20+ Data Engineering Projects for Beginners in 2024
Explore top 20 real-world data engineering projects ideas for beginners with source code to gain hands-on experience on diverse data engineering skills.

Most of us have observed that data scientist is usually labeled the hottest job of the 21st century, but is it the only most desirable job? No, that is not the only job in the data world. Data professionals who work with raw data, like data engineers, data analysts, machine learning scientists, and machine learning engineers, also play a crucial role in any data science project. And, out of these professions, we will focus on the data engineering job role in this blog and list out a comprehensive list of projects to help you prepare for the same.
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor). Cloud computing skills, especially in Microsoft Azure, SQL, Python, and expertise in big data technologies like Apache Spark and Hadoop, are highly sought after. These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
The growing demand for data engineering jobs highlights their important role in driving innovation. Thus, data engineering job applicants must showcase real-world project experience and grasp various data engineering technologies to stand out as a candidate. If you are also one, explore ProjectPro's data engineering project ideas for a head start. But before you hop on to the projects list, check out the next section, which showcases the basic structure of a data engineering project for clarity and reusability.
Data Engineering Project Structure
Often, beginners in data engineering struggle with managing the code and data of a data engineer project. In this section, we will cover the general structure of a data engineering project that you can refer to for all your projects in data engineering. However, don’t forget to tweak it to fit your needs.
-
config/: This folder will have the configuration files for your project, such as database connection details, API keys, or other project-specific settings. It keeps these configurations separate from the code to simplify updates.
-
data/: This directory stores both raw and processed data files. It has two subfolders: raw/ for unprocessed data and processed/ for transformed data. This structure ensures access to the original data files and tracks changes made during processing.
-
docs/: The "docs" folder has project documentation, including user guides, README files, and technical documentation. It aims to maintain comprehensive documentation for better project understandability and maintainability.
-
etl/: This directory contains scripts for performing Extract, Transform, and Load (ETL) tasks. It is divided into three subfolders: extract/, transform/, and load/, each hosting script for data extraction, transformation, and loading, respectively.
-
pipelines/: This folder contains data pipeline orchestration scripts. These scripts define the order in which different ETL processes or other data processing steps should be executed.
-
src/: The "src" folder stores the source code for the project, including data processing and transformation scripts, utility functions, and data validation scripts. It is organized into subfolders: data/, utils/, and validation/.
-
tests/: This directory contains unit and integration tests for the data engineering project. It ensures that the code functions as planned and helps identify potential issues before they escalate.
-
.gitignore: This file lists the files and folders that Git version control should not consider. It prevents accidental commits of specific files, such as data or configuration files containing sensitive information.
-
environment.yml: The "environment.yml" file details the Conda environment for the project, listing the required packages and their versions. It manages dependencies for easy setup and ensures consistent package versions across team members.
-
README.md: This file gives an overall idea of the project, including its purpose, setup instructions, and usage information. A well-written README file helps team members and users understand and utilize the project effectively.

This structure will also come handy when you work on building your data engineer portfolio. If you are a newbie in data engineering and are interested in exploring real-world data engineering projects, check out the list of best data engineering project examples below.
Top 20+ Data Engineering Project Ideas for Beginners with Source Code [2024]
We recommend over 20 top data engineering project ideas with an easily understandable architectural workflow covering most industry-required data engineer skills.
1) Smart IoT Infrastructure
2) Aviation Data Analysis
3) Event Data Analysis
4) Data Ingestion with Google Cloud Platform
5) Data Visualization
6) Data Aggregation
7) Building a web-based Surfline Dashboard
8) Log Analytics Project
9) COVID-19 Data Analysis
10) Movielens Data Analysis for Recommendations
11) Retail Analytics Project Example
12) Real-time Financial Market Data Pipeline with Finnhub API and Kafka
13) Real-time Music Application Data Processing Pipeline
14) Shipping and Distribution Demand Forecasting
15) Visualizing Reddit Data
16) Analyzing data from Crinacle
17) Live Twitter Sentiment Analysis
18) Website Monitoring
19) Bitcoin Mining
20) How to deal with slowly changing dimensions?
21) GCP Project to Explore Cloud Functions
22) Yelp Data Analysis
23) Data Governance
24) Real-time Data Ingestion
25) ETL Pipeline
26) Data Integration
27) ETL and ELT Operations
28) Apache Spark
29) Delta Lake
30) Apache Cassandra

Data Engineering Projects for Beginners
If you are a newbie in data engineering and are interested in exploring real-world data engineering projects, check out the examples below.
-
Smart IoT Infrastructure
In this IoT project, you will explore a general architecture for building smart IoT infrastructure. With the trending advance of IoT in every facet of life, technology has enabled us to handle a large amount of data ingested with high velocity. This big data project discusses IoT architecture with a sample use case.

This is a fictitious pipeline network system called SmartPipeNet, a network of sensors with a back-office control system that can monitor pipeline flow and react to events along various branches to give production feedback, detect and reactively reduce loss, and avoid accidents.
This architecture shows that simulated sensor data is ingested from MQTT to Kafka. The data in Kafka is analyzed with Spark Streaming API and stored in a column store called HBase. Finally, the data is published and visualized on a Java-based custom Dashboard.
Tech Stack: Apache Spark, Apache Kafka, Apache HBase
Source Code: Smart IoT Infrastructure Data Engineering Project with Source Code
-
Aviation Data Analysis
Aviation Data can segment passengers, observe their behavioral patterns, and contact them with relevant, targeted promotions. This helps improve customer service, enhance customer loyalty, and generate new revenue streams for the airline. In this project use case, you will learn how to get streaming data from an API, cleanse the data, transform it to gain insights, and visualize the data in a dashboard.

-
The primary step in this data project is to gather streaming data from Airline API using NiFi and batch data using AWS Redshift using Sqoop.
-
The next step is to build a data engineering pipeline using Apache Hive and Druid to analyze the data.
-
You will then compare the performances to discuss hive optimization techniques and visualize the data using AWS Quicksight.
Tech Stack: Apache NiFi, Kafka, HDFS, Hive, Druid, AWS QuickSight
Source Code: Aviation Data Analysis using Big Data Tools
-
Event Data Analysis
NYC Open Data is free public data published by New York City agencies and partners. This project is an opportunity for data enthusiasts to engage in the information produced and used by the New York City government. You will analyze accidents happening in NYC. This is an end-to-end big data project for building a data engineering pipeline involving data extraction, data cleansing, data transformation, exploratory analysis, data visualization, data modeling, and data flow orchestration of event data on the cloud.

In this big data project, you will explore various data engineering processes to extract real-time streaming event data from the NYC city accidents dataset. You will process the data on AWS to extract KPIs that will eventually be pushed to Elasticsearch for text-based search and analysis using Kibana visualization.
Tech Stack: Kibana, PySpark, AWS ElasticSearch.
Source Code: Event Data Analysis using AWS ELK Stack
-
Data Ingestion with Google Cloud Platform
This data engineer project involves data ingestion and processing pipeline with real-time streaming and batch loads on the Google cloud platform (GCP). The Yelp dataset, which is used for academic and research purposes, is processed here.

Create a service account on GCP and download Google Cloud SDK(Software developer kit). Then, Python software and all other dependencies are downloaded and connected to the GCP account for other processes. Then, the Yelp dataset downloaded in JSON format is connected to Cloud SDK, following connections to Cloud storage which is then connected with Cloud Composer. The Yelp dataset JSON stream is published to the PubSub topic. Cloud composer and PubSub outputs are Apache Beam and connected to Google Dataflow. Google BigQuery receives the structured data from workers. Finally, the data is passed to Google Data studio for visualization.
Tech Stack: Apache AirFlow, Apache Beam, GCP- Google Data Studio, Google BitQuery, Google Cloud Storage, Google Cloud Dataflow, Google Cloud Pub/Sub
Source Code: Data Ingestion with SQL using Google Cloud Dataflow
-
Data Visualization
A data engineer is occasionally asked to perform data analysis; it will thus be beneficial if they understand how data needs to be visualized for smooth analytics. This is because often, data analysts create an automated dashboard, the backbone of which relies primarily on the kind of data the team of data engineers provides.
We’ll explore the usage of Apache Airflow for managing workflows. Learn how to process Wikipedia archives using Hadoop and identify the lived pages in a day. Utilize Amazon S3 for storing data, Hive for data preprocessing, and Zeppelin notebooks for displaying trends and analysis. Understand the importance of Qubole in powering up Hadoop and Notebooks.
Tech Stack: Apache Hadoop, Apache Zeppelin, Apache Airflow
Source Code: Visualize Daily Wikipedia Trends with Hive, Zeppelin, and Airflow
-
Data Aggregation
Data Aggregation refers to collecting data from multiple sources and drawing insightful conclusions from it. It involves implementing mathematical operations like sum, count, average, etc., to accumulate data over a given period for better analysis. There are many more aspects to it and one can learn them better if they work on a sample data aggregation project.
Explore what real-time data processing is, the architecture of a big data project, and data flow by working on a sample of big data. Learn how to use various big data tools like Kafka, Zookeeper, Spark, HBase, and Hadoop for real-time data aggregation. Also, explore other alternatives like Apache Hadoop and Spark RDD.
Tech Stack: Apache Spark, Spark SQL, Python, Kafka.
Source Code: Real-time data collection & aggregation using Spark Streaming
-
Building a web-based Surfline Dashboard
This project will build a web-based dashboard for surfers that provides real-time information about surf conditions for popular surfing locations worldwide. The aim is to create a data pipeline that collects surf data from the Surfline API, processes it, and stores it in a Postgres data warehouse. If you are specifically looking for Python data engineering projects, this project should be your pick.

The first step in the pipeline is to collect surf data from the Surfline API. The data is then exported to a CSV file and uploaded to an AWS S3 bucket. S3 is an object storage service provided by AWS that allows data to be stored and retrieved from anywhere on the web. The most recent CSV file in the S3 bucket is then downloaded and ingested into the Postgres data warehouse. Postgres is an open-source relational database management system that stores and manages structured data. Airflow is used for orchestration in this pipeline. And Plotly is used to visualize the surf data stored in the Postgres database.
Tech Stack: AWS, PostgreSQL, Python, Surfline API.
Source Code: Surfline Dashboard u/andrem8 on GitHub
Intermediate-level Data Engineer Portfolio Project Examples for 2024
Here are data engineering project ideas that you can explore and add to your data engineering portfolio to showcase practical experience with data engineering problems. Let us discuss these sample projects for data engineers in detail.
-
Log Analytics Project
Logs help understand the criticality of any security breach, discover operational trends, establish a baseline, and perform forensic and audit analysis. In this project, you will apply your data engineering and analysis skills to acquire server log data, preprocess it, and store it in reliable distributed storage HDFS using the dataflow management framework Apache NiFi. This data engineering project involves cleaning and transforming data using Apache Spark to glean insights into what activities are happening on the server, such as the most frequent hosts hitting the server and which country or city causes the most network traffic with the server. You will then visualize these events using the Plotly-Dash to tell a story about the activities occurring on the server and if there is anything your team should be cautious about.

The current architecture is called Lambda architecture, where you can handle both real-time streaming data and batch data. Log files are pushed to Kafka topic using NiFi, and this Data is Analyzed and stored in Cassandra DB for real-time analytics. This is called Hot Path. The extracted data from Kafka is also stored in the HDFS path, which will be analyzed and visualized later, called the cold path in this architecture.
Tech Stack: Apache Kafka, AWS EC2, Apache NiFi, Spark Streaming, Cassandra, Docker
Source Code: Log Analytics Project with Spark Streaming and Kafka
-
COVID-19 Data Analysis
This is an exciting portfolio project example where you will learn how to preprocess and merge datasets to prepare them for the Live COVID19 API dataset analysis. After preprocessing, cleansing, and data transformation, you will visualize data in various Dashboards.
-
Country-wise new recovered
-
Country-wise new confirmed cases

COVID-19 data will be pushed to the Kafka topic and HDFS using NiFi. The data will be processed and analyzed in the PySpark cluster and ingested to the Hive database. Finally, this data will be published as data Plots using Visualization tools like Tableau and Quicksight.
Insert Video: https://www.youtube.com/watch?v=q8QTgmU07jg
Tech Stack: NiFi, PySpark, Hive, HDFS, Kafka, Airflow, Tableau and AWS QuickSight.
Source Code: Real-World Data Engineering Project on COVID-19 Data
-
Movielens Data Analysis for Recommendations
A Recommender System is a system that seeks to predict or filter preferences according to the user's choices. Recommender systems are utilized in various areas, including movies, music, news, books, research articles, search queries, social tags, and products in general. This use case focuses on the movie recommendation system used by top streaming services like Netflix, Amazon Prime, Hulu, Hotstar, etc, to recommend movies to their users based on historical viewing patterns. Before the final recommendation is made, a complex data pipeline brings data from many sources to the recommendation engine.

In this project, you will explore the usage of Databricks Spark on Azure with Spark SQL and build this data pipeline.
-
You can download the dataset from GroupLens Research, a research group in the Department of Computer Science and Engineering at the University of Minnesota.
-
Upload it to Azure Data Lake storage manually.
-
Create a Data Factory pipeline to ingest files. Then, use databricks to analyze the dataset for user recommendations.
This straightforward data engineering pipeline architecture allows exploring data engineering concepts and confidence to work on a cloud platform.
Tech Stack: Databricks, Spark SQL, Microsoft Azure- Azure Data Lake, Azure Data Factory, Azure Blob Storage.
Source Code: Analyse Movie Ratings Data
-
Retail Analytics Project Example
For retail stores, inventory levels, supply chain movement, customer demand, sales, etc. directly impact the marketing and procurement decisions. They rely on Data Scientists who use machine learning and deep learning algorithms on their datasets to improve such decisions, and data scientists have to count on Big Data Tools when the dataset is huge. So, if you want to understand the retail stores’ analytics and decision-making process, check out this project.
This projects aims to analyse dataset of a retail store to support its growth by enhancing its decision-making process. You will get an idea of working on real-world data engineering projects through this project. You will use AWS EC2 instance and docker-composer for this project. You will learn about HDFS and the significance of different HDFS commands. You will be guided on using Sqoop Jobs and performing various transformation tasks in Hive. You will set up MySQL for table creation and migrate data from RDBMS to Hive warehouse to arrive at the solution.
Tech Stack: SQL, Bash, AWS EC2, Docker, MySQL, Sqoop, Hive, HDFS
Source Code: Retail Analytics Project Example using Sqoop, HDFS, and Hive
Data Engineering Projects on GitHub
This section boasts an intriguing list of data engineering projects with full source code available on GitHub.
-
Real-time Financial Market Data Pipeline with Finnhub API and Kafka
This project aims to build a streaming data pipeline using Finnhub's real-time financial market data API. Its architecture primarily comprises five layers: Data Ingestion, Message broker, Stream processing, Serving database, and Visualization. The result is a dashboard that displays data in a graphical format for deep analysis.
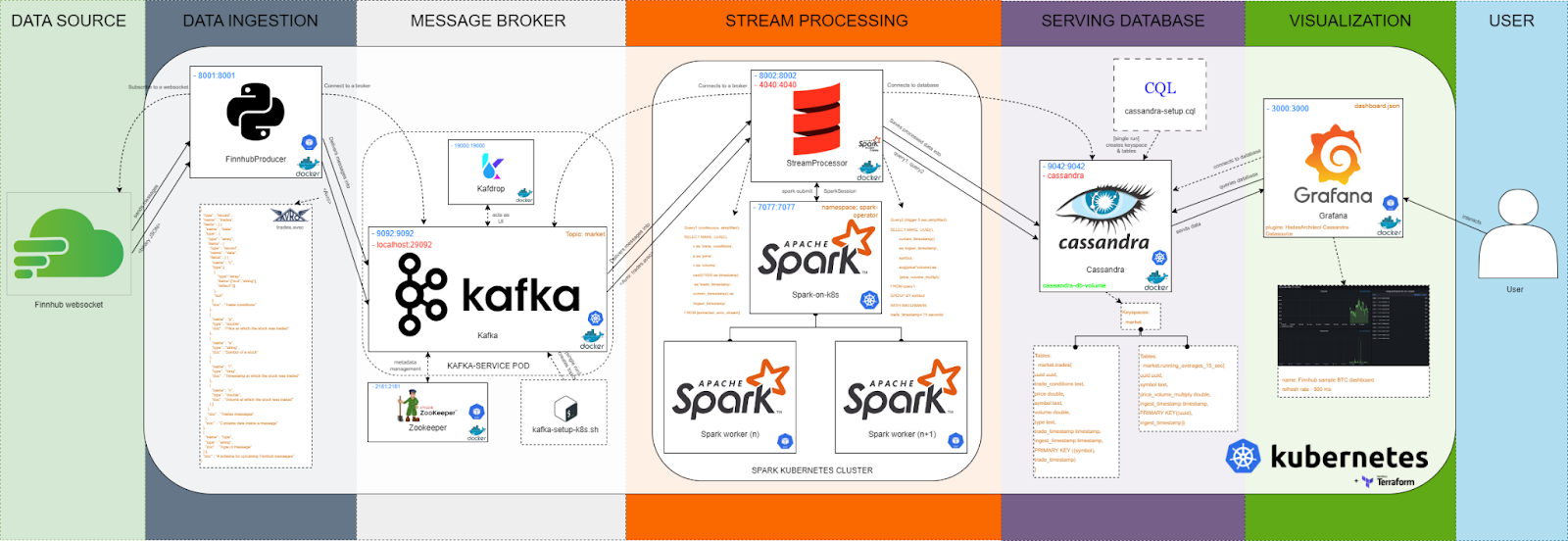
The pipeline includes several components, including a producer that fetches data from Finnhub's API and sends it to a Kafka topic, a Kafka cluster for storing and processing the data. For stream processing, Apache Spark will be used. Next, Cassandra is used for storing the pipeline's financial market data that is streamed in real-time. Grafana is used to create the final dashboard that displays real-time charts and graphs based on the data in the database, allowing users to monitor the market data in real-time and identify trends and patterns. This is one of the simplest Spark projects for data engineers, so do not sleep on it.
Tech Stack: Apache Kafka, Apache Spark, Python, Kubernetes, Grafana
GitHub Repository: Finnhub Streaming Data Pipeline by RSKriegs
-
Real-time Music Application Data Processing Pipeline
In this project, you will use the data of Streamify, a fake platform for users to discover, listen and share music online. The aim is to build a data pipeline that intakes real-time data and stores it in data lake every two minutes.

With the help of the Eventism and Million Songs dataset, you can create a sample dataset for this project. Apache Kafka and Apache Spark are the streaming platforms used for real-time data processing. Spark's Structured Streaming API allows for data to be processed in real-time in mini-batches, providing low-latency processing capabilities. The processed data is stored in Google Cloud Storage and is transformed with the help of dbt. Using dbt, we can clean, transform, and aggregate the data to make it suitable for analysis. The data is then pushed to the data warehouse- BigQuery, and finally, the data is visualized using Data Studio. For orchestration, Apache AirFlow has been used, and for containerization, Docker is the preferred choice.
Tech Stack: Apache Kafka, Apache Spark, GCP, Docker, Apache Airflow, Terraform
GitHub Repository: A data engineering project with Kafka, Spark Streaming, dbt, Docker, Airflow, Terraform, GCP by Ankur
-
Shipping and Distribution Demand Forecasting
This one of the best data engineering projects for beginners and it uses historical demand data to forecast demand for the future across various customers, products, and destinations. A real-world use case for this data engineering project is when a logistics company wants to predict the quantities of the products customers want delivered at various locations. The company can use demand forecasts as input to an allocation tool. The allocation tool can then optimize operations, such as delivery vehicle routing and planning capacity in the longer term. A related example is when a vendor or insurer wants to know the number of products that will be returned because of failures.

This data engineering project uses the following big data stack -
-
Azure Structured Query Language (SQL) Database instance for persistent storage; to store forecasts and historical distribution data.
-
Machine Learning web service to host forecasting code.
-
Blob Storage for intermediate storage of generated predictions.
-
Data Factory to orchestrate regular runs of the Azure Machine Learning model.
-
Power BI dashboard to display and drill down the predictions.
Tech Stack: Azure SQL, Azure Machine Learning, Azure Data Factory, Power BI, Azure Blob Storage
GitHub Repository: Shipping and Distribution Forecasting
Advance Data Engineering Projects for Resume
Proceed with this section and experiment with projects in data engineering that will increase your chances of getting an interview call for a data engineering job.
-
Visualizing Reddit Data
Extracting data from social media platforms has become essential for data analysis and decision-making. Reddit, being a vast community-driven platform, provides a rich data source for extracting valuable insights. 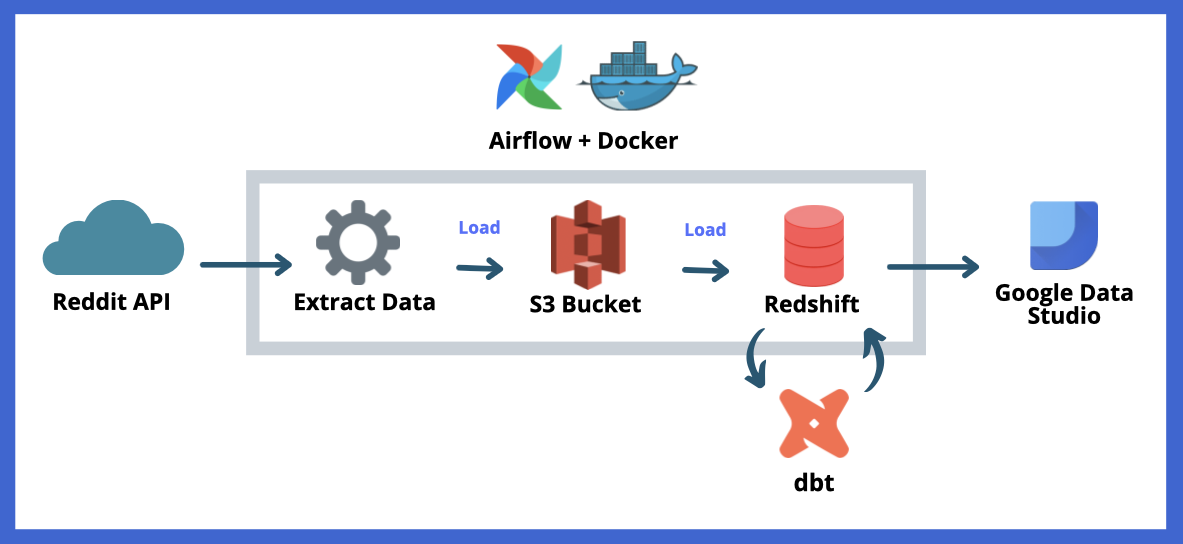
The first step in this project is to extract data using the Reddit API, which provides a set of endpoints that allow users to retrieve data from Reddit. Once the data has been extracted, it needs to be stored in a reliable and scalable data storage platform like AWS S3. The extracted data can be loaded into AWS S3 using various ETL tools or custom scripts. Once the data is stored in AWS S3, it can be easily copied into AWS Redshift, a data warehousing solution that efficiently analyzes large datasets. The next step is to transform the data using dbt, a popular data transformation tool that allows for easy data modeling and processing. dbt provides a SQL-based interface that allows for easy and efficient data manipulation, transformation, and aggregation. After transforming the data, we can create a PowerBI or Google Data Studio dashboard to visualize the data and extract valuable insights. To orchestrate the entire process, this project uses Apache Airflow.
Tech Stack: Reddit API, AWS S3, Amazon RedShift, dbt, Google Data Studio, Apache Airflow
Source Code: GitHub - ABZ-Aaron/Reddit-API-Pipeline
-
Analyzing data from Crinacle
Scraping data from Crinacle's website can provide valuable insights and information about headphones and earphones. This data can be used for market analysis, product development, and customer segmentation. However, before any analysis can be conducted, the data needs to be processed, validated, and transformed. This is where a data pipeline comes in handy.
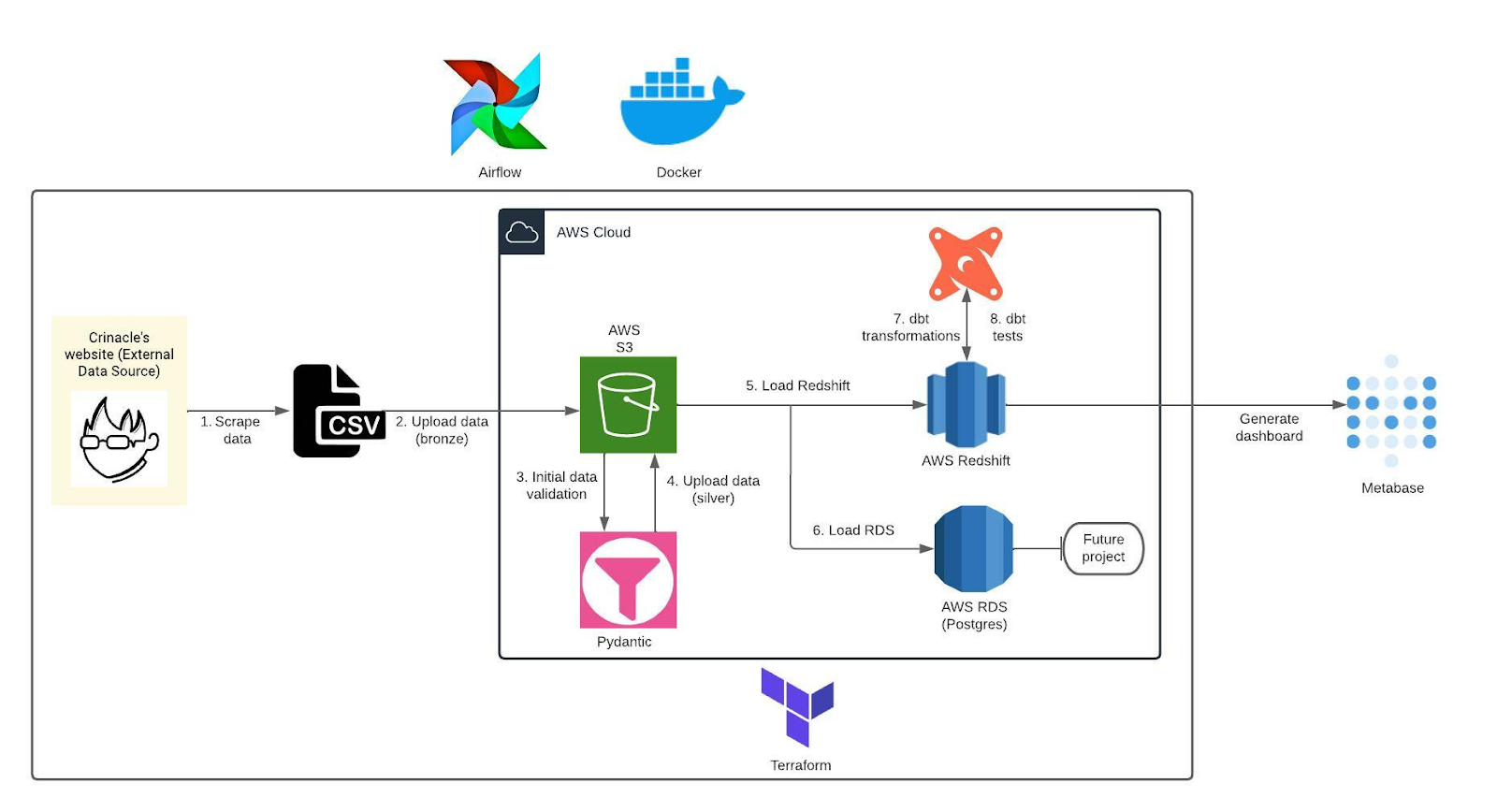
The first step in the data pipeline is to scrape data from Crinacle's website. This can be done using web scraping tools like Beautiful Soup or Scrapy. The data can then be stored in a CSV or JSON format and loaded to AWS S3 for storage. Once the data is loaded to AWS S3, it must be parsed and validated. Pydantic is a Python library that can be used for data validation and serialization. By defining data models using Pydantic, we can ensure that the data is in the correct format and structure. The parsed and validated data is then transformed into silver data, ready for analysis. The silver data can be loaded to AWS S3 for storage and backup. The silver data can also be loaded to AWS Redshift, a data warehouse that enables fast querying and analysis of large datasets. AWS RDS can also store the silver data for future projects. Finally, the data must be transformed and tested using dbt (data build tool). dbt is a tool that enables data analysts and engineers to build and manage data pipelines in a modular and scalable way. With dbt, we can transform the silver data into an optimized format for analysis and testing.
Tech Stack: AWS S3, Python, AWS RDS, AWS RedShift, AWS S3, Terraform, dbt
-
Live Twitter Sentiment Analysis
When it comes to influencing purchase decisions or finding people’s sentiment toward a political party, people’s opinion is often more important than traditional media. It means that there is a significant opportunity for brands on Twitter. The Twitter sentiment is a term used to define the analysis of sentiments in the tweets posted by the users. Generally, Twitter sentiment is analyzed in most big data projects using parsing. Analyzing users’ sentiments on Twitter is fruitful to companies for product that is mostly focused on social media trends, users' sentiments, and future views of the online community.

The data pipeline for this data engineering project has five stages - data ingestion, NiFi GetTwitter processor that gets real-time tweets from Twitter and ingests them into a messaging queue. Collection happens in the Kafka topic. The real-time data will be processed using Spark structured streaming API and analyzed using Spark MLib to get the sentiment of every tweet. MongoDB stores the processed and aggregated results. These results are then visualized in interactive dashboards using Python's Plotly and Dash libraries.
Tech Stack: MongoDB, Apache Kafka, Python, Apache Spark, NiFi
Source Code: Live Twitter Sentiment Analysis with Spark
-
Website Monitoring
Website Monitoring is used to describe any activity which involves testing a website or any web service for its availability, performance, or function. It’s the process of testing and also verifying that the end-users can interact with the website or the web application as expected. The Website Monitoring service checks and verifies that the website is up and working as expected, and website visitors can use the site without facing any difficulties.

In this AWS project, Amazon EC2 is a website backend generating server logs; Kinesis Datastreams read the logs and push them to Kinesis Analytics. The second stream receives alarms based on the analyzed data and triggers Lambda. Lambda triggers an SNS notification to deliver a message, and the data is saved in Aurora DB.
Tech Stack: Amazon EC2, Kinesis, SNS, Aurora, Lambda
Source Code: Website Monitoring using AWS Services with Source Code
-
Bitcoin Mining
Bitcoin Mining is a critical component of maintaining and developing the blockchain ledger. It is the process in which new bitcoins are entered into rotation. It is performed using sophisticated computers that solve complex math problems. In this data engineering project, you will apply data mining concepts to mine Bitcoin using the freely available relative data.

This is a straightforward project where you will extract data from APIs using Python, parse it, and save it to EC2 instances locally. After that, upload data onto HDFS. Then read the data using Pyspark from HDFS and perform analysis. The techniques explained in this use case are the usage of Kryo serialization and Spark optimization techniques. An External table will be created on Hive/Presto, and at last, for visualizing the data we will use AWS Quicksight.
Tech Stack: Amazon EC2, Apache HDFS, Python.
Source Code: Top Data Engineering Project with Source Code on BitCoin Mining
-
How to deal with slowly changing dimensions?
Slowly changing dimensions (SCDs) are attributes in a dataset whose values have been amended over a long time and are not updated regularly. Examples of SCDs include geographical location, employees, and customers. There are various great ways of amending the values for SCDs, and in this project, you will learn how to implement those methods in a Snowflake Datawarehouse. Snowflake provides multiple services to help you create an effective data warehouse with ETL capabilities and support for several external data sources.
Data Description
This project uses Python's faker package to generate user data and store them in CSV format with the user's name and the current system time.
The data contains the following details:
-
Customer_id
-
First_name
-
Last_name
-
Email
-
Street
-
State
-
Country
Tech Stack: Python3, JavaScript, SQL, Faker, NiFi, Amazon S3, Snowflake, Amazon EC2, Docker
Source Code: How to deal with slowly changing dimensions using Snowflake?
-
GCP Project to Explore Cloud Functions
The market's three popular cloud service providers are Amazon Web Services, Microsoft Azure, and GCP. Big Data Engineers often struggle with deciding which one will work best for them, and this project will be a good start for those looking forward to learning about various cloud computing services and who want to explore whether GCP is for them or not. The project’s objective is to understand the significant services of the GCP, including Cloud Storage, Cloud Engineer, and PubSub.
This project will introduce you to the Google Cloud Console. You will learn how to create a service account on the GCP and understand cloud storage concepts. You will be guided on setting up a GCP Virtual machine and SSH configuration. Another exciting topic you will learn is Pub/Sub Architecture and its application.To learn more about GCP, check out GCP Roadmap: Your Learning Path to Google Cloud Excellence.
Tech Stack: Language: Python3, Cloud Storage, Cloud Engine, Pub/Sub
Source Code: GCP Project to Explore Cloud Functions using Python
Azure Data Engineering Projects
Let us discuss a few Azure Data Engineer projects for your practice to understand how Azure services areused by data engineers for everyday tasks.
-
Yelp Data Analysis
The Yelp dataset consists of data about Yelp's businesses, user reviews, and other publicly available data for personal, educational, and academic purposes. Available as JSON files, use it to learn NLP for sample production data. This dataset contains 6,685,900 reviews, 192,609 businesses, and 200,000 pictures in 10 metropolitan areas. This Azure project helps you understand the ETL process, i.e., how to ingest the dataset, clean it, and transform it to get business insights. Also, you can explore Azure Databricks, Data Factory, and Storage services.

There are three stages in this real-world data engineering project. Data ingestion: In this stage, you get data from Yelp and push it to Azure Data Lake using DataFactory. The second stage is data preparation. Here, data cleaning and analysis happen using Databricks. The final step is Publish. In this stage, whatever insights we drew from the raw Yelp data will be visualized using Databricks.
Tech Stack: Azure Data Lake, Azure DataFactory, Databricks,
Source Code: Analyse Yelp Dataset with Spark & Parquet Format on Azure Databricks
-
Data Governance
An organization planning to leverage data as a resource must perform multiple operations, including cleaning, securing, transforming, etc. However, it is important to wonder how an organization will achieve the same steps on data of different types. The answer is to design standard policies and processes to ensure consistency.
Microsoft introduced Azure Purview, a data governance tool that lets users better manage data. In this project, you will learn how to use this tool as a beginner, manage the ingested data, and implement data analysis tools to draw insightful conclusions.
Tech Stack: Azure Logic Apps, Azure Storage Account, Azure Data Factory, Azure SQL Databases, DBeaver, Azure Purview
Source Code: Getting Started with Azure Purview for Data Governance
-
Real-time Data Ingestion
Many businesses realize the potential of data as a resource and invest in learning new ways to capture user information and store it. Intending to store information comes with the responsibility to keep it safe. That is why real data warehouses are often away from offices and located where a high level of security is ensured. This produces another challenge: the task of sourcing data from a source to a destination, or in other words, the task of data ingestion.

Project Idea: This project is a continuation of the project mentioned previously. It will use the same tool, Azure Purview, to help you learn how to ingest data in real time. You will explore various Azure apps like Azure Logic Apps, Azure Storage Account, Azure Data Factory, and Azure SQL Databases and work on a hospital dataset that has information for 30 different variables.
Tech Stack: Azure Purview, Azure Data Factory, Azure Logic Apps
Source Code: Learn Real-Time Data Ingestion with Azure Purview
To master Microsoft Azure services further, check out Azure Roadmap:Elevating Your Cloud Skills from Novice to Pro.
AWS Data Engineering Project Ideas
We will now discuss a few data engineering project ideas that only leverage Amazon Web Services and related products.
-
ETL Pipeline
Sales data helps with decision-making, understanding your customers better, and improving future performance within your organization. Sales leaders must know how to interpret the data they collect and use its insights to improve their strategy. This data engineering project has all the data engineering knowledge a data engineer should have. It includes analyzing sales data using a highly competitive technology big data stack such as Amazon S3, EMR, and Tableau to derive metrics from the existing data. Finally, Tableau visualizes the cleansed and transformed data as various plots.
-
Units Sold vs. Units cost per region
-
Total revenue and cost per country
-
Units sold by Country
-
Revenue vs. Profit by region and sales Channel

Get the downloaded data to S3 and create an EMR cluster consisting of a hive service. Create an external table in Hive, perform data cleansing and transformation operations, and store the data in a target table. Finally, this data is used to create KPIs and visualize them using Tableau.
Tech Stack: Apache HDFS, Apache Hive, Tableau, Amazon S3
Source Code: ETL Pipeline on AWS EMR Cluster
-
Data Integration
Just like investing all your money in a single mode of investment isn’t considered a good idea, storing all the data in one place isn’t considered good either. Often, companies store precious information at multiple data warehouses across the world. This poses the task of accumulating data from multiple sources, which is called data integration.

The project idea is to integrate data from different sources, data engineers use ETL pipelines. In this project, you will work with Amazon’s Redshift tool for performing data warehousing. Additionally, you will use tools like AWS Glue, AWS Step Function, VPC, and QuickSight to perform end-to-end sourcing of data and its analysis.
Tech Stack: AWS Glue, VPC, QuickSight
Source Code: Orchestrate Redshift ETL using AWS Glue and Step Functions
-
ETL and ELT Operations
One of the most important tasks of a data engineer is to build efficient pipelines that can transfer data from multiple sources to destinations and transform them into a form that allows easy management. These pipelines involve many ETL (Extract, Transform and Load) and ELT (Extract, Load, and Transform) operations that a data engineer must know.
Work on a data engineering project to learn how to perform ETL and ELT operations using Apache Cassandra and Apache Hive with PySpark. Use Amazon Redshift for creating clusters that will contain the database and its tables. Ensure that you learn how to integrate PySpark with Confluent Kafka and Amazon Redshift.
Tech Stack: Apache Cassandra, Apache Hive, Amazon Redshift, PySpark, PySpark
Source Code: Build a Data Pipeline using Kafka and Redshift
There is a lot more to learn about using AWS for data engineering projects, explore further by looking at AWS Roadmap: Learning Path to AWS Mastery with ProjectPro.
Open-Source Projects for Data Engineers
Here are a few open-source projects in data engineering that you can contribute to.
-
Apache Spark
Apache Spark is an open-source, distributed computing system designed to process large amounts of data in a parallel and fault-tolerant manner. It provides a unified programming model for processing batch, streaming, and interactive data and supports multiple languages, including Java, Scala, Python, and R. Spark's primary abstraction is the Resilient Distributed Dataset (RDD), which represents an immutable, fault-tolerant collection of objects that can be processed in parallel across a cluster.
Spark also includes high-level APIs for machine learning, graph processing, and stream processing, making it a versatile tool for data scientists and engineers. Additionally, Spark can handle diverse data processing tasks as it can be integrated with various data sources, such as Hadoop Distributed File System (HDFS), Apache Cassandra, and Apache Kafka. Check out the Contributing to Spark page if you want to assist with this Apache project.
-
Delta Lake
Delta Lake is an open-source data lake storage layer developed by Databricks and built on top of Apache Spark. It helps organizations to create reliable, scalable, and performant data lake solutions on top of Apache Spark. It supports ACID transactions, schema enforcement, and data versioning to big data workloads. The ACID transactions ensure that data operations are Atomic, Consistent, Isolated, and Durable. It means that different people can simultaneously edit data without corrupting it. Schema enforcement assists in ensuring the data quality and reliability of data pipelines. With data versioning, data scientists can look at different versions of the data and roll back to previous versions if necessary. Additionally, with Delta Lake, users can query data at any point and edit data pipelines. If you are curious about all these features and want to know how you can contribute to Delta Lake, check out the Contributing to Delta Lake page.
-
Apache Cassandra
Apache Cassandra is a distributed NoSQL database management system that can handle large amounts of data across many commodity servers. Cassandra can handle large amounts of data across multiple data centers and cloud regions with its decentralized architecture and no master node. The absence of a master node ensures that all nodes are equal and communicate with each other, resulting in data consistency. Cassandra supports flexible schema management, allowing columns to be added or removed dynamically without disrupting the system's availability. Cassandra provides high write and read throughput and can handle large amounts of data. It is popular for use cases that require fast, scalable, and highly available data storage, such as real-time analytics, recommendation engines, and Internet of Things (IoT) applications. If you want to know how you can contribute to this project by Apache, check out Contributing to Cassandra page.
After working on these data engineering projects, you must prepare a good data engineering project portfolio that accurately summarizes all your skills. So, read the next section to learn how to build a successful project portfolio.
How to build a Data Engineering Portfolio?
Adding Data Engineering projects to your resume is important to stand out from other candidates in your job applications. Here are a few options for adding data engineering projects to your resume.
-
LinkedIn
Using LinkedIn for networking is pretty common, but you can also create your data engineering project portfolio. Write a LinkedIn article about your projects and feature it on your profile. Add the article link to your resume to showcase it to recruiters.
-
Personal Website
Try platforms like GoDaddy to create a personal website. You can decide the look of the website and present your projects. Ensure that the website has a simple UI and can be accessed by anyone. Do not use complex graphics, as it may increase load time. Keep your portfolio short and crisp.
-
GitHub
GitHub is another perfect solution for building a project portfolio. It allows users to add all the files related to your project's folders and showcase their technical skills. Add all the relevant information in the readme file to make your portfolio user-friendly.
The data engineering projects mentioned in this blog might seem challenging and if you are not familiar with the different platforms used, the projects can be even more challenging. But no need to worry as we have the perfect solution for you in the next section.
Build your Data Engineer Portfolio with ProjectPro!
Unlocking the potential of data engineering projects is crucial in staying ahead in the dynamic tech landscape. As highlighted by Ben Lorica in his interview with DataNami, 'There’s about the same number of sessions on data engineering and architecture as data science and machine learning, but the data engineering and architecture [sessions] in the past would have been more Hadoop-focused. Now there’s a lot of cloud. There are a lot of projects that are not Hadoop. Besides Spark and Kafka, there are a lot streaming and real-time projects. There are a lot of sessions on…how do you architect data platforms and data pipelines, how do you architect in the cloud and on-premise.' Traditional Hadoop-centric approaches are making way for cloud-based solutions and real-time projects. To keep pace with such kind of advancements, platforms like ProjectPro offer a comprehensive repository of hands-on projects in Data Science and Big Data. With guided videos and mock interview sessions, ProjectPro ensures learners stay updated and well-prepared for the job market.
FAQs on Data Engineering Projects
1. Where can I practice Data Engineering?
To practice Data Engineering, you can start by exploring solved projects and contributing to open-source projects on GitHub, such as the Singer and Airflow ETL projects.
2. How do I create a Data Engineer Portfolio?
You can create a Data Engineer Portfolio by hosting your contributions on websites like GitHub. Additionally, write a few blogs about them giving a walkthrough of your projects.
3. How to Start your First Data Engineering Project?
A practical data engineering project has multiple components. To Start your First Data Engineering Project, follow the below checklist -
-
Have a clear understanding of the data that is meant to be collected.
-
Identify big data tools that will best work with the given data type.
-
Prepare a layout of the design of pipelines.
-
Install all the necessary tools.
-
Prepare the infrastructure and start writing the code accordingly.
-
Test the design and improve the implementation.
4. What are the real-time data sources for data engineering projects?
You can leverage real-time data sources for data engineering projects with the help of Twitter's official API, REST API, and Meetup for streaming event comments, photos, etc.
5. Why should you work on a data engineering project?
If you are interested in pursuing data engineering as a career, working on a data engineering project is a must. It will help you understand how the industry works and give you a real-world perspective on how practical problems can be solved.
6. How do we optimize the performance of the data pipeline?
Here are a few points that you can follow to optimize the performance of the data pipeline:
-
Resort to simultaneous data flow instead of sequential execution.
-
Use methods to ensure data quality at different stages in the pipeline.
-
Try to build pipelines that can be reused for different applications.
When building data pipelines, create documentation so other team members can easily understand the code.
About the Author

ProjectPro
ProjectPro is the only online platform designed to help professionals gain practical, hands-on experience in big data, data engineering, data science, and machine learning related technologies. Having over 270+ reusable project templates in data science and big data with step-by-step walkthroughs,