busy and stressed and need to meet customer expectations. |
| Teams Did Not Build Current Architecture For Rapid And Low-Risk Changes Those Systems | Teams have complicated in-place data architectures and tools and fear changes to what is already running. Any change to production takes time because a lack of automation is hazardous. |
| Constant Data And Tool Errors In Production | Teams cannot see across all tools, pipelines, jobs, processes, datasets, and people. As a result, their customers tell them when there is a problem. |
| No Time For Data Validation Testing | Teams must learn what, where, and how to check raw, integrated, or ‘data in use’ to ensure the correct outputs. |
Obstacles to Automation in Your Data Operations
Enter ‘Data Journey First DataOps.’ The idea here is to focus first on understanding and observing the journey that data takes through your production environment – from ingestion to processing to delivering actionable insights. This monitoring process identifies data errors, tool problems, and timing issues, enabling a quick win for your DataOps implementation by driving immediate improvements. Lowering production errors increases the reliability of your data and gives your team more time to focus on automation. And all this has to happen in days, not months. There are only five pillars that define what teams need to get value quickly, with little work, and without significantly changing what they already have working in production.
Data Journey First DataOps: An Overview
The first step in DataOps isn’t implementing DataOps automation techniques or deploying cutting-edge data management platforms. Instead, it focuses on a humble yet pivotal element – lowering errors in your production Data Journey. The term ‘Data Journey First DataOps’ encapsulates this philosophy.
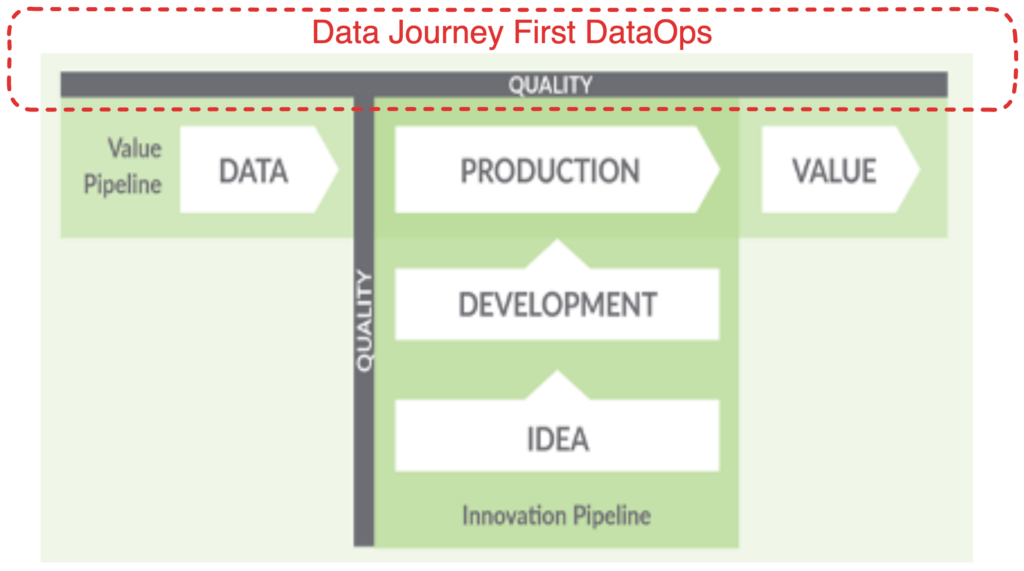
DataOps Concept: Data Journey at the Forefront
Observing Production Data Journeys: This step involves a deep and continuous understanding of your production data estate. Actively monitoring the entire Data Journey goes beyond the static Data Lineage of where your data originates and where it lands. It adds the dynamic understanding of how your data flows, transforms, gets enriched, and is consumed. It allows you to trust through active verification. By observing these Data Journeys comprehensively and actively, you can detect problems early, streamline your processes, and make informed decisions.
Lower Errors in Production: A keen focus on the Data Journey helps to pinpoint errors, inconsistencies, and delays in your production data, tools, and deliverables. Data engineers can lower error rates in production by identifying these issues early and resolving them swiftly, improving the overall quality of data and, thereby, the reliability of insights derived from the data.
Creating Time for Automation in Step Two: By prioritizing your Data Journey, you allow your team to address the fundamental issues affecting your data estate before moving to the second step – automation. This sequence ensures your team can leverage automation more effectively when the time comes.
Automation Second DataOps: The Next Step
Once we’ve established stable, fully observed Data Journeys, we can move onto the second stage: ‘Automating DataOps.’ The first, second, and third pipelines of DataOps automation come into play, designed to increase productivity and reduce cycle times.
- Meta-Orchestrate Your Production Pipelines to organize your entire data analytics toolchain.
- Automate Your Deployment Pipelines for fast and fearless development.
- Automate Your Environment Pipelines for reusability, security, and developer speed.
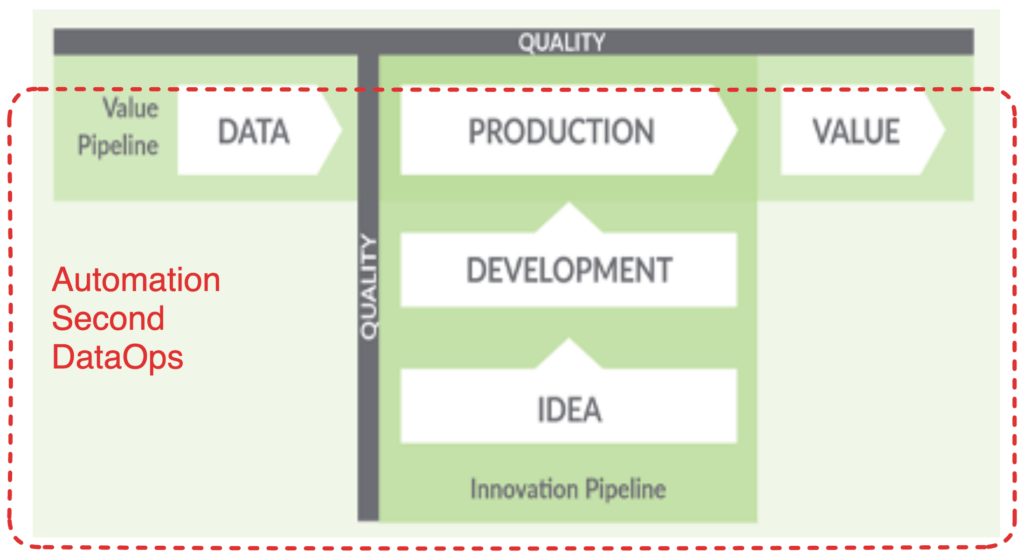
DataOps Automation Second Concept: Environments, Deployment, and Production.
Automated DataOps significantly enhance cycle times. It accelerates your ability to make small, low-risk changes to production data systems, enables quicker decision-making, and boosts productivity by freeing data teams to focus on learning through rapid iterations. But remember, this step can be practical only when it builds upon the groundwork laid by ‘Data Journey First DataOps.’
Benefits Of Data Journey First DataOps
Choosing a Data Journey first approach to DataOps is essential because:
It’s easy and fast to get done.
Most data teams are often overwhelmed with tasks and have pressing customer needs. They need valuable, quickly implemented DataOps solutions without drastically changing what they already have. Implementing a Data Journey is the first step.
It minimizes disruption of your existing ‘as-built’ data estate.
As-built data and analytic systems have many steps to prepare for full-fledged DataOps automation. Teams have rushed to get a production solution in place without adequate investment in deployment pipelines, environment management, and orchestration of their production pipelines. These gaps result in the need for solutions that address the primary pain points without causing significant disruption.
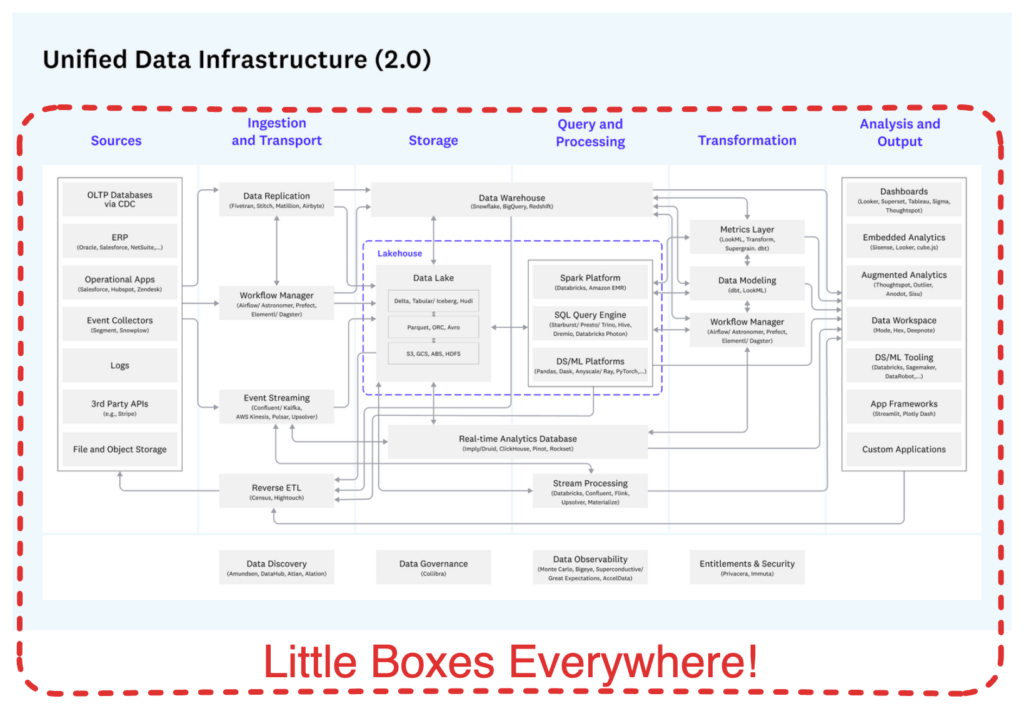
Aren’t you tired of seeing architectural diagrams composed of little boxes everywhere? (credit a16z)
No analytic customer ever said, ‘I want more data errors’ in my Data Journey!
22% of data engineers’ time is spent on innovation, but 78% on errors and manual execution (Gartner 2022). An Eckerson survey found that over 79% of projects have too many errors.
Addressing this challenge delivers a big chunk of the value of adopting DataOps.
Most organizations want their first DataOps projects to deliver significant value fast with a small effort and minimal changes to existing operations. Data Journeys are fast and easy to implement.
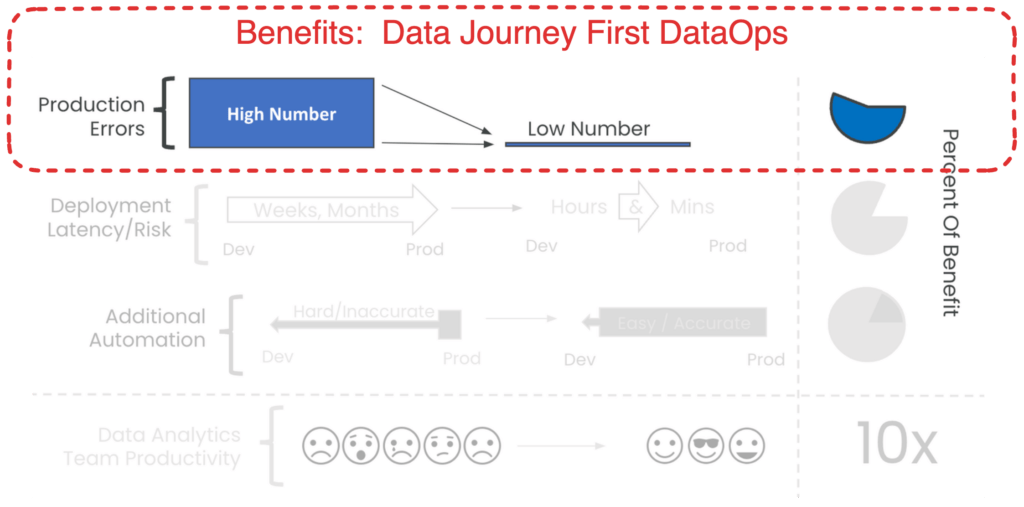
Reducing production errors delivers a large portion of the overall value of DataOps.
It lowers your team’s stress to make more fundamental changes.
A recent survey of 700 data engineers by DataKitchen & Data.world in 2022 found that 52% of Data Engineers said errors are a significant source of burnout. Data engineers deal with hundreds of data sets and diverse customer needs. They have backlogs on their daily task lists. So they don’t have time or energy to learn about each data set or customer to create robust production data validation tests. The entire Data Journey is invisible to them. They need help creating data tests and observing the entire Data Journey for success.
It lays the data validation and testing groundwork to improve deployment cycle time.
In a world of complexity, failure, and frustration, data and analytics teams need to deliver insight to their customers with no errors and a high rate of change. They must deploy small changes, new data sets, new tools, and updated code to production quickly and with low risk. From initiating a data analytics task to its completion and deployment, cycle time is a critical metric affecting an organization’s ability to generate insights and make data-driven decisions. A shorter cycle time enables a more agile decision-making process and allows organizations to capitalize on emerging trends or opportunities. Testing, observing, and monitoring production Data Journeys provides testing and exception monitoring capabilities that can be used to improve deployment.
In Conclusion
Data Teams often need more. They desire quick, valuable assistance without significantly changing their existing systems. The ‘Data Journey First DataOps’ approach aligns perfectly with these needs.
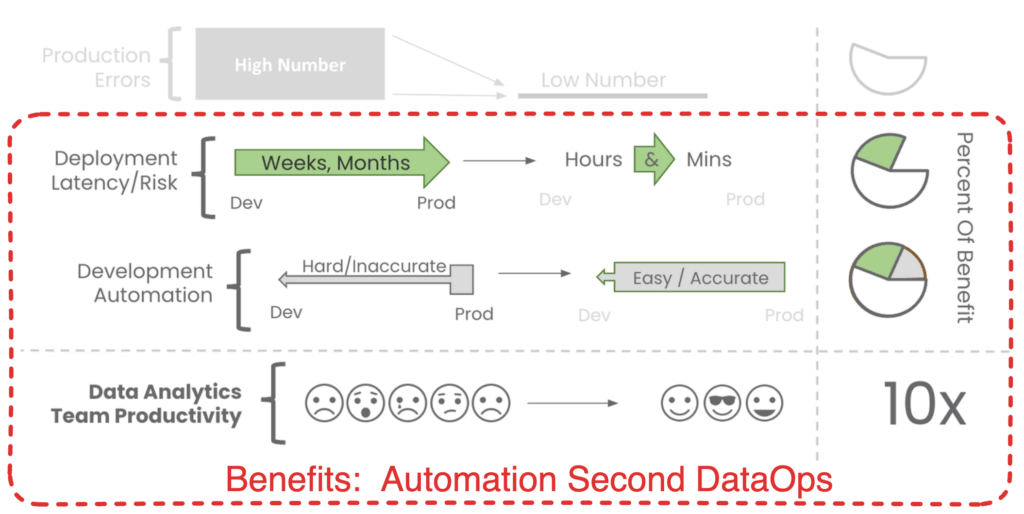
Automation gives a portion of the overall benefits of DataOps.
‘Data Journey First DataOps’ is a philosophy that acknowledges the current constraints of data and business teams and proposes a solution that offers rapid, substantial value. Whether you’re ‘Leading with Data Journey,’ ‘Prioritizing Data Journey,’ or simply ‘Putting Data Journey First in DataOps,’ remember that the goal is to deliver quick wins today while laying the foundation for a more robust, automated data operations landscape tomorrow. The first successful DataOps implementation is all about quick wins to lower errors and creating foundational elements for the next improvement phase, automating DataOps.
For more information on Data Journey Ideas and Background, see
- Data Journey Manifesto https://datajourneymanifesto.org/
- Why the Data Journey Manifesto? https://datakitchen.io/why-the-data-journey-manifesto/
- Five Pillars of Data Journeys https://datakitchen.io/introducing-the-five-pillars-of-data-journeys/




