PostgreSQL in a time of Kubernetes
Read about how we created a useful set of projects for operating PostgreSQL on Kubernetes.

Senior Platform Engineer
A lot of time has passed at Zalando since the first services were started backed by PostgreSQL 9.0-rc1. Despite the adoption of other technologies, PostgreSQL remains the preferred relational database for most engineers around. You can follow some of the developments around PostgreSQL on the blog and also on GitHub where we share most of our PostgreSQL-related tooling.
Let’s start with a quick look at PostgreSQL on AWS. When Zalando Tech began its transition to AWS, the STUPS landscape and tooling was created. For the ACID team (the database engineering team), the most relevant changes where that applications had to run in Docker and EC2 instances might be slightly less reliable than what we were used to.
At scale and in the cloud automation is key. The ACID team started the work on Patroni, today Zalando’s most popular open source GitHub project, to take care of PostgreSQL deployments and manage high availability, among other valuable features. The next step was Spilo, packaging Patroni and PostgreSQL into a single Docker image and providing guidance on how to deploy database clusters using AWS CloudFormation templates.
Today teams have the choice of deploying PostgreSQL either with AWS RDS or Spilo. We are convinced that Spilo is a more flexible solution, providing more control to teams, although often the one-click RDS service is more compelling. We feel that our own PostgreSQL solution gives us more control and more flexibility, but this is not always required.
However, automated our deployment became, we did not focus on the last step, which is automating the initial request for a cluster. Somewhere between the team wanting a PostgreSQL database and the database team creating it was still a ticketing system. This had to change. Initial work on a REST service to trigger Spilo deployments on plain AWS/EC2 was scrubbed in favor of a new solution using Kubernetes, believing that this the future platform to run on and benefiting from its feature set, which is a stable API and declarative deployment descriptions. Kubernetes today runs on various cloud providers, opening up for a bigger target audience and less lock in.
Current status
Let’s take a look at what we are currently developing and working on as open source products. First, we will briefly touch on the PostgreSQL operator and its tiny user interface and then look into the pg_view web version.
Kubernetes provides so-called third party objects, allowing us to store YAML documents within Kubernetes itself and act upon their changes. Using those third party objects to describe PostgreSQL clusters, we started working on the operator that picks up the YAML definitions and transforms them into Kubernetes resources needed to run and expose PostgreSQL clusters to our engineers. This concept will later allow us to easily configure and provision PostgreSQL into production environments with a common deployment pipeline that relies solely on the Kubernetes API, basically triggering PostgreSQL cluster setup from engineers committing to Git.
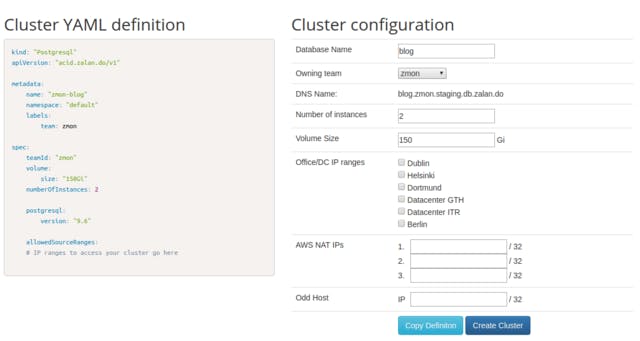
Writing a YAML is pretty easy, but somehow it turned out having a user interface to get a cluster even quicker was a good idea and less error prone. Thus, we wrote a very small RiotJS user interface for engineers to create PostgreSQL clusters and provide them with feedback on how far the cluster creation is progressing. As one basically only works against the nice Kubernetes API, this was not much work in the end.
The next thing we learned is that once you have a UI, engineers create clusters with incomplete or tiny misconfigurations - forcing us to quickly add the first possible features to change the cluster configuration and test the idea of the operator in production. Making the change means updating the third party object and letting the postgres-operator update the Kubernetes resources.
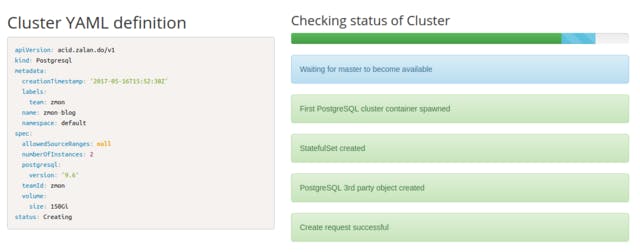
Thanks to the work done in Patroni, tackling deployment, configuration, failover and recovery from S3 for example, the deployment of a database is only a part of what users expect from PostgreSQL as a service. Maintenance and monitoring are equally essential and most likely to require more work and attention.
Monitoring
Earlier we released our console tool pg_view to monitor the PostgreSQL cluster in “real-time”; however, by its nature it required users to have SSH access into the machine, something no longer possible and not desired for every engineer. Discussing the options, not everyone was immediately on board with the idea to transfer this to a web based solution, but one of our engineers had already done the heavy lifting: a custom PostgreSQL extension was lingering around in his GitHub repos providing all the metric and query data via a single HTTP endpoint. We quickly implemented a tiny prototype UI showing the same data earlier visible on the terminal and, as we received good feedback on the idea, decided to stick with it.
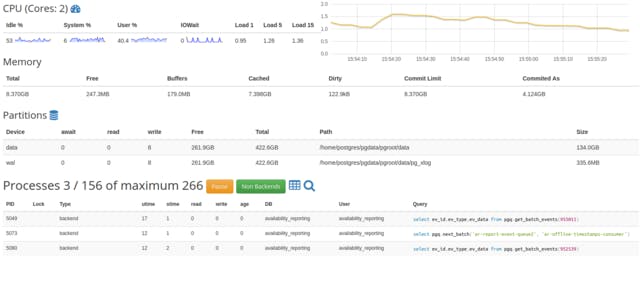
While this provided the critical insights into running queries and system metrics, we also reworked the ZMON-based coverage of our PostgreSQL clusters. ZMON checks track the basic metrics one expects from AWS instances/Kubernetes Pods: CPU and memory, along with storage metrics and monitoring for free disk space. Additionally, we also started to track PostgreSQL internal metrics from tables and indexes to give engineers a better impression on how tables and indexes were growing, as well as how and where sequential scan or index scan patterns changed over time.
What’s in it for you?
We have already open sourced the operator and are investing more time to improve its feature set as we speak. Shortly, we will also release the user interface for “creating” the third party resources to trigger PostgreSQL clusters. Our pg_view web version will also arrive soon.
From our point of view, the above creates a very useful set of projects around operating PostgreSQL on Kubernetes. Keep an eye out for new repositories in the Zalando Incubator, or contact me via Twitter at @JanMussler if you have further questions. Interested in joining us? We're hiring.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Software Engineer!


