Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Are Apache Iceberg Tables Right For Your Data Lake? 6 Reasons Why.


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
Does it feel colder in here or is it all this Apache Iceberg talk?
Over the last few months, Apache Iceberg has come to the forefront as a promising new open-source table format that removes many of the largest barriers to lakehouse adoption – namely, the high-latency and lack of OLTP (Online Transaction Processing) support afforded by Apache Hive.
Databricks announced that Delta tables metadata will also be compatible with the Iceberg format, and Snowflake has also been moving aggressively to integrate with Iceberg. I think it’s safe to say it’s getting pretty cold in here.
Table of Contents
What is Apache Iceberg?
Apache Iceberg is an open source data lakehouse table format developed by the data engineering team at Netflix to provide a faster and easier way to process large datasets at scale. It is designed to be easily queryable with SQL even for large analytic tables (we’re talking petabytes of data).
Where modern data warehouses and lakehouses will offer both compute and storage, Iceberg focuses on providing cost effective, structured storage that can be accessed by the many different engines that may be leveraged across your organization at the same time, like Apache Spark, Trino, Apache Flink, Presto, Apache Hive, and Impala.
Iceberg breaks away from the directory table structure, and instead defines a table as a canonical list of files with metadata on those files themselves, rather than metadata on directories of files. These files can be added, removed or modified indivisibly, with full read isolation and multiple concurrent writes.
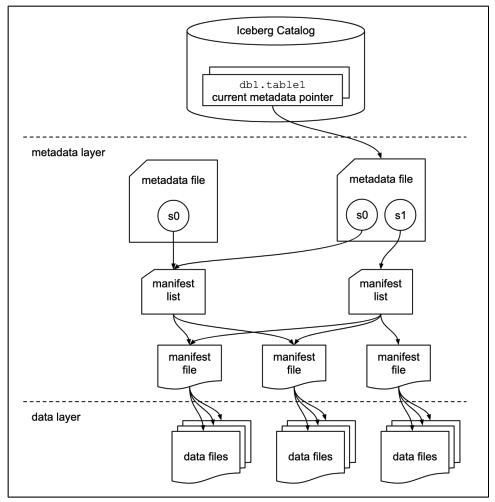
courtesy of Dremio.
So, is Iceberg right for you? In this piece, we break down popular Iceberg use cases, advantages and disadvantages, and its impact on data quality so you can make the table format decision that’s right for your team. Let’s dive in.
Is your data lake a good fit for Iceberg?
Like many open table formats with ACID properties, Apache Iceberg is a good fit for data teams working with large volumes of data in a lakehouse environment.
Some common use cases for Iceberg might include:
- Cost-sensitive organizations with petabytes of data that needs to be stored for long periods of time and consistently updated;
- Teams that already have heavily customized data infrastructures and the expertise to maintain them long-term; and
- Teams with a wide range of data consumer personas querying the data with multiple engine types (especially teams that require fast and frequent deletions, updates, or have unpredictable schema changes across engines).
If these use cases sound familiar, then it may make sense to migrate to Apache Iceberg. However, any data migration at scale is a significant endeavor, and one that risks potential data downtime. So, it’s best to ensure you understand all of the potential advantages, disadvantages, and risks associated with migrating before you jump into the icy water.
What are the advantages of Apache Iceberg tables?
First, let’s explore a few benefits of Apache Iceberg and how it can make data lakehouse management easier.
- High ecosystem compatibility with flexible SQL: Iceberg was built to be compatible with existing processing tools, meaning it can be used with any engine including Spark, Flink, Presto, and more. Across larger data organizations, there might be several teams running queries across multiple use cases with each leveraging different tools. For instance, a data scientist might be using data to power computations in their Juptyer notebook while the data engineering team might be querying the same data for a customer-facing data product. Because you can use Iceberg across engines, the raw table can serve as a single source of truth across your stack rather than having to duplicate tables in each environment.
- Schema evolution: Iceberg lets you change the structure of your data without interrupting the data itself. You can add a column, rename, and reorder, and changes won’t require a table rewrite – saving you time.
- Data versioning, time travel and rollback: Iceberg makes it easy to reproduce queries with immutable snapshots to see, track, and undo changes in your data should issues arise.
- Hidden partitioning: Unlike other SQL-based table formats, Iceberg doesn’t require user-maintained partitioned columns, so it can handle the tedious task of producing partition values for rows in a table. Partition values are automatically configured every time, no extra filters are needed for fast queries, and table layouts can be updated as data or queries change.
- Data compaction: With Iceberg, teams can choose from various rewrite strategies to optimize file layout, size, and as a result, storage, thereby improving query performance on massively large data sets compared to Hive.
- Cost savings: Technically speaking, Iceberg is more cost-effective than using a managed data store because it’s open source and publicly available. And with its low-latency and high performance compared to other open source formats, you can make the argument that you get more bang for your buck. However, like any open source solution, there is more upfront investment in terms of data engineering time spent on upfront configuration and maintenance overtime.
What are the disadvantages of Apache Iceberg tables?
While Apache Iceberg is often hailed as the answer to our lakehouse problems, it’s not right for every data organization. Here are a few disadvantages to consider before you take the plunge:
- Higher complexity: The maintenance required for Apache Iceberg tables is a significant drawback, requiring more data engineering resources spent on infrastructure maintenance rather than unlocking data value. However, leveraging a solution like Tabular, an Apache Iceberg managed table store that bills itself as a “headless data warehouse,” can help remove some of that data management overhead and streamline resource management.
- Distributed computing framework: Iceberg uses a distributed computing framework to process multiple large SQL tables at the same time across multiple query engines. Without a central query log, your team can run the risk of data loss and lack of data governance.
- Limited data type support. Apache Iceberg supports several data types, including text, integers, and floats. However, it can be difficult to store certain types of data in the table format, like images, meaning that data will have to be stored elsewhere, adding greater complexity to your stack.
How data observability can increase data trust in Iceberg tables
Data quality is the backbone of a successful enterprise business, and a risk to data integrity should not be taken lightly. As with any table format, Apache Iceberg tables are only as useful and reliable as the data stored in them. It’s essential to ensure your data is fresh and accurate so your queries will pull accurate information – and your business can make trustworthy decisions.
Because Apache Iceberg is engine-agnostic, it allows for querying the same data concurrently across different processing engines, which is ideal for businesses looking to avoid vendor lock-in and support the preferences of various internal teams. However, running concurrent queries across processing engines is likely to leave your data susceptible to gaps. And while Iceberg’s ability to support rollbacks has the potential to help improve data quality with reversion to previous states, data quality issues, like inconsistency, incompleteness, and inaccuracy, are likely to remain. These issues can look like:
- Data inconsistency: Tables with both raw and transformed data or both frequently updated data and stale data – affecting the accuracy of data analysis and reporting.
- Data incompleteness: Corrupted, incomplete, or data missing from your tables, such as data ingested without all the required fields or data damaged due to human or technical errors.
- Data inaccuracy: Tables that include incorrect, irrelevant, or misleading data, such as data with anomalies or errors or data misaligned with the business needs.
With any table format, Apache Iceberg or otherwise, one thing is certain: raw data in a lakehouse is always more prone to data quality issues like these. The ability to monitor and alert to these issues is critical for the success of data products – and many companies are turning to data observability to provide that end-to-end monitoring of their data pipelines and gain visibility into the health of the data.
A data observability tool can analyze historical patterns in data while adding custom rules and thresholds – ensuring the right data team is notified if data issues occur. This can massively minimize data downtime, maintaining data quality throughout the lifecycle and increasing stakeholder data trust.
So, if Apache Iceberg sounds like the right table format for your team’s lakehouse needs, we recommend investing in data observability from day one.
Want to learn more about how data observability can help you get more out of Apache Iceberg? Contact our team to learn more.
Our promise: we will show you the product.
Read more posts.