Apache Spark Vs Apache Flink – What Is The Difference?

As data increased in volume, velocity, and variety, so, in turn, did the need for tools that could help process and manage those larger data sets coming at us at ever faster speeds.
As a result, frameworks such as Apache Spark and Apache Flink became popular due to their abilities to handle big data processing in a fast, efficient, and scalable manner.
But we often find that sometimes it can be difficult to understand which use cases are best suited for Spark as well as for Flink (or even which might be suited for both).
In this article, we’ll discuss some of those unique benefits for both Spark and Flink and help you understand the difference between the two, and go over real use cases, including ones where the engineers were trying to decide between Spark vs. Flink.
Key Features of Spark and Flink
Before digging into Spark vs. Flink, we’d like to set the stage and talk about the two different solutions.
What is Apache Spark?
Apache Spark is likely the most known between Flink and Spark (or at least the most used).
One could describe both solutions as open-sourced distributed processing systems used for big data workloads.
But in particular, as AWS calls out:
“Spark utilizes in-memory caching, and optimized query execution for fast analytic queries against data of any size. It provides development APIs in Java, Scala, Python, and R, and supports code reuse across multiple workloads—batch processing, interactive queries, real-time analytics, and machine learning.” – AWS
Spark Features
- Resilient Distributed Dataset (RDD): Spark’s foundational abstraction, the RDD, provides a fault-tolerant, immutable collection of objects that can be processed in parallel across a computing cluster. RDDs offer fine-grained control over data processing, making Spark highly efficient and fault-tolerant.
- DataFrame APIs: Building on the concept of RDDs, Spark DataFrames offer a higher-level abstraction that simplifies data manipulation and analysis. Inspired by data frames in R and Python (Pandas), Spark DataFrames allow users to perform complex data transformations and queries in a more accessible way.
- Diverse Libraries:
- Spark SQL: Provides a DataFrame API that can be used to perform SQL queries on structured data.
- Spark Streaming: Enables high-throughput, fault-tolerant stream processing of live data streams.
- MLlib: Spark’s scalable machine learning library provides a wide array of algorithms and utilities for machine learning tasks.
- GraphX: A library for manipulating graphs (networks) and performing graph-parallel computations.
- Multi-Language Support: Spark supports multiple programming languages, offering APIs in Scala, Java, Python, and R. This makes Spark accessible to a wide range of developers and data scientists with different backgrounds and preferences.
What Is Apache Flink
Apache Flink is distinguished by its robust streaming data processing capabilities, making it an excellent choice for real-time analytics and applications.
Flink Features
- DataStream and DataSet APIs:
- DataStream API: Designed for unbounded and bounded data streams, Flink’s DataStream API supports stateful or stateless real-time data processing, catering to complex event-driven applications.
- FlinkSQL: Flink SQL allows the end user to use ANSI standard compliant SQL in both stream processing and batch jobs. Similar to SparkSQL.
- True Streaming Model: Flink’s core is built around a true streaming dataflow engine, meaning it processes data as soon as it arrives. This is in contrast to systems that micro-batch stream processing, providing Flink with a distinct advantage in scenarios where low latency and real-time results are critical.
- Exactly-Once Processing Semantics: Flink guarantees each record will be processed exactly once, even in the event of failures, ensuring data accuracy and consistency across distributed systems. This is crucial for applications where data integrity is paramount.
- Event Time Processing and CEP: Flink has built-in support for event time processing, allowing for accurate event ordering and timing, regardless of when the events are actually processed. The complex event processing (CEP) capabilities enable the identification of complex patterns and relationships in data streams, useful for applications like fraud detection and network monitoring.
Spark vs. Flink – Use Cases
Capital One – Switching from Spark to Flink – Spark vs. Flink
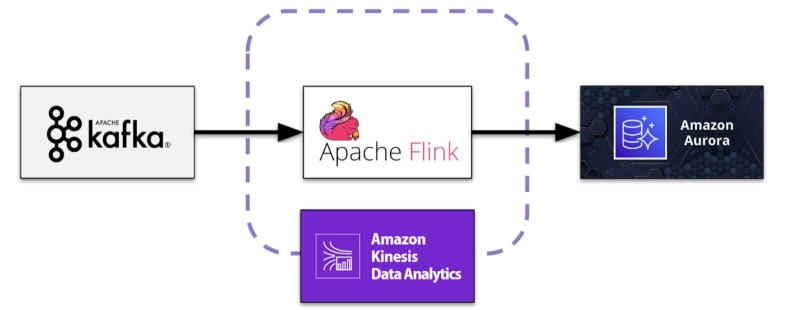
Capital One was originally using Spark for batch processing but they faced efficiency issues with increasing data volumes and a desire to improve their real-time capabilities. The team sought a scalable, low-maintenance solution, leading to AWS KDA and AWS Aurora’s adoption for real-time processing. They built a proof of concept to test the viability of Flink with KDA.
Flink was chosen for its real-time capabilities, efficient memory management, and SQL-based transformations. AWS KDA offered scalability, easy configuration, and seamless AWS integration. The team utilized PyFlink for development, despite the more mature Java/Scala APIs, focusing on consuming Kafka streams and outputting to an AWS Aurora database.
The project involved configuring Flink to work with KDA-supported versions, setting up data sources and sinks, and creating a custom User-Defined Function (UDF) to decode Kafka stream messages.
Despite facing challenges, like SSL certification handling in KDA and managing custom data types, the collaboration with AWS provided valuable workarounds and best practices.
This experience highlighted the benefits of using Flink and KDA for real-time data streaming applications, emphasizing the importance of real-time processing and the advantages of managed services for scalability and security management. Capital One’s journey illustrates Flink and KDA’s effectiveness in addressing real-time data processing needs in the financial industry.
Lyft – Spark vs. Flink
In 2022, Lyft’s already comprehensive machine learning (ML) platform, LyftLearn, encompassed model serving, training, CI/CD, feature serving, and monitoring. However, it had limited integration with real-time streaming data, particularly in the realms of training and complex monitoring. Despite this, there was a strong demand within Lyft for real-time ML capabilities, crucial for enhancing Lyft’s real-time marketplace with immediate data signals.
To bridge this gap, Lyft launched the “Real-time Machine Learning with Streaming” initiative, leveraging Apache Flink’s streaming capabilities to enable seamless integration of streaming data into LyftLearn. The goal was to empower Lyft’s ML developers to effortlessly incorporate real-time data into their models, thereby improving real-time inference and decision-making processes.
Lyft identified three essential capabilities for real-time ML applications to leverage streaming data: computing real-time features, real-time learning, and making event-driven decisions with streaming data. Apache Flink was central in facilitating these capabilities, especially in event-driven decisions, which found immediate applications across various teams within Lyft, including a project to revamp Lyft’s Traffic infrastructure using real-time data aggregation.
Uber Use Case
Uber relies heavily on both offline and online analytics for decision-making, with data volumes growing exponentially each year. To efficiently process this vast amount of data, Uber has predominantly used Apache Spark™, which powers numerous critical business functions like Uber rides, Uber Eats, autonomous vehicles, ETAs, and Maps. Spark’s extensive use at Uber is evident in its operation on over 10,000 nodes, consuming more than 95% of analytics cluster compute resources to process hundreds of petabytes of data daily.
Despite Spark’s advantages, Uber has encountered significant challenges, particularly with the Spark shuffle operation—a key process for data transfer between job stages, which traditionally occurs locally on each machine. To address the inefficiencies and reliability issues of local shuffling, Uber proposed a new Remote Shuffle Service (RSS), moving shuffle operations to remote machines. This transition aims to enhance computing efficiency, alleviate the dependency on persistent local disk storage, and facilitate a smoother transition to cloud environments while also supporting the colocation of Data Batch and microservices on the same machines.
Uber’s exploration of remote shuffle solutions involved several approaches, including different storage plugins and streaming writes; however, these significantly increased job latencies. The breakthrough came with the RSS, which adopted a reversed Map-Reduce paradigm, coordinating map tasks to write to specific RSS servers. This innovation led to performance on par with, or sometimes surpassing, local shuffles.
The Result
The RSS architecture consists of three main components: the Client, Server, and Service Registry. The RSS Client, integrated into Spark executors, communicates with RSS servers and the Service Registry to determine server availability and manage data transfers. The Service Registry tracks available RSS servers; meanwhile, the Shuffle Manager within the RSS Client selects RSS servers for data storage and retrieval. Each RSS Server efficiently handles data streams from multiple map tasks, directly writing them to local disk files.
Implementing RSS at Uber has significantly improved Spark operations’ reliability and scalability. It has reduced hardware wear and tear, decreased application failures, and increased the capacity to handle large-scale shuffles beyond the limitations of local disk storage. RSS’s deployment has transformed Uber’s Spark infrastructure, offering a scalable, reliable solution for one of the largest Spark workloads in the industry. Uber has also made RSS an open-source project, contributing to the broader Apache Spark and cloud computing communities.
Ecosystem and managed solutions
The ecosystems and communities surrounding Apache Spark and Apache Flink play pivotal roles in their adoption, development, and success in handling big data challenges. Both frameworks are supported by rich ecosystems comprising various integrations, tools, and platforms, complemented by active and vibrant communities.
Apache Spark Ecosystem
Databricks
Founded by the original creators of Apache Spark, Databricks offers a unified data analytics platform that provides a managed Spark environment, simplifying the process of working with Spark in the cloud. Databricks integrates closely with Spark to offer enhanced capabilities, such as optimized execution and streamlined workflows, making it easier for organizations to deploy Spark at scale.
Apache Spark community and support:
Spark boasts a large and active community, contributing to its rapid development and the continuous addition of new features and improvements. The community provides extensive documentation, forums, online courses, and meetups, facilitating learning and troubleshooting.
The availability of resources and skilled developers is relatively high for Spark due to its widespread adoption and the existence of comprehensive training materials and community support.
Apache Flink Ecosystem:
Similar to Spark, Flink integrates with a wide range of storage systems, messaging queues, and databases, enabling it to fit seamlessly into existing data infrastructure. Its ecosystem includes connectors for systems like Apache Kafka, Amazon Kinesis, Elasticsearch, and JDBC databases.
DeltaStream
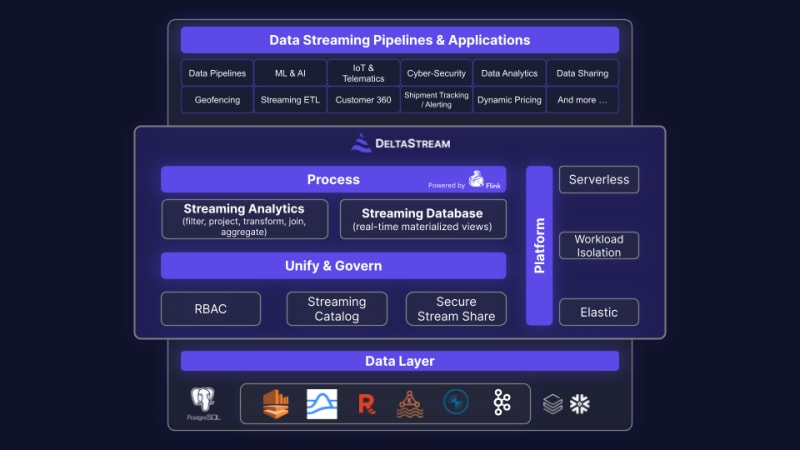
spark vs flink – delta stream diagram
Flink isn’t an easy solution to manage yourself, especially at scale. In turn, there are solutions like DeltaStream that aim to make it easier. DeltaStream allows you to connect to data sources like Kafka or Kinesis and create SQL-like transforms on top that then can be piped to another destination. Meanwhile, you may not even realize Flink is under the hood powering it.
Community and support:
Flink’s community, while smaller than Spark’s, is highly active and engaged, contributing to a steady stream of innovations and features. The community support includes detailed documentation, forums, and events like Flink Forward, bringing together the global Flink community.
While the pool of Flink experts might be smaller compared to Spark, the demand for Flink expertise is growing, and resources for learning and development are increasingly becoming available.
Both Apache Spark and Apache Flink are bolstered by their ecosystems and communities, driving their evolution and adoption. While Spark has a broader adoption and a more extensive community, Flink’s unique capabilities, especially in stream processing, have nurtured a dedicated and growing community. The choice between Spark and Flink often comes down to specific project requirements and the existing technology stack within an organization.
Apache Spark
Pros:
- Mature Ecosystem: Apache Spark has a mature and expansive ecosystem, including libraries for SQL, streaming, machine learning, and graph processing, making it a versatile choice for a wide range of applications.
- Ease of Use: With high-level APIs in Java, Scala, Python, and R, along with interactive shells, Spark is known for its ease of use, especially for batch processing.
- Large Community and Support: Spark has a vast community, meaning abundant resources, support, and a rich ecosystem of third-party tools and platforms.
Cons:
- Memory Management: Spark’s in-memory processing, while fast, can be expensive in terms of memory usage. It might also not be the most efficient for all workloads, especially those that cannot fit entirely into memory.
- Latency: For streaming applications, Spark’s micro-batch processing model can introduce higher latency compared to true streaming models, making it less ideal for real-time processing needs.
- Complexity in Tuning: Due to its extensive feature set and configuration options, Spark can be complex to tune and optimize for performance.
Apache Flink
Pros:
- True Streaming Model: Flink is designed with a true streaming model at its core, allowing for more efficient and lower-latency stream processing compared to micro-batch models.
- State Management and Checkpointing: Flink provides robust state management and exactly-once processing semantics out of the box, making it highly reliable for critical stream processing applications.
- Flexibility: Flink’s APIs provide excellent flexibility for building complex event-driven applications and are designed to handle both batch and stream processing effectively.
- Scalability: Flink is known for its ability to scale effectively, maintaining high performance and reliability as workloads grow.
Cons:
- Youth and Ecosystem: While rapidly growing, Flink’s ecosystem is not as mature as Spark’s, which might limit some functionality or integrations available out of the box.
- Learning Curve: Given its unique architecture and APIs, there might be a steeper learning curve for teams new to Flink, especially for those not familiar with stream-first processing models.
- Operational Complexity: Flink can be more complex to set up and manage, particularly in large-scale, mission-critical deployments, requiring more expertise to ensure high availability and fault tolerance.
Cost Of Compute Inside Of Your Data Warehouse
One of the recent points brought up is the cost of compute on cloud data platforms and warehouses. In turn, some data teams are looking to run transforms externally, often on solutions like Flink or a Spark cluster. Now there is always a cost for everything, but once a company gets large enough or, more importantly, their data gets large enough and their transforms get complex enough, this cost arbitrage can make a lot of sense!
Can help improve performance
Another reason we often find data teams moving their data transforms into their streaming layers is that it can be more performant. If you’re running a batch process, it’ll only process data every hour or every day, meaning the data will be delayed and could take minutes or hours to process because you’ve waited until you’ve got a large amount of data. In comparison, stream processing can manage some of the initial data processing live, thus ensuring the data is both live as well as easier to process.
Conclusion
Stream processing large data sets continues to be a necessity, especially for (but not limited to) companies such as Capital One and Lyft. It lets them process data for their machine-learning models and daily analytical needs. In turn, tools like Spark and Flink have been crucial in handling big data sets.
So if you were looking to understand the difference between Spark and Flink, hopefully, it’s now a little clearer.