DuckDB vs Polars for Data Engineering.

Photo by Liz Sanchez-Vegas on Unsplash
I was wondering the other day … since Polars now has a SQL context and is getting more popular by the day, do I need DuckDB anymore? These two tools are hot. Very hot. I haven’t seen this since Databricks and Snowflake first came out and started throwing mud at each other.
You might think it doesn’t matter. Two of one, half-dozen of another, whatever. But I think about these things. Simplicity is underrated these days. If you have two tools but could do it with one, should you use two? Probably depends on the Engineering culture you’re working in.
I mean just because you can doesn’t mean you should. Some data engineering repo with 50 different Python pip packages installed, constantly breaking and upgrading for no reason. CI/CD build failing, conflicts. Frustration. Why? Just because someone wants to do this one thing and decided they needed yet another package to do it.
That’s a slippery slope, my friend. That says something about how seriously you take your calling, your Data Engineering calling. In the age of ChatGTP and CoPilot, both of which write code just as good or better than you, what is your value? Your value is that you are a human with emotions and context, the ability to see the big picture and make good decisions.
Your value as an Engineering in the future is more than ever going to be based on your ability to be wise and build good, scalable, clean, and robust systems. And so we return to our original question. DuckDB or Polars to solve a Data Engineering problem? What’s the bigger picture, what should you use? Polars has a SQL context anyways, so is there any difference at all?
DuckDB vs Polars.
Funny enough, DuckDB has a Polars extension. Import both tools, do some stuff in Polars, then run some SQL on a Polars Dataframe with DuckDB. I mean why not overcomplicate your pipeline, you’re bored, right?
I don’t think this is going to be some heady stuff we are getting into. It’s actually pretty straightforward. What’s the real difference between Polars and DuckDB?
- DuckDB is going to be
SQLfrom end to end. - Polars is
Dataframecentric with aSQLoption. - Polars is a high-performance tool.
- DuckDB is taking aim at analytics and databases.
- Polars is taking aim at ETL and pipeline tools.
- There is much overlap in what each tool does.
- Simplicity is the name of the game for DuckDB.
- Polars isn’t necessarily simple. It’s fast and complex.
Can we surmise anything from this? Well, we Data Engineers are good at solving data problems in a variety of manners, we can pretty much use any tool to do anything, even if we shouldn’t. I think generally speaking you will find that most of the Data Engineering community falls into one of two camps.
- Those “data” people who love SQL, and came from non-traditional backgrounds.
- Those classically “software” folks who thrive in writing code, are probably Polars lovers.
Sure, you get people in between and all along the bell curve, but we all know why DuckDB is getting so many downloads. If it’s got SQL in the name, it’s got fans.
I mean can you really compare DuckDB vs Polars? Yes, because you will have people choosing between the two and writing pipelines in one or the other. Here is my guess on how it will break down.
- Those who value non-SQL-centric data pipelines will choose Polars, and use its SQL context when needed.
- Those who already love SQL will choose DuckDB hands down.
- If you like to write re-usable, functionally, unit-tested code you will use Polars.
- If you have tabular data that uses lots of analytics and groupings with aggregates, you will pick DuckDB.
These two different data pipelines will fundamentally probably look much differently depending on the engineer writing them. We should probably write pipeline in both Polars and DuckDB to see the difference.
Data Pipelines with DuckDB.
I’m going to give you the 10,000-foot view of DuckDBbefore we dive into code and pipeline examples.
“DuckDB is an in-process
SQL OLAP database management system” – duckdb.org
What does that mean? It means DuckDB is a simple, easy-to-use and install SQL based data tool. The “in-process” mention is important … it’s “shorted lived” in the sense the runtime lasts as long as your process. It’s not Postgres or SQLServer is what they are trying to say.
What exactly can DuckDB DO? Here are some things Data Engineers will be interested in.
- Read and write to
CSVfiles. - Read and write
Parquetfiles. - Read and write
JSONfiles. - Read and write
s3and other remote files. - Run functions, expressions, and aggregations via SQL.
I know this might not sound like anything earth-moving, but it kinda sneaks up on you. Usually, the best things in life are simple. What is it exactly that Data Engineers look for in tools when building pipelines? At the beginning of my Data Engineering life, I thought it was the complexity that was to be reached, complicated is good right? It gave an illusion of goodness and made you feel like you were doing something.
I’ve changed my evil ways. So this simplicity of DuckDB can be very attractive. Less to break, easy to use, and easy to ramp up engineers onto it. I mean, of course, we have to think about use cases, putting the right tool in the right spot etc, but I think we can find a home for DuckDB don’t you?
I mean how many times if your life have you had to do simple flat-file and data manipulation and dump the results back out somewhere? Like a zillion times. I have a feeling DuckDB could make your life easier in this aspect.
DuckDB example pipeline.
So our examples are always a little contrived, but if we do it correctly, we can get some ideas of what it’s like to use DuckDB in the real world. Let’s write a pipeline that …
- read
CSVfile froms3bucket. - calculate some metrics.
- write the results back to
s3as a parquet file.
I’m using Divvy Bike trip open-source data set.
I also setup a GitHub repo with docker and docker-compose with all the tools installed and ready to go so it’s easier to run this code, you can check it out here.
But, let’s look at our simple DuckDB pipeline. Let’s just make sure it works.
import duckdb
def main():
results = duckdb.sql("""
INSTALL httpfs;
LOAD httpfs;
SET s3_region='us-east-1';
SET s3_access_key_id='';
SET s3_secret_access_key='';
SELECT CAST(started_at as DATE) as dt,
rideable_type,
COUNT(ride_id) as cnt_per_day
FROM read_csv_auto('s3://confessions-of-a-data-guy/202303-divvy-tripdata.csv')
GROUP BY CAST(started_at as DATE), rideable_type;
""").fetchall()
print(results)
if __name__ == '__main__':
main()
The output is not pretty and leaves much to be desired. But it works.
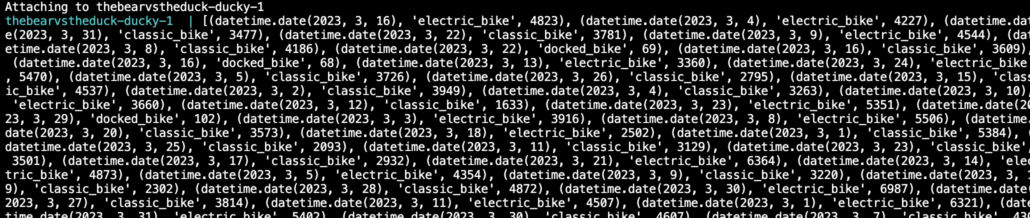
I want to make one comment before I move on to the simple step of writing these results out to s3 as a parquet file. Did you notice how easy and simple that was? More on that later.
BTW. It turns out using fetchall() returns the results as Python objects, hence the crappy output. You can use df, pl, or arrow to pull the results to pandas, polars, or arrow, respectively.
The next step of sending the results to s3 as a parquet is barely worth mentioning. Also, we modify the above code to create a View of our metrics, then copy that View out to s3. Here is the code.
import duckdb
def main():
duckdb.sql("""
INSTALL httpfs;
LOAD httpfs;
SET s3_region='us-east-1';
SET s3_access_key_id='';
SET s3_secret_access_key='';
CREATE VIEW metrics AS
SELECT CAST(started_at as DATE) as dt,
rideable_type,
COUNT(ride_id) as cnt_per_day
FROM read_csv_auto('s3://confessions-of-a-data-guy/202303-divvy-tripdata.csv')
GROUP BY CAST(started_at as DATE), rideable_type;
""")
duckdb.sql("""
COPY metrics TO 's3://confessions-of-a-data-guy/results.parquet';
""")
if __name__ == '__main__':
main()
And it works by George. No first-time errors … that’s a first.
I have to say, I’m impressed, and probably for different reasons than you, maybe. I mean sure, it’s another SQL tool and that probably has something to do with its meteoric rise. But I see something different in this little snippet of code that we wrote.
I see simplicity. I see the ease of use and approachability. I also see something that could easily become the modern version of those SQL Server data stacks full of unrecognizable stored procedures, triggers, and views, that quickly becomes out of hand and untestable. Let the user be warned.
Polars example pipeline.
It’s time to switch gears to the other new hot stuff, Polars of course. Polars is a beast in the data world now, a force to be reckoned with, devouring that poor and hobbled old Pandas for lunch. Truly a breath of fresh air for all those stuck between Spark and Pandas, with no other option.
Most thralls of good old fashioned Data Engineering appreciate the Dataframe and what it represents to us poor folk. The ability to write functional and unit-testable code is truly the savior of us all, Polars gives us that option.
Since I’ve been reading Beowulf and I’m getting long-winded already, let’s dive into the same task we just did with DuckDB and write some code, then make some comments on it.
The first problem.
Surprisingly, I immediately fell into a state of shock. Either I’m not up-to-date on my Polars, or it appears that I’m going to have to immediately introduce a second tool to read a file from s3 using Polars. I was hoping for some Spark-like feature, just point and shoot my friend. No such luck.
Such is life, on with it as they say.
import os
import boto3
import tempfile
import polars as pl
os.environ['AWS_ACCESS_KEY_ID']=''
os.environ['AWS_SECRET_ACCESS_KEY']=''
def main():
s3 = boto3.client('s3')
with tempfile.NamedTemporaryFile(mode='wb', delete=False) as temp_file:
# Download the CSV file from S3
s3.download_fileobj("confessions-of-a-data-guy",
"202303-divvy-tripdata.csv",
temp_file)
df = pl.read_csv(temp_file.name, try_parse_dates=True)
df = df.groupby([pl.col('started_at').dt.date().alias('dt'),
'rideable_type']).agg([pl.count('ride_id')]
)
fs = s3fs.S3FileSystem()
with fs.open('confessions-of-a-data-guy/polars.parquet', mode='wb') as f:
df.write_parquet(f)
if __name__ == '__main__':
main()
I’m sure there is plenty of ways to do this to the astute cadre of internet genius, but this was mine. I do wish Polars had a tighter integration with cloud storage like s3, that’s where things get wonderful. This code is interesting, it’s not overly complex but it does require a number of separate packages to get the job done.
I’m sure someone will correct me later about my foolhardiness and terrible approach to this problem, but there it is. Polars requires me to think this way to write the pipeline, we all would have to choose our own routes and ways to solve this problem. This was just mine.
A Few Notes
My thoughts are thus. I love the simplicity of DuckDB, it’s hard to beat, and probably the reason it’s getting some hype. I can appreciate the simple, now, in ways I could not in the past. I used to think complex was good, some sort of faux wonderfulness.
Martin Luther put it something like this …
“I was a good monk, and I kept the rules of my order so strictly that I may say that if ever a monk got to heaven by his monkery it was I.”
Many years later Software Engineers and Developers still fall into the same trap. Sure, there can be a time and place for monkery, and complexity, when it’s warranted. Most of the time it’s not.
I love a good dataframe library, and Polars is the next generation. I hope to see it in a distributed version someday soon, all hope springs eternal. But, you can see from the code above it does require a bit more antics to make it happen. You know what comes after antics … bugs. I mean this was just a simple example, in a complex production situation where pipelines are much more complex, and integrations are much more important, it’s easy to see how things would get out of hand.
Unit tests are going to be important with Polars, keep one’s self from shooting the old foot.
Lest you think I bear some ill will, I have my concerns about DuckDB as well. Writing gobs of SQL was the path down which our forefathers tread to their eternal doom. The hellish place where the stored procedures, triggers, and endless CTE’s live. So much logic, bitterness, and hatred poured into those systems. Places where good engineers go to their eternal reward never to return.
You should tread the DuckDB path carefully. Remember what makes good data pipelines … clean, reusable, and testable code.
Polars requires rust to be installed, which creates quite some overhead to install it somewhere (CI pipeline, lambda functions etc.). awswrangler with pyarrow engine is probably also something to consider for your next pipeline in case it mingles with AWS.