Data Engineering: Incremental Data Loading Strategies
Outlining strategies and solution architectures to incrementally load data from various data sources.
The era of big data requires strategies to handle data efficiently and cost-effectively. Incremental data ingestion becomes the go-to solution when working with various and critical data sources generating data at a high velocity and low latency.
Years of serving as a data engineer and analyst working on integrating many data sources into enterprise data platforms, I managed to encounter one complexity after another when trying to incrementally ingest and load data into target data lakes and databases. Complexity shines when the data is of bits and pieces lying around the dust and in the corners of dear old legacy systems. Digging through those systems to find the golden interfaces, timestamps, and identifiers to hopefully enable seamless and incremental integration.
This is a common scenario where engineers and analysts are faced with when new data sources are needed for analytical use cases. Running a smooth data ingestion implementation is a craft, that many engineers and analysts aim to perfect. That is sometimes far-fetched and depending on the source systems, and the data they provide, things can get messy and complicated with workarounds and scripts here and there to patch things up.
In this story, I will outline a comprehensive overview of solutions for implementing incremental data ingestion strategies. Taking into consideration data source characteristics, data format, and properties of the data being ingested. The coming sections will focus on strategies to optimize incremental data loading therefore avoiding duplicate data records, reducing redundant data transfer, and decreasing load on operational source systems. We discuss high-level solution implementations and explain its components with the expected data flows. We list incremental strategies depending on data sources from Databases to File Storage and how to approach solutions for each. Let’s dive in.

1 — Databases
Databases are one of the most popular data sources when it comes to data ingestion. Whether it is relational or non-relational, and depending on which ingestion tool or package is used, most databases are usually supported. Incremental ingestions from databases can take on many strategies depending on requirements and data availability.
1.1 Direct Query Connection
This approach includes a consumer application establishing a direct connection to a database. The applications utilize a query language to select and filter data tables.
To enable effective incremental ingestion, The first approach requires the data schema to have only a creation timestamp field (for immutable records), while the second requires a last modification timestamp combined with a unique identifier.
1.1.1 Creation Timestamp
For direct connections utilizing creation timestamps, it can be as simple as querying the databases for new records utilizing the last creation timestamp as a filter criterion. The diagram shows the request flow between the consumer and the database. To make sure that timestamps are not lost, run timestamp entries are stored in an external storage for future retrieval.

Data Requirements and Assumptions
- Creation Timestamp
- Records are immutable (cannot be modified later from the source)
Sample Query to Database
SELECT
*
FROM
TABLE
WHERE
CREATEDON > <last_run_timestamp>1.1.2 Modification Timestamp
Similar to the creation timestamp, records that can be modified require a new approach as shown below. It is important for this approach that a unique identifier exists to avoid duplicate records, as the same record ID can be ingested again with a new creation date.
It could be also that requirements are to maintain a history of the changes, for more on this I recommend checking the different types of Slowly Changing Dimensions (Recommended books to read more on SCD: Data Warehouse Toolkit”)

Data Requirements and Assumptions
- Modified Timestamp
- The modified timestamp matches the creation timestamp when no modifications are applied yet.
- Records have a unique identifier.
- Records can be modified from the source.
Consumer sample import query
SELECT
*
FROM
TABLE
WHERE
MODIFIEDON > <last_modified_timestamp>Consumer sample merge query
MERGE INTO silver_table AS silver
USING (SELECT*FROM raw_table) AS raw --raw_table containing imported raw records
ON silver.id= raw.id
WHEN MATCHED THEN
UPDATE SET
silver.name= raw.name,
silver.category= raw.category,
silver.updated_at= raw.updated_at
WHEN NOT MATCHED THEN
INSERT (id, name, category, updated_at)
VALUES (raw.id, raw.name, raw.category, raw.updated_at);In the sample merge query, the raw_table contains raw ingested data which may contain duplicate records. The merge to the silver_table ensures that matching IDs are merged into one record with fields like category and updated_at are changed to match the new data.
1.1.3 Important to consider
The creation and modified timestamps can have different meanings depending on the source system. Understanding the meaning of the fields in relation to the table context is crucial.
a. Two creation timestamp fields
This situation can occur when a creation timestamp refers to the creation of the record in the DB and not the original event occurrence. Thus using the wrong creation date will result in importing duplicate records, as a modified record will be imported twice containing two different database creation timestamps.
b. Creation timestamp with initial empty modified timestamp
This case requires the incremental ingestion pipeline to keep track of both timestamps. The situation arises when efficiency is highly required and a merge is very expensive to run on a large table with every new data load.
1.2 Change Data Capture: (CDC)
Pulling data from a database traditionally involves a scheduled data import approach where the database is queried for new data on every run. This can become an issue when many applications pull data from a critical operational database thus impacting its performance.

An alternative approach, that adds a real-time sync possibility between the source and its consumer is using Change Data Capture or CDC. CDC enables DML changes on the databases to be pushed to the consumer in real time.
These transaction logs are then used by the consumer to keep its storage in sync with the databases. CDC can sometimes be more challenging to implement depending on the use case and the tech used.
Transaction logs are usually streamed from the DB, requiring the stream to be temporarily persisted until the consumer ingests and applies the changes to the target storage.
For that additional components to the full ingestion pipeline are needed. Those can be a simple queue, a Kafka broker, or any similar queueing or event streaming systems.
2 — APIs
Applications and 3rd party systems will provide an API layer for consumers to interact with their data. Providers can have their APIs engineered for core application use cases, which can make it harder for those APIs to be used for large-scale data ingestion.

Depending on how flexible an API is, ingesting data from APIs can be relatively similar to that of the requirements for a database data schema.
For incremental ingestion to run smoothly, the API requires timestamp parameters to indicate new or modified data. Similar to the databases, that could be a creation timestamp parameter in case of an immutable data record, otherwise a modification timestamp with a unique identifier.
It is important that the API schema is well documented and attributes are clearly described and tested, unlike relational databases response data from APIs are bound to frequent breaking changes.
Data Requirements and Assumptions follow those of the database section mentioned above.
Sample Python script for loading data incrementally from APIs
import requests
import json
from datetime import datetime
def fetchData(url,from_date, to_date):
"""
Fetch data from the API with the given date range.
"""
endpoint = f"{url}/data?from={from_date}&to={to_date}"
response = requests.get(endpoint)
if response.status_code == 200:
return response.json()
else:
raise Exception(f"Failed to fetch data: {response.status_code}")
def getFromDate():
"""
Depending on the chosen checkpointing storage, this method implements
returning the from date
"""
pass
def exportToStorage(data, file_name):
"""
Depending on the chosen target storage, this method implements
inserting or merging the data
"""
pass
if __name__ == "__main__":
URL = "http://exampleendpointurl.com" # Placeholder URL
# Get from and to dates
from_date = getFromDate()
to_date = datetime.now().strftime('%Y-%m-%d')
# Fetch data
data = fetchData(URL, from_date, to_date)
# Create a file name with the current timestamp
timestamp = datetime.now().strftime('%Y%m%d%H%M%S')
file_name = f"{timestamp}_datasource.json"
# Export data to storage with the given file name
exportToStorage(data, file_name)API Data Ingestion Limitations
Depending on the data source/provider and the frequency of how recently the data is needed, this approach can rack extensive costs and load on source systems and may reach API call limitations if the data is too large.
An alternative approach for loading data incrementally at scale when it comes to APIs, would be a push mechanism. The data will be stored in cheap file storage for later processing. This is discussed in the next section.
3 — File Storage
File storage is arguably one of the most popular data storage solutions in recent years, attributing that to its setup effort, scalability, and cost-effectiveness. Data stored long-term in file storage is usually used for archival, backup, or analytical & AI purposes.
The strategy to load data from file storage will heavily depend on how data is stored and structured. It will also depend on the type of file storage, and whether additional services (e.g. in the Cloud) are provided to support the incremental data ingestion strategies (Some cloud vendors offer seamless queueing integration out of the box for new files landing in the file storage).
- Raw incremental data files
Data files are usually dumped into a storage account with the aim of later retrieval. How data lands and is structured in the storage can have a huge impact on the effort it requires to retrieve it efficiently.

For our use case, we assume that data is coming from a single data source and thus a single directory is being used to store data files. The data schema contains a unique identifier and an attribute that contains the creation or modification timestamps (following the approach discussed in the above sections). We add that the file format can vary between JSON, PARQUET, DELTA, etc.. (this can play a bigger role in the next section).
Data Requirements and Assumptions
- Data files have a unique file name.
- Old data files are not replaced with the same names and new data.
It can be possible to implement the ingestion process without notification components/queue, but with a growing number of data files, the consumer will be required to go through the list of all files on every ingestion run.

Using an event queue removes the requirements for scheduling, and can thus provide faster loading time to new data. An additional checkpoint storage can still mitigate loading files twice and be used as an additional efficiency gate.
2. File Storage Query Engine
In this approach, the file storage is treated as a database source, where standard SQL queries can run on top of the data files. There is a long list of open-source projects that bring a query engine on file storage, like Apache Hive, Presto, Apache Drill, etc.
Many cloud providers have query engine solutions that support their file storage systems, like Google Big Query, Azure Databricks SQL, Azure Synapse Analytics, and Amazon Athena.

When using query engines, it is important to analyze the best approach to store the data files (structure and hierarchy, file size, format, etc..). It plays a crucial role in the optimization and speed of the queries, especially in the scenario of having many small files, where query engines will have to loop through each file. This brings us back to using the database incremental loading approach mentioned before but with an additional query engine layer.
Final Words
Designing an end-to-end solution for incremental data loading requires an understanding of the source systems and the needs of the end data consumers. Begin with the data source and an assessment of the data it provides, to refine the strategy that best aligns with requirements, SLAs, and potential budget constraints.
Every situation might have its unique circumstances or limitations, and many will require you to use combinations of the approaches discussed. Sometimes data sources make it impossible to incrementally ingest the data, and thus require alternative mitigation batch data loading approaches.
I always recommend the top data engineering books that cover partially the concepts we discuss here in more details, feel free to check them here
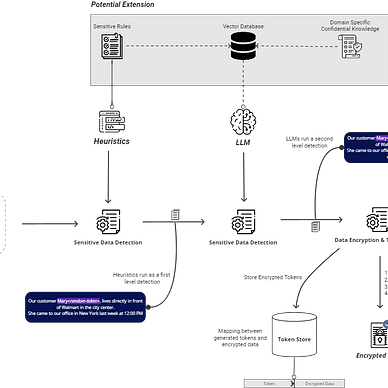
Further architecture that complements solutions discussed in this article

Thank you for taking the time to read through the blog. I believe that time is incredibly valuable, and with that in mind, I try to ensure that my articles are concise and deliver substantial value for your reading time. If they meet your expectations, your feedback would be greatly appreciated to guide my ongoing improvement.
Thank you and Happy Engineering !
