How to manage and schedule dbt
The most complete guide about everything you need to know when you manage and schedule dbt. It features an exhaustive list of solutions.
Table of Contents
Last week dbt Labs decided to change the pricing of their Cloud offering. I've already analysed this in week #22.50 of the Data News. In a nutshell, dbt Cloud pricing is per seat based, which means you pay for each dbt developer. Previously for a team it was $50/month/dev and they increase to $100/month/dev, a 100% increase with a team limit of 8 devs and only one project. To overpass this limit you'll need to take the Enterprise pricing which is opaque as all pricing of this kind.
But this article is not about the pricing which can be very subjective depending on the context—what is 1200$ for dev tooling when you pay them more than $150k per year, yes it's US-centric but relevant.
Let's go deeper than this to list what are today the options out there to schedule dbt in production. We will also cover what it means to manage dbt1. This article will be written like a guide that aim to be exhaustive by listing all the possible solutions but if you feel I missed something do not hesitate to ping me.
dbt, a small reminder
Everyone—incl. me—is speaking about dbt, but what the heck is dbt. In simple words dbt Core is a framework that helps you organise all your warehouse transformation. The framework usage grew a lot over the last years. It's important to say that a lot of the usages we have today have not been initially designed by Fishtown Analytics.
At first dbt transformations were only SQL queries, but in the recent version with supported warehouse it has been possible to add Python transformations. dbt responsibility is to transform the collection of queries into an usable DAG. The dependencies between the queries are humanly defined—which means prone to error—thanks to 2 handful function source and ref. These 2 functions are called macros because they use Jinja, a Python templating engine, in dbt macros transform Python+SQL code in SQL, we can say that we have templated queries.
Everything I just mention before we can consider it static. If we do a parallel with software development, this is your codebase. Python and SQL together in the dbt framework is your codebase. You can do development on your codebase. In order to go in production you'll have to manage and schedule dbt.
To manage dbt you will have to answer multiple questions, but mainly dbt management is how the data team develop on dbt, how the project is validated/deployed, how you get alerted when something goes wrong, how you monitor.
In addition the dbt management you will have to find the place where dbt will be scheduled. Where dbt will run. dbt scheduling is tricky but not really complicated. If you followed what we've just seen dbt is in a SQL queries orchestrator. dbt does not run the queries, all the queries are sent to the underlying warehouse, which means that theoretically dbt does not need a lot of computing power—CPU/RAM—because he is only sending SQL queries sequentially to your data warehouse which does the work.
Obviously every dbt project has been designed differently but if we simplify the workflow all dbt project will need at some point to run one or multiple dbt CLI commands.
In this guide we will first see how we can manage dbt, i.e. git structures, how to code, the CI/CD and the deployment then in the second part how we schedule dbt code,i.e. on which server and triggers.
How to manage dbt 🧑🔧

One of the dbt founding principle is to bring software engineering practices to the data development work, especially into SQL development world. In order to follow-up on this we will try to treat the workflow like an engineering project, even if sometimes it could feel over-engineered.
You have to consider development and deployment when managing dbt project(s):
- Like every engineering project the management will obviously start with a git repository—depending on your scale it can be multiple repositories, but if you're just starting I recommend you to go with a single one.
- The next step is the development experience. What we often call DevEx. Sometimes data teams forget it. In order to understand this point we have to ask ourselves who are the dbt developers and what do they need.
- After development often comes deployment. It can be deployment in all environment or as a lot of data only in production, because only production exists. But before sending your code to production you still want to validate some stuff, static or not, in the CI/CD pipelines.
Git repositories considerations
This is the everlasting debate of every software engineering team, monorepo or multirepo? This is tightly linked to another dbt related question which is mono-project or multi-project. By default and by design dbt is meant to work with mono-project, but when you're starting to grow or when you want to have clear domain borders the single project can quickly reach limits.
As I said previously if you're just starting with dbt and you're a small team I still recommend you to go with one repo one project. Try first to organise correctly the models folder before trying to structure at a higher level.
The first question you'll probably hit is: how do I put models in different schema/datasets? This is the first step of project organisation. The solution is to override the generate_schema_name macro.
Then if you want to go for multiple projects you'll maybe have to decide how you do the interface between multiple projects, within the dbt toolkit you have 2 solutions:
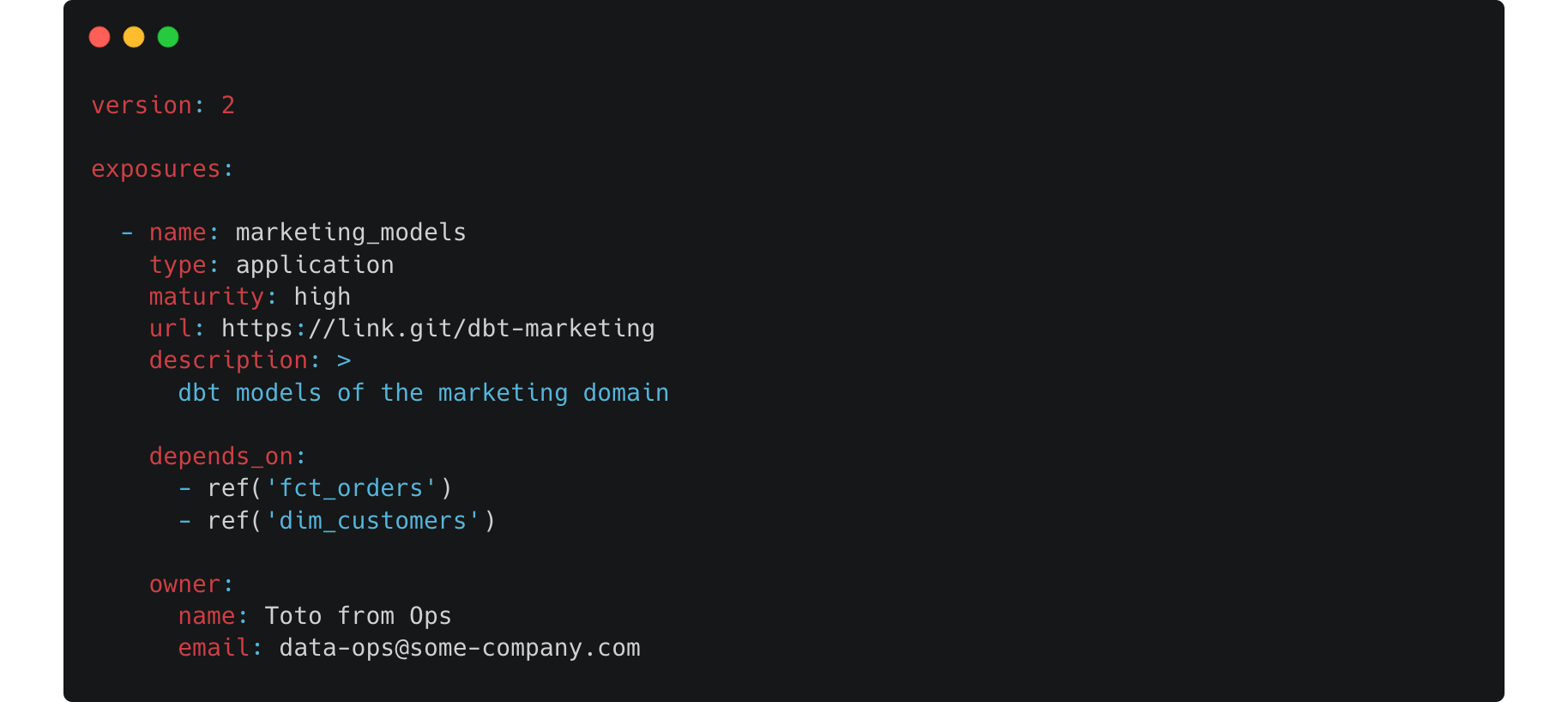
- Every project can define exposures2. Exposures are then a way to define a downstream usage of models in the project. With the exposure nomenclature you can regroup multiple models in the depends_on for an type:application that is supposed to use them. If we imagine some-company, with 2 projects—domains—Ops and Marketing we can have in the Ops exposures the models that we want the outside to be aware of define in it. Then with some kind of automation we can generate sources accordingly in the Marketing project. summarized everything here, to go further GoDataDriven team did an awesome talk at Coalesce explaining how you can achieve this: dbt & data mesh: the perfect pair (?).
- The other solution is to go for a dbt packages structure. In this solution every project—domain—can be installed as a dep in other projects, but I think it will end up in a nightmare of dependencies management. In addition you'll have to be smart in the way you run the models in the end because packages installation could duplicate models execution.
Once project/repo structure has been defined there are still open questions, here are a few:
- How do I structure my dbt models folder? You can opt for the dbt recommended solution or for Brice's recommendations. Personally here my only advice is: don't be shy to create folders to separate concerns.
- One YAML to rule them all — Do you want to create only one big YAML file that describe all the sources and all the models or do you split it. In my opinion sources have to be at schema/database level and YAML models have to be at the model level. So it means one YAML per SQL file.
- Who is the real owner of the git repo? Data engineering or analytics team? — It depends but I'm in favour if possible to give the responsibilities and ownership to the analytics team, dbt is their playground, as a data—platform—engineer it's your responsibility to help them, but it's up to them to learn by doing. Under the hood it also means that dbt project(s) have to be independent(s) from other tools (e.g. dbt repo should not be in the Airflow repo).
Development Experience with dbt
First important thing to say. I'm a data engineer and I truly think that my main mission when in a data team is to empower others through data tools. In the dbt context it means you have to understand how your analytics team is working. I've also noticed over the years that analytics teams are often not able to identify that they are under-equipped or doing something that is not efficient. This is your role as data engineer to identify these issues. This is your role to provide a neat developer experience for every dbt users.
But who are your dbt users?
- They can be data engineers—working on the founding layers of the modelisation. Probably the sources and the staging tables.
- They can be analytics engineers—doing the same as data engineers in the previous point and going deeper in the modelisation layer into the core, intermediate and mart models.
- They can be data analysts, business analysts, web analysts—people using the final mart models, sometimes also doing it. They mainly want to be able to understand from where or how a column is computed or do small changes. They also need a place to store their analyses or all the modelisations they were doing before in their BI tool, which is often their main playground.
- Management roles (head of data, VP tech, etc.)—they want to be sure dbt is the right tool but also they want to take a higher view on the modelisation, dbt docs are sometimes a good first entry point for them.
- Stakeholders—not sure they are dbt users, dbt is too technical, and you don't want them to see the whole complexity that exists in it.
Now that we listed a few of the dbt users, let's focus on the development experience, especially for analytics team—analytics engineers and data analysts. This is super important to provide a smooth experience for these users because they will spend a lot of working hours in the models, the neater the workflow is, the happier people will be.
What are the levers you can act on to provide this great experience: