Cross-Lingual End-to-End Product Search with Deep Learning
How We Built the Next Generation Product Search from Scratch using a Deep Neural Network

Senior Research Scientist
How We Built the Next Generation Product Search from Scratch using a Deep Neural Network
Product search is one of the key components in an online retail store. A good product search can understand a user’s query in any language, retrieve as many relevant products as possible, and finally present the results as a list in which the preferred products should be at the top, and the less relevant products should be at the bottom.
Unlike text retrieval (e.g. Google web search), products are structured data. A product is often described by a list of key-value pairs, a set of pictures and some free text. In the developers’ world, Apache Solr and Elasticsearch are known as de-facto solutions for full-text search, making them a top contender for building e-commerce product searches.
At the core, Solr/Elasticsearch is a symbolic information retrieval (IR) system. Mapping queries and documents to a common string space is crucial to the search quality. This mapping process is an NLP pipeline implemented with Lucene Analyzer. In this post, I will reveal some drawbacks of such a symbolic-pipeline approach, and then present an end-to-end way of building a product search system from query logs using Tensorflow. This deep learning based system is less prone to spelling errors, leverages underlying semantics better, and scales out to multiple languages much easier.
Recap: Symbolic Approach for Product Search
Let’s first do a short review of the classic approach. Typically, an information retrieval system can be divided into three tasks: indexing, parsing and matching. As an example, the next figure illustrates a simple product search system:
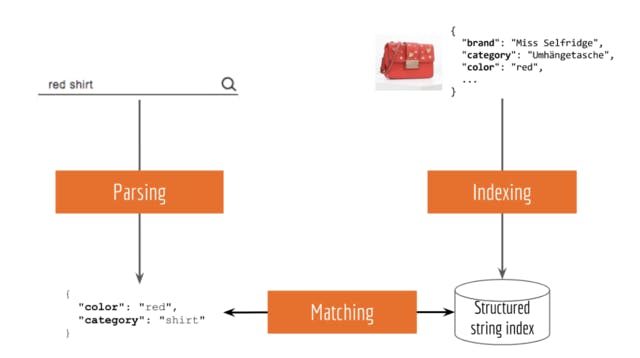
- indexing: storing products in a database with attributes as keys, e.g. brand, color, category;
- parsing: extracting attribute terms from the input query, e.g. red shirt -> {"color": "red", "category": "shirt"};
- matching: filtering the product database by attributes.
Many existing solutions such as Apache Solr and Elasticsearch follow this simple idea.Note, at the core, they are symbolic IR systems that rely on NLP pipelines for getting effective string representation of the query and product.
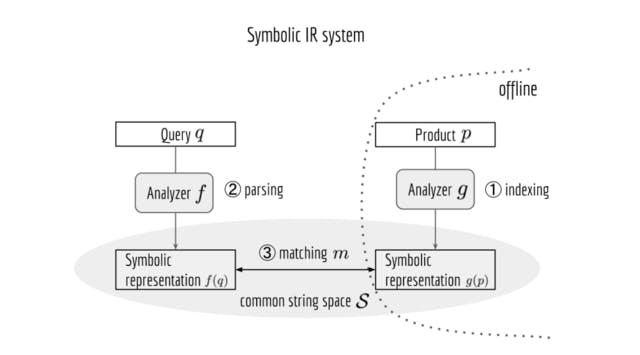
**Pain points of A Symbolic IR System **
- The NLP pipeline is fragile and doesn’t scale out to multiple languages The NLP Pipeline in Solr/Elasticsearch is based on the Lucene Analyzer class. A simple analyzer such as StandardAnalyzer would just split the sequence by whitespace and remove some stopwords. Quite often you have to extend it by adding more and more functionalities, which eventually results in a pipeline as illustrated in the figure below.
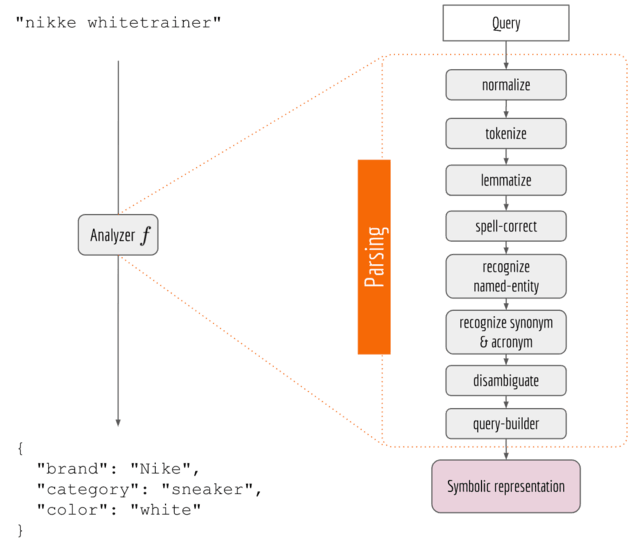
While it looks legit, my experience is that such NLP pipelines suffer from the following drawbacks:
- The system is fragile. As the output of every component is the input of the next, a defect in the upstream component can easily break down the whole system. For example, canyourtoken izer split thiscorrectly?
- Dependencies between components can be complicated. A component can take from and output to multiple components, forming a directed acyclic graph. Consequently, you may have to introduce some asynchronous mechanisms to reduce the overall blocking time.
- It is not straightforward to improve the overall search quality. An improvement in one or two components does not necessarily improve the end-user search experience.
- The system doesn’t scale out to multiple languages. To enable cross-lingual search, developers have to rewrite those language-dependent components in the pipeline for every language, which increases the maintenance cost.
2. Symbolic Systems do not Understand Semantics without Hard Coding A good IR system should understand trainer is sneaker by using some semantic knowledge. No one likes hard coding this knowledge, especially you machine learning guys. Unfortunately, it is difficult for Solr/Elasticsearch to understand any acronym/synonym unless you implement SynonymFilter class, which is basically a rule-based filter. This severely restricts the generalizability and scalability of the system, as you need someone to maintain a hard-coded language-dependent lexicon. If one can represent query/product by a vector in a space learned from actual data, then synonyms and acronyms could easily be found in the neighborhood without hard coding.
Neural IR System The next figure illustrates a neural information retrieval framework, which looks pretty much the same as its symbolic counterpart, except that the NLP pipeline is replaced by a deep neural network and the matching job is done in a learned common space.
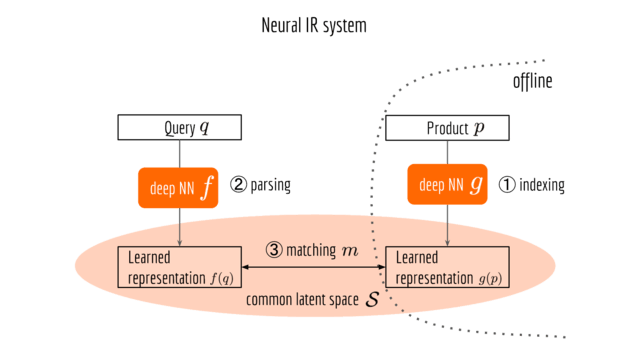
End-to-End Model Training There are several ways to train a neural IR system. One of the most straightforward (but not necessarily the most effective) ways is end-to-end learning. Namely, your training data is a set of query-product pairs feeding on the top-right and top-left blocks in the last figure. All the other blocks are learned from data. Depending on the engineering requirements or resource limitations, one can also fix or pre-train some of the components.
Where Do Query-Product Pairs Come From? To train a neural IR system in an end-to-end manner, you need some associations between query and product such as the query log. This log should contain what products a user interacted with after typing a query. Typically, you can fetch this information from the query/event log of your system. After some work on segmenting, cleaning and aggregating, you can get pretty accurate associations. In fact, any user-generated text can be good association data. This includes comments, product reviews, and crowdsourcing annotations.
Neural Network Architecture The next figure illustrates the architecture of the neural network. The proposed architecture is composed of multiple encoders, a metric layer, and a loss layer. First, input data is fed to the encoders which generate vector representations. In the metric layer, we compute the similarity of a query vector with an image vector and an attribute vector, respectively. Finally, in the loss layer, we compute the difference of similarities between positive and negative pairs, which is used as the feedback to train encoders via backpropagation.
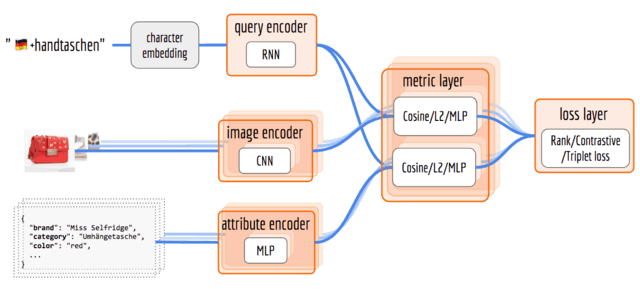
Query Encoder Here we need a model that takes in a sequence and outputs a vector. Besides the content of a sequence, the vector representation should also encode language information and be resilient to misspellings. The character-RNN (e.g. LSTM, GRU, SRU) model is a good choice. By feeding RNN character by character, the model becomes resilient to misspelling such as adding/deleting/replacing characters. The misspelled queries would result in a similar vector representation as the genuine one. Moreover, as European languages (e.g. German and English) share some Unicode characters, one can train queries from different languages in one RNN model. To distinguish the words with the same spelling but different meanings in two languages, such as German rot (color red) and English rot, one can prepend a special character to indicate the language of the sequence, e.g. 🇩🇪 rot and 🇬🇧 rot.
Image Encoder The image encoder rests on purely visual information. The RGB image data of a product is fed into a multi-layer convolutional neural network based on the ResNet architecture, resulting in an image vector representation in 128-dimensions.
Attribute Encoder The attributes of a product can be combined into a sparse one-hot encoded vector. It is then supplied to a four-layer, fully connected deep neural network with steadily diminishing layer size. Activation was rendered nonlinear by standard ReLUs, and drop-out is applied to address overfitting. The output yields attribute vector representation in 20 dimensions.
Metric & Loss Layer After a query-product pair goes through all three encoders, one can obtain a vector representation of the query, an image representation and an attribute representation of the product. It is now the time to squeeze them into a common latent space. In the metric layer, we need a similarity function which gives higher value to the positive pair than the negative pair. To understand how a similarity function works, I strongly recommend you read my other blog post on “Optimizing Contrastive/Rank/Triplet Loss in Tensorflow for Neural Information Retrieval”. It also explains the metric and loss layer implementation in detail.
Inference For a neural IR system, doing inference means serving search requests from users. Since products are updated regularly (say once a day), we can pre-compute the image representation and attribute representation for all products and store them. During the inference time, we first represent user input as a vector using query encoder; then iterate over all available products and compute the metric between the query vector and each of them; finally, sort the results. Depending on the stock size, the metric computation part could take a while. Fortunately, this process can be easily parallelized.
Qualitative Results Here, I demonstrated (cherry-picked) some results for different types of query. It seems that the system goes in the right direction. It is exciting to see that the neural IR system is able to correctly interpret named-entity, spelling errors and multilinguality without any NLP pipeline or hard-coded rule. However, one can also notice that some top ranked products are not relevant to the query, which leaves quite some room for improvement.
Speed-wise, the inference time is about two seconds per query on a quad-core CPU for 300,000 products. One can further improve the efficiency by using model compression techniques.
Query & Top-20 Results
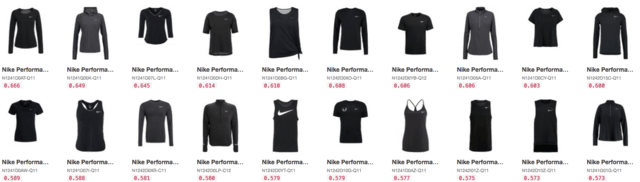
🇩🇪 nike

🇩🇪 schwarz (black)

🇩🇪 nike schwarz

🇩🇪 nike schwarz shirts

🇩🇪 nike schwarz shirts langarm (long-sleeved)
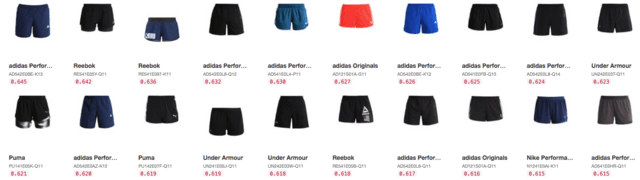
🇬🇧 addidsa (misspelled brand)

🇬🇧 addidsa trosers (misspelled brand and category)

🇬🇧 addidsa trosers blue shorrt (misspelled brand and category and property)
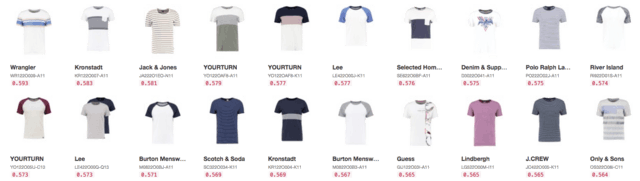
🇬🇧 striped shirts woman

🇬🇧 striped shirts man
🇩🇪 kleider (dress)

🇩🇪 🇬🇧 kleider flowers (mix-language)

🇩🇪 🇬🇧 kleid ofshoulder (mix-language & misspelled off-shoulder)

Summary If you are a search developer who is building a symbolic IR system with Solr/Elasticsearch/Lucene, this post should make you aware of the drawbacks of such a system.
This post should also answer your What?, Why? and How? questions regarding a neural IR system. Compared to the symbolic counterpart, the new system is more resilient to the input noise and requires little domain knowledge about the products and languages. Nonetheless, one should not take it as a “Team Symbol” or “Team Neural” kind of choice. Both systems have their own advantages and can complement each other pretty well. A better solution would be combining these two systems in a way that we can enjoy all advantages from both sides.
Some implementation details and tricks are omitted here but can be found in my other posts. I strongly recommend readers to continue with the following posts:
- “Optimizing Contrastive/Rank/Triplet Loss in Tensorflow for Neural Information Retrieval.”
- “Why I Use raw_rnn Instead of dynamic_rnn in Tensorflow and So Should You.”
Last but not least, the open-source project MatchZoo contains many state-of-the-art neural IR algorithms. In addition to product search, one may find its application in conversational chatbot and question-answer systems.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Applied Scientist!





