Enhancing Efficiency: Robinhood’s Batch Processing Platform

Robinhood was founded on a simple idea: that our financial markets should be accessible to all. With customers at the heart of our decisions, Robinhood is lowering barriers and providing greater access to financial information and investing. Together, we are building products and services that help create a financial system everyone can participate in.
…
Authored by: Grace L., Chandra K. and Sreeram R. from Robinhood Data Infrastructure
Robinhood adheres to a data-first philosophy. Every decision we make here (or every decision at the company), from feature rollouts to operational changes, is backed by data. When dealing with large-scale data, we turn to batch processing with distributed systems to complete high-volume jobs. In this blog, we explore the evolution of our in-house batch processing infrastructure and how it helps Robinhood work smarter.
Why Batch Processing is Integral to Robinhood
Why is batch processing important? Consider some of the practical data applications we use at Robinhood –
- Experimentation: Batch processing creates metrics for A/B testing, resulting in more accurate outcomes and aiding data driven product development.
- Clearing: Batch processing ensures accurate, compliant, and fast end-of-day reporting.
- Product reporting: Batch processing generates end-of-day/month/year reports which includes transaction statements and tax documents for various products.
- Data science: Batch processing builds datasets that form the backbones of our analytics pipelines and visualization dashboards.
We empower our developers, data engineers, operations, and data scientists to build structured, repeatable, and reliable batch data pipelines securely and efficiently.
Hadoop-Based Batch Processing Platform (V1)
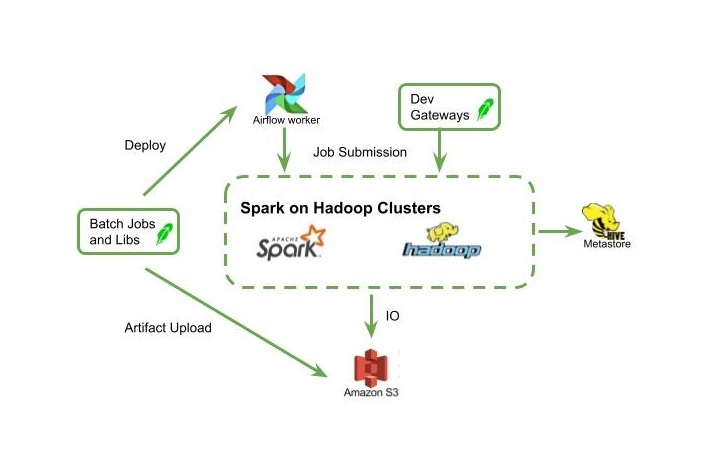
Initial Architecture
In our early days of batch processing, we set out to optimize data handling for speed and enhance developer efficiency. Our V1 batch processing architecture was robust, anchored by Apache Spark on multiple Hadoop clusters (Spark is known for effectively handling large-scale data processing). We chose Apache Airflow for workflow management, Amazon (AWS) S3 for cloud-based storage, and Hive Metastore as our data catalog.
Job Submission Process
The job submission process was key. For production jobs, we built libraries to trigger spark-submit from Airflow workers packaged with application code. For one-off jobs, we provided access through development gateways. This allowed for a balance between scheduled jobs and spontaneous data analysis.
Navigating Limitations
While our V1 batch processing architecture laid a strong foundation, we encountered several limitations and learned valuable lessons.
These were the key areas where we faced challenges:
- User development: Users needed to login into development gateway machines for testing jobs, which was inconvenient and raised security concerns. Tracking job runs was also cumbersome because it required navigating multiple cluster UIs.
- Access controls: Our uniform data access policy for all users limited data management and posed compliance risks.
- Diverse workloads and use cases: Our platform struggled with a growing diversity of batch processing needs, from handling various workload types to enabling different job invocation methods. We encountered several use cases highlighting the need for a more programmable and responsive job submission mechanism, such as –
- Audience targeting: a requirement for triggering jobs programmatically based on user actions or service automations.
- IPO access allocations: to trigger jobs automatically based on scheduled IPOs.
- Anti-fraud rule testing: a system for the team that handles issues related to fraud to backtest new rules before production deployment.
- Accounting and ML operations: triggering end-of-day accounting jobs or running multiple partitions for ML feature backfills.
- Experimentation team: a dedicated job submission service so our experimentation methodology wouldn’t have to rely on convoluted methods to submit Spark jobs for analysis.
- Transitions to newer architectures: Keeping up with the evolution of Spark and our internal infrastructure was difficult without a centralized control plane.
- Multi-cluster management: As the number of clusters increased, more human oversight was needed to perform operations and maintenance.
- Costs and scalability: Rising costs and scalability issues posed significant challenges as we sought to manage and expand our infrastructure.
Job Management Service (JMS)
These limitations led to the development of the Job Management Service (JMS). JMS was designed to be a Spark Control Center, addressing challenges and bridging the gap between our V1 and V2 architecture.
Key Features and Goals
- Uniform APIs for Spark job management: for the creation, cancellation, and information retrieval of Spark jobs. This enables seamless interaction across clusters and backends, allowing developers and various services within our organization to invoke Spark jobs.
- Authentication and authorization support: including authentication for job triggering and the integration of user level credentials for secure S3 access.
- Smart job routing: routing jobs to different clusters based on several criteria, such as the type of workflow, job retry history, cluster health, and available resources. This promotes optimal job execution and resource utilization.
- Customized job lifecycle management: supporting customized actions and responses to job state transitions, including fallbacks and retries. This allows for more flexible job handling.
- Central governance for batch job behaviors: allowing us to set the desirable defaults for jobs across the board and block undesirable configurations.
- Dynamic change for feature rollout and configuration updates: the integration between JMS and our internal dynamic configuration system, allows us to dynamically tune and adjust settings for Spark jobs like parallelism, CPU and memory, resulting in a quick but controlled feature rollout or system behavioral change process.
- Central User interface for all jobs: a central user interface for managing and monitoring jobs, simplifying the user experience by providing a single point of access for job oversight.
Processing Platform With JMS and Kubernetes Backend (V2)
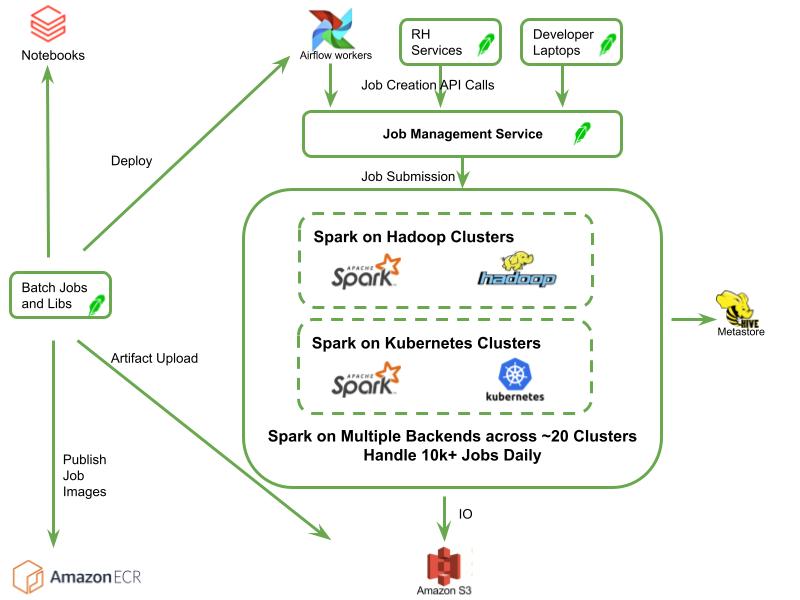
With newer architecture, JMS abstracts away the backend cluster implementation from clients, and this supports our Spark workloads transitioned to run on a multi-backend environment of Hadoop and Kubernetes (K8s). Migrating all Spark workflows over to K8s would enhance our batch processing capabilities with all the internal toolings and features we have on our K8s infrastructure and align with our overarching goal of a unified, K8s-based ecosystem at Robinhood.
While building this newer architecture, we encountered new challenges. Here’s how we tackled them.
Spark-K8s Operator Integration
Standard K8s resources, like Deployments and DaemonSets, aren’t tailored to Spark, so we adopted the Spark-K8s operator. This introduced SparkApplication as a K8s custom resource definition (CRD), creating a K8s-native environment optimized for managing the orchestration and lifecycle of Spark applications. When introducing the spark operator component we also did multiple rounds of load testing to identify some bottlenecks. Following are some of the interesting findings we had:
- With enable-ui-service config enabled, spark operator will create one additional k8s service resource for each job. When there is a large amount of jobs created in one namespace, there is a potential risk of hitting a known k8s limit of too many k8s services in one namespace which causes service discovery environment variables to be too long and leads to pods being stuck in crash loop backoff. To address this we set namespace level limits on services to de-risk the immediate larger outage and later shifted away from using enable-ui-service config.
- Spark operator starts having a delay in its actions when it needs to track more than ~3000 spark related pods. We decide to shard the operators to better balance the load on individual operator deployment.
Isolate Spark CRD Workload with Spark Control Plane
During our initial POC of the Spark-K8s integration, large CRD resources caused reliability issues on K8s storage layer etcd. Since etcd is shared across the whole K8s cluster, there was concern that Spark’s workload would impact K8s’ cluster health.
To address this, we enforced the TTL on Spark’s custom resource (CR) and introduced Spark Control Plane to store and manage the Spark CRs. A separate K8s control plane – Spark Control Plane, prevents the spark CRD workload from hindering the reliability of the main K8s cluster.
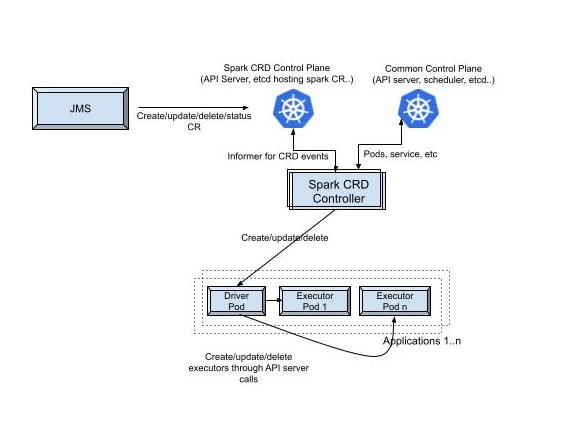
HA Setup for Spark on K8s
Now, we’d like to extend the multi-availability-zone(multi-AZ) and multi-cluster reliability and scalability we have on Hadoop to Spark on K8s. To achieve this, Spark operator and Spark Control Plane are set up on multiple K8s clusters, and JMS is upgraded to work with K8s’ CRD-based submission across multiple clusters. We also set up multiple instance groups, on different AZs, for Spark to use within each K8s cluster. Together, this mitigates risks like single-cluster outages or single-AZ outages.
Observability for Spark on K8s Jobs
On Hadoop, Spark was leveraging Hadoop’s comprehensive UI and log tracking functionalities. On K8s, however, Spark can’t accomplish this natively. So we leveraged a job portal UI built with JMS as central UI for searching a job, checking its status and finding log and history server entries
Fault Tolerant Migration Process
Benefitting from the JMS features mentioned above (see “Customized job lifecycle management” and “Dynamic change for feature rollout and configuration updates”), we were able to build a simple and safe Hadoop-to-K8s migration process, as follows:
- Spark jobs can be added to the allowlist to run on K8s or Hadoop using its job path prefixes.
- If a Spark job fails on the new K8s backend, it will automatically fallback to retry on Hadoop.
With these settings, we are able to introduce the new K8s backend without risk.
Cost Optimizations
In order to assure the ideal resource efficiency for Spark on K8s without sacrificing reliability, we’ve implemented the following setups:
- Enable K8s autoscaler: K8s cluster autoscaler (AC) is configured for each Spark instance group so that the K8s nodes serving Spark traffic will be scaled up and down based on the load.
- Ensure Spark job resiliency on scale down: To enable the aggressive auto-scale down without concern, we moved the Spark driver to a separate instance group and tagged the AC to treat driver pod as in-churnable. We also configured the graceful decommission settings for executors to make them more resilient during scale down.
- Leveraging other K8s clusters to spare resources at night: We have multiple K8s clusters in RH, some of them are mainly for supporting critical online systems. These systems usually have high traffic during market hours and lower traffic at night, which results in a decent amount of spare capacity on K8s clusters at night. On the other hand, most of the Spark batch jobs run at night. So, by shifting Spark workloads to K8s, we discovered an opportunity to better leverage that spare night capacity. A new feature was added to JMS to support automatically routing Spark jobs to online-services-specific K8s clusters after market hours and routing to offline-analytics-specific K8s clusters before market open. This helps with overall cost efficiency.
Credits
All of this is just one chapter in our batch processing platform journey. We continue to improve the platform and are always looking to be more efficient, reliable, and user-friendly. We want to thank Palanieppan M., Tiecheng S., Nan H., Mingmin X., John L., Tianyi W., Sujith K., Yujie L., Rand X., Lu Z., and many others who’ve contributed to this effort.
…
We are always looking for more individuals who share our commitment to building a diverse team and creating an inclusive environment as we continue in our journey in democratizing finance for all. Stay connected with us — join our talent community and check out our open positions!
…
“Robinhood” and the Robinhood feather logo are registered trademarks of Robinhood Markets, Inc. All other names are trademarks of and/or registered trademarks of their respective owners.
…
© 2024 Robinhood Markets, Inc.
…
3355062