Data Pipeline with Airflow and AWS Tools (S3, Lambda & Glue)
Learning a little about these tools and how to integrate them
Introduction
A few weeks ago, while doing my mental stretch to think about new post ideas, I thought: Well, I need to learn (and talk) more about cloud and these things, I’ve practiced a lot on on-premise ambients, using open-source tools, and running away from proprietary solutions… But the world is cloud and I don’t think that this is gonna change any time soon…
I then wrote a post about creating a data pipeline with local Spark and GCP, my first one using cloud infrastructure. Today’s post follows the same philosophy: fitting local and cloud pieces together to build a data pipeline. But, instead of GCP, we’ll be using AWS.
AWS is, by far, the most popular cloud computing platform, it has an absurd number of products to solve every type of specific problem you imagine. And, when it comes to data engineering solutions, it’s no different: They have databases, ETL tools, streaming platforms, and so on — a set of tools that makes our life easier (as long as you pay for them).
So, join me on this post to develop a full data pipeline from scratch using some pieces from the AWS toolset.
not sponsored.
The tools — TLDR
Lambda functions are AWS’s most famous serverless computing solution. ‘Serverless’ means the application is not attached to a particular server. Instead, whenever a request is made, a new computing instance is quickly initiated, the application responds, and the instance is terminated. Because of this, these applications are meant to be small and stateless.
Glue is a simple serverless ETL solution in AWS. Create Python or Spark processing jobs using the visual interface, code editor, or Jupyter notebooks. Run the jobs on-demand and pay only for the execution time.
S3 is AWS’ blob storage. The idea is simple: create a bucket and store files in it. Read them later using their “path”. Folders are a lie and the objects are immutable.
Airflow is a ‘workflow orchestrator’. It’s a tool to develop, organize, order, schedule, and monitor tasks using a structure called DAG — Direct Acyclic Graph, defined with Python code.
The Data
To properly explore the functionalities of all these tools, I’ve chosen to work with data from the Brazillian ENEM (National Exam of High School, on literal translation). This exam occurs yearly and is the main entrance door to most public and private Brazilian universities; it evaluates the student in 4 great areas of knowledge: Human Sciences; Natural Sciences; Math and Languages (45 questions each).

Our task will be to extract these questions from the actual exams, which are available as PDFs on the MEC (Ministry of Education) website [CC BY-ND 3.0].

The Implementation
After reading one line or two about the available data processing tools in AWS, I chose to build a data pipeline with Lambda and Glue as data processing components, S3 as storage, and a local Airflow to orchestrate everything.
Simple idea, right?
Well, sort of.
As you will note through this post, the problem is that there are a lot of configurations, authorizations, roles, users, connections, and keys that need to be created to make these tools work together nicely.
I promise that I’ll try to cover the steps as most as I can, but I’ll need to cut off some details to make a shorter post.
With that said, let’s have a look at each tool’s function, see the figure below.
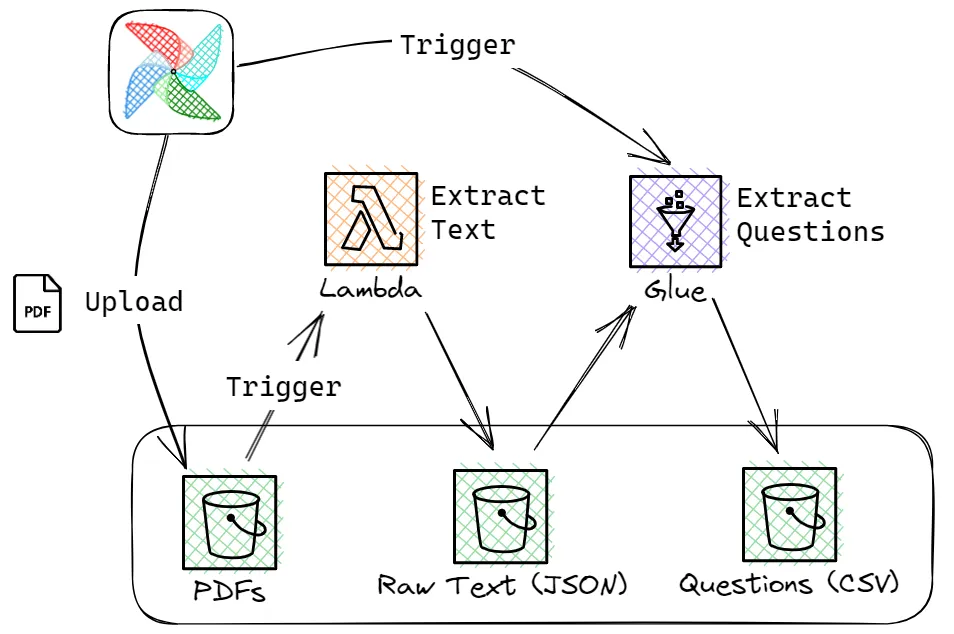
The local Airflow instance will orchestrate everything, downloading the PDFs from the MEC website and uploading them to S3. This process should automatically trigger a Lambda Function execution, which will read the PDF, extract its text, and save the result in ‘another place’ of S3. Airflow should then trigger a Glue Job that will read these texts, extract the questions, and save the results in CSV to S3.
In steps:
- (Airflow) Download the PDF and upload it to S3
- (Lambda) Extract the text from the PDF, writing the result in JSON to S3
- (Airflow->Glue) Read the text, split the questions, add the proper metadata, and save the results in CSV
0. Setting up the environment
All the code used in this project is available in this GitHub repository.
The first step is to configure the local environment.
You will need Docker installed on your local machine to create the Airflow cluster. The docker images are already configured to automatically create a new environment from scratch, so we can focus more on the implementation.
On the same folder of the docker-compose.yaml file, start the environment with:
docker compose upAfter the initial configuration, the airflow web service should start at localhost:8080. The default user and password are both ‘airflow’.
If you run into problems while starting Airflow, try to give read and write permissions to the newly created volumes, ex: chmod 777 <foldername>.
Moving on to the cloud environment.
You’ll need an AWS account, and here is a warning — watch out for the bills. The S3 storage and Lambda functions uses will be under the free quota (if you have not already spent it), but the Glue executions will charge you a few USD cents. Always remember to shut down everything when the work is finished.
Once you have created the account, follow the steps:
- Create a new Bucket in S3 called enem-bucket.
- Create a new IAM user with authorization to read and write to S3 and run Glue Jobs, store the access key pair generated.
- In the airflow UI (localhost:8080), under the admin->connections tab, create a new AWS connection, named AWSConnection, using the previously created access key pair.

Some other minor tweaks may be needed, AWS is a crazy place, but the list above should cover the overall process.
Once a man ate an entire airplane. The secret is that the process took 2 years and he ate it piece by piece. Take this philosophy with you along this post. The next sections will detail the implementation of each pipeline piece and, one by one, we will build the full project.
1. Uploading files to AWS using Airflow
First, create a Python file inside the /dags folder, I named mine process_enem_pdf.py. This is the default folder where Airflow searches for dags definitions. Inside the script, import the following dependencies:
# import airflow dependencies
from airflow import DAG
from airflow.models import Variable
from airflow.operators.python_operator import PythonOperator
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from airflow.providers.amazon.aws.hooks.base_aws import AwsGenericHook
from datetime import datetime
import requestsIn a real scenario, a web scraping application would search the PDFs’ download links on the MEC page but, for simplicity, I collected the links manually (there are not so many) and hard-coded them in a dictionary.
LINKS_ENEM = {
"2010_1":'https://download.inep.gov.br/educacao_basica/enem/provas/2010/dia1_caderno1_azul_com_gab.pdf',
"2010_2":'https://download.inep.gov.br/educacao_basica/enem/provas/2010/dia2_caderno7_azul_com_gab.pdf',
"2010_3":'https://download.inep.gov.br/educacao_basica/enem/provas/2010/AZUL_quarta-feira_GAB.pdf',
"2010_4":'https://download.inep.gov.br/educacao_basica/enem/provas/2010/AZUL_quinta-feira_GAB.pdf',
"2011_1":'https://download.inep.gov.br/educacao_basica/enem/provas/2011/01_AZUL_GAB.pdf',
"2011_2":'https://download.inep.gov.br/educacao_basica/enem/provas/2011/07_AZUL_GAB.pdf',
"2011_3":'https://download.inep.gov.br/educacao_basica/enem/ppl/2011/PPL_ENEM_2011_03_BRANCO.pdf',
# OMITTED TO MAKE THIS CODE BLOCK SMALLER
# ...
}Always be responsible when planning to create a web scraper: check the site’s terms of use and the hosted content copyright.
To better simulate the behavior of a scraping application, I’ve also created a ‘year’ variable in the Airflow UI (admin->variables). This variable simulates the ‘year’ when the scraping script should execute, starting in 2010 and being automatically incremented (+1) by the end of the task execution. This way, each task run will only process data from one year.

Airflow variables and connections are referenced inside the code using their ID (name). I usually put their names as constants:
# Connections & Variables
AWS_CONN_ID = "AWSConnection"
YEAR_VARIABLE = "year"The most common way of executing Python code inside Airflow DAGs is using the PythonOperator, which creates a task based on a Python function.
Because of this, the process of downloading the PDF and uploading it to the S3 bucket needs to be wrapped inside a function. See below.
AWS_CONN_ID = "AWSConnection"
YEAR_VARIABLE = "year"
def download_pdfs_from_year(
year_variable,
bucket
):
# Create a S3 connection using the AWS Connection defined in the UI
conn = S3Hook(aws_conn_id=AWS_CONN_ID)
client = conn.get_conn()
year = Variable.get(year_variable)
year_keys = [key for key in LINKS_ENEM.keys() if year in key]
for key in year_keys:
print(f"Downloading {key}")
url = LINKS_ENEM[key]
r = requests.get(
url,
allow_redirects=True,
verify=False
)
client.put_object(
Body=r.content,
Key=f"pdf_{key}.pdf",
Bucket=bucket,
)
# increase the year
year = str(int(year)+1)
Variable.set(year_variable, year)Now, it’s just a matter of instantiating the DAG object itself:
# Some airflow boilerplate and blah blah blah
default_args = {
'owner': 'ENEM_PDF',
'depends_on_past': False,
'start_date': datetime(2021, 1, 1),
}
dag = DAG(
'process_enem_pdf_aws',
default_args=default_args,
description='Process ENEM PDFs using AWS',
tags=['enem'],
catchup=False,
)And writing the tasks:
with dag:
download_pdf_upload_s3 = PythonOperator(
task_id='download_pdf_upload_s3',
python_callable=download_pdfs_from_year,
op_kwargs={
'year_variable': YEAR_VARIABLE ,
'bucket': 'enem-bucket',
},
)The DAG will be visible in the Airflow UI, where we can activate it and trigger executions:

And here is (the first) moment of truth, trigger the dag and watch the S3 Bucket. If all goes well, the PDFs should appear in the S3 bucket.

If not (which is likely, as things tend to go wrong in the technology field), start debugging the DAG logs and search for misconfiguration.

2. Extracting the PDF’s text using Lambda Functions
With the PDFs already being uploaded to S3, it’s time for the next step: extracting their texts.
This is a perfect task to implement using AWS Lambda Functions: A stateless, small, and quick process.
Just a recap of how this serverless thing works. In usual ‘server’ applications, we buy a particular server (machine), with a proper IP, where our application gets installed, and it stays up 24/7 (or something like that) to serve our needs.
The problem with using this approach to things like this simple text-extraction preprocessing task is that we need to build a full robust server from scratch, which takes time and may not be so cost-effective in the long run. Serverless technology has arrived to solve this.
In serverless, whenever a request is made, a new small server instance is quickly initiated, the application responds, and the instance is terminated.
It’s like renting a car vs taking a Uber to make a small 5 min trip.
Let’s get back to coding.
Search for Lambda in your AWS account and create a new lambda function in the same region as the S3 bucket used earlier, otherwise, it will not be able to interact with it using triggers (more on that later).

Create a new function from scratch, name it process-enem-pdf, choose Python 3.9 runtime and we’re good to go. AWS will probably instruct you on creating a new IAM role for Lambda Functions, make sure that this role has the read and write permissions in the enem-bucket S3 bucket.
You may also need to increase the function max execution time to around 3min, the default value is 3 seconds (or something close to it), which is insufficient for our purposes.
Python Lambda functions in AWS take the form of a simple Python file called lambda_function.py with a function lambda_handler(event, context) inside, where ‘event’ is a JSON object representing the event that triggered the execution.
You can edit the Python file directly on the AWS built-in IDE or upload a local file using a compressed zip folder.

And here things get a bit tricky.
To extract the text from the PDFs, we’re going to use the PyPDF2 package. However, installing this dependency in the AWS Lambda function environment is not as easy as running ‘pip install’.
We need to install the packages locally and send the code + dependencies compressed (zip) together.
To do this, make the following procedure:
- Create a Python virtual env with venv: python3 -m venv pdfextractor
- Activate the environment and install the dependencies
source pdfextractor/bin/activate
pip3 install pypdf2 typing_extensions3. Create a local lambda_function.py file with the lambda_handler function
import boto3
from PyPDF2 import PdfReader
import io
import json
def lambda_handler(event, context):
# The code goes here blah blah blah
# Detailed latter
# ...4. Copy the lambda_function.py to the pdfextractor/lib/python3/site-packages/ path.
5. Compress the contents of the pdfextractor/lib/python3/site-packages/ folder in a .zip file
6. Upload this file in the Lambda Functions UI
Now that you (probably) understand this process, we can move on to developing the code itself.
The idea is simple: every time a new PDF object is added to the S3 bucket, the Lambda function should be triggered, extract its text, and write the result to S3.
Luckily, we don’t need to code this trigger rule by hand, because AWS provides built-in triggers that interact with different parts of its infrastructure. In the process-enem-pdf page, click on add trigger.

Now, configure a new rule based on S3 …

Bucket: enem-bucket; Event types: All object create events; Suffix: .pdf
IT IS VERY IMPORTANT TO PROPERLY ADD THE SUFFIX. We’re going to use this function to write new files to this same bucket, if the suffix filter is not correctly configured, it may cause an infinite recursive loop that will cost you an infinite amount of money.
Now, every time a new object is created in the S3 bucket, it will trigger a new execution. The parameter event will store a JSON describing this newly created object, which looks something like that:
{
"Records": [
{
# blah blah blah blah blah
"s3": {
# blah blah blah blah blah
"bucket": {
"name": "enem-bucket",
"ownerIdentity": {
# blah blah blah
},
"arn": "arn:aws:s3:::enem-bucket"
},
"object": {
"key": "pdf_2010_1.pdf",
"size": 1024,
}
}
# blah blah blah
}
]
}With this information, the function can read the PDF from S3, extract its text, and save the results. See the code below.
import boto3
from PyPDF2 import PdfReader
import io
import json
def lambda_handler(event, context):
object_key = event["Records"][0]["s3"]["object"]["key"]
bucket = event["Records"][0]["s3"]["bucket"]["name"]
object_uri = f"s3://{bucket}/{object_key}"
if not object_uri.endswith(".pdf"):
# Just to make sure that this function will not
# cause a recursive loop
return "Object is not a PDF"
# Create a S3 client
# Remember to configure the Lambda role used
# with read and write permissions to the bucket
client = boto3.client("s3")
try:
pdf_file = client.get_object(Bucket=bucket, Key=object_key)
pdf_file = io.BytesIO(pdf_file["Body"].read())
except Exception as e:
print(e)
print(f"Error. Lambda was not able to get object from bucket {bucket}")
raise e
try:
pdf = PdfReader(pdf_file)
text = ""
for page in pdf.pages:
text += page.extract_text()
except Exception as e:
print(e)
print(f"Error. Lambda was not able to parse PDF {object_uri}")
raise e
try:
# Save the results as JSON
text_object = {
"content": text,
"original_uri": object_uri
}
client.put_object(
Body=json.dumps(text_object).encode("utf-8"),
Bucket=bucket,
Key=f"content/{object_key[:-4]}.json" ,
)
except Exception as e:
print(e)
print(f"Error. Lambda was not able to put object in bucket {bucket}")
raise eCreate this function and reproduce the deploy steps explained earlier (venv, zip and upload) and everything should work fine (probably). As soon as our airflow pipeline saves a new PDF to the bucket, its text should be extracted and saved as a JSON in the /content “folder” (remember, folders are a lie).

3. Processing the text using Glue
And we finally get to the final piece of our pipeline. The texts are already extracted and stored in a format that can be easily handled (JSON) by most of the data processing engines.
The final task is to process these texts to isolate the individual questions, and that’s where AWS Glue comes in.
Glue is a pair of solutions: a data catalog, with crawlers to find and catalog data and map schemas, and the serverless ETL engine, responsible for the data processing.
Search for Glue in the AWS console and select it.

Before writing a job, we’re going to create a new dataset in the data catalog using crawlers. Too many new concepts, I know, but the process is simple. On Glue’s main page, go to crawlers on the left menu.

Create a new crawler, give it a name in step 1, and move to step 2. Here, add a new data source pointing to the s3://enem-bucket/content, our ‘folder’ where all the texts are stored.

Move to step 3, creating a new IAM role if needed. Step 4 will ask you for a database, click on Add database and create a new one called enem_pdf_project. Review the info on step 5 and save the crawler.
You will be redirected to the crawler page. Now the danger zone (it will cost you a few cents ;-;), click on run crawler and it will start to map the data in the specified sources (s3://enem-bucket/content). A few seconds later, the process finishes and, if everything goes well, a new table called content should appear in the enem_pdf_project database.
Now, the Glue job will be able to read the S3 JSON files referencing this table from the catalog.
I think this is actually not needed, as you can query S3 directly, but the lesson stays.
Now, we’re ready to code our job.
Inside the Jobs task, you can choose many ways to develop a new job: visually connecting blocks, using interactive pyspark notebooks sessions, or coding directly on a script editor.

I suggest that you explore the options yourself (watch out for the notebook sessions, you pay for them). Regardless of your choice, name the created job Spark_EnemExtractQuestionsJSON. I choose to use Spark because I’m more familiar with it. See the code below.
from awsglue.transforms import *
from pyspark.context import SparkContext
import pyspark.sql.functions as F
from awsglue.context import GlueContext
from awsglue.job import Job
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
# Reading the table content from the Data Catalog
dyf = glueContext.create_dynamic_frame.from_catalog(
database="enem_pdf_project", table_name="content"
)
dyf.printSchema()
# Just pyspark script below
df = dyf.toDF()
# Create a new column with the year
df = df.withColumn(
"year", F.regexp_extract(F.col("original_uri"), ".+pdf_([0-9]{4})", 1)
)
# Split the text using the 'questão XX' regex
# and explode the resultant list
# resulting in one row per question
df = (
df.withColumn("text", F.lower(F.col("content")))
.withColumn(
"text",
F.regexp_replace(
F.col("text"), "(questão [0-9]+)", "<QUESTION_START_MARKER>$1"
),
)
.withColumn("text", F.split(F.col("text"), "<QUESTION_START_MARKER>"))
.withColumn("question", F.explode(F.col("text")))
.withColumn(
"question_number", F.regexp_extract(F.col("question"), "questão ([0-9]+)", 1)
)
.drop("content", "text")
)
# Save the result in CSV to S3
df.write.csv("s3://enem-bucket/processed/", mode="overwrite", header=True)
job.commit()Besides some extra bits of code needed to interact with the AWS infrastructure (on the readings and writings), all the processing logic is written using standard pyspark operations. If you are interested in understanding a little more about Spark, check out one of my previous posts.
By default, Glue jobs are configured to run on-demand, which means that we have to trigger its execution manually, using the AWS interface, or through API calls.
So, we only need a new task in the Airflow DAG to trigger the job and finish the pipeline.
Luckily, the code needed to do this is very simple, so let’s go back to the process_enem_pdf.py file and create a new function
def trigger_process_enem_pdf_glue_job(
job_name
):
session = AwsGenericHook(aws_conn_id=AWS_CONN_ID)
# Get a client in the same region as the Glue job
boto3_session = session.get_session(
region_name='us-east-1',
)
# Trigger the job using its name
client = boto3_session.client('glue')
client.start_job_run(
JobName=job_name,
)And add this function as a task in the DAG …
with dag:
download_pdf_upload_s3 = PythonOperator(
task_id='download_pdf_upload_s3',
python_callable=download_pdfs_from_year,
op_kwargs={
'year_variable': 'year',
'bucket': 'enem-bucket',
},
)
trigger_glue_job = PythonOperator(
task_id='trigger_glue_job',
python_callable=trigger_process_enem_pdf_glue_job,
op_kwargs={
'job_name': 'Spark_EnemExtractQuestionsJSON'
},
)
download_pdf_upload_s3 >> trigger_glue_jobAnd, voilá, the pipeline is finished.

Now, on every run, the pipeline should download the newest PDFs available, and upload them to S3, which triggers a Lambda Function that extracts their texts and saves them in the /content path. This path was mapped by a crawler and is available in the data catalog. When the pipeline triggers the Glue job, it reads these texts, extracts each question, and saves the results as CSV in the /processed path.

See the results below…

Conclusion
This was a long adventure.
In this post, we built an entire data pipeline from scratch mixing the power of various famous data-related tools, both from the AWS cloud (Lambda, Glue, and S3) and the local environment (Airflow+Docker).
We explored the functionalities of Lambda and Glue in the context of data processing, discussing their advantages and use cases. We also learned a little about Airflow, the most famous orchestration tool for data pipelines.
Each one of these tools is a world by itself. I tried to compress all the information learned during the project’s development period into the smallest post possible so, unavoidably, some information was lost. Let me know in the comments if you have problems or doubts.
I know that the data pipeline proposed is probably not optimal, especially in terms of cost vs efficiency, but the main point of this post (for me, and I expect that it worked this way for you as well) is to learn the overall process of developing data products with the tools addressed.
Also, the majority of the data available today, especially on the internet, is in the so-called unstructured format, such as PDFs, videos, images, and so on. Processing this kind of data is a crucial skill that involves knowing a broader set of tools that go beyond the usual Pandas/Spark/SQL group. The pipeline we built today addresses exactly this kind of problem by transforming raw PDFs stored on a website into semi-structured CSV files stored in our cloud infrastructure.
For me, a highlight of this pipeline was the text extraction step deployed with AWS Lambda, because this task would probably be impossible or very difficult (as far as I know) to implement using only Spark.
And this is what I hope you took away from this post: Developing a good data infrastructure requires not only some theoretical knowledge of data architectures, data modeling, or streaming but also a good understanding of the available tools that can help materialize your vision.
As always, I am not an expert in any of the subjects discussed, and I strongly recommend further reading and discussion (see some references below).
It cost me 36 cents + taxes ;-;
Thank you for reading! ;)
References
All the code is available in this GitHub repository.
Data used —ENEM PDFs, [CC BY-ND 3.0], MEC-Brazilian Gov.
[1] Amazon Web Services Latin America. (2021, December 6). Transforme e catalogue dados com o AWS Glue Parte 1 — Português [Video]. YouTube. Link.
[2] Bakshi, U. (2023, February 9). How to Upload File to S3 using Python AWS Lambda — Geek Culture — Medium. Medium. Link.
[3] Cairocoders. (2020, March 5). How to Import Custom Python Packages on AWS Lambda Function [Video]. YouTube. Link.
[4] How to extract, transform, and load data for analytic processing using AWS Glue (Part 2) | Amazon Web Services. (2022, April 4). Amazon Web Services. Link.
[5] How to write a file or data to an S3 object using boto3. (n.d.). Stack Overflow. Link.
[6] Tutorial: Using an Amazon S3 trigger to invoke a Lambda function — AWS Lambda. (n.d.). Link.
[7] Um Inventor Qualquer. (2022, January 10). Aprenda AWS Lambda neste Curso Prático GRATUITO! | Aula 17 — #70 [Video]. YouTube. Link.
[8] Chambers, B., & Zaharia, M. (2018). Spark: The definitive guide: Big data processing made simple. “ O’Reilly Media, Inc.”.
