Handling a Regional Outage: Comparing the Response From AWS, Azure and GCP
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover three out of seven topics from today’s subscriber-only issue Three Cloud Providers, Three Outages: Three Different Responses. To get full issues twice a week, subscribe here.
It’s rare that all three major cloud providers suffer regional outages, but that’s exactly what happened between April and July:
- 25 April 2023: GCP. A Google Cloud region (europe-west-9) went offline for about a day, and a zone was offline for two weeks (europe-west-9-a.) (incident details). We did a deepdive into this incident in What is going on at Google Cloud?
- 13 June 2023: AWS. The largest AWS region (us-east-1) degraded heavily for 3 hours, impacting 104 AWS services. A joke says that when us-east-1 sneezes the whole world feels it, and this was true: Fortnite matchmaking stopped working, McDonalds and Burger King food orders via apps couldn’t be made, and customers of services like Slack, Vercel, Zapier and many more all felt the impact. (incident details). We did a deepdive into this incident earlier in AWS’s us-east-1 outage.
- 5 July 2023: Azure. A region (West Europe) partially went down for about 8 hours due to a major storm in the Netherlands. Customers of Confluent, CloudAmp, and several other vendors running services out of this region suffered disruption. (incident details). We touched on this outage in The Scoop #55: how can a storm damage fiber cables?
A regional outage is rare for any cloud provider because regions are built to be resilient. The fact each major cloud provider suffered one allows us to compare their responses, and take some learnings about best practices. We’ll also learn how this article contributed to AWS publishing its first public postmortem in two years!
Today, we cover:
- 1. Communicating during the incident
- 2. Preliminary incident details
- 3. Incident postmortem and retrospective
- 3.1 Azure’s standout postmortem and retrospective
- 3.2 Google Cloud’s detailed incident review
- 3.3 Silence of AWS (until this article was about to publish)
1. Communicating during the incident
How did the cloud providers communicate during the incidents? A summary:

Google Cloud is the only cloud provider that preserved the incident communication log on the incident page, so we can see which updates occurred and when. I like that every status update followed this template:
“Summary: {short summary}
Description: {more details, based on what is known}
{When the next update can be expected}
Diagnosis: {summary if this is known}
Workaround: {possible workaround for customers}”
The incident at Google Cloud was a particularly nasty one; flames spread through a data center hosting the europe-west-9-a zone, and also some clusters from the europe-west-9-c zone. The incident caused the entire europe-west-9 region to be inaccessible for around 14 hours. There was little to tell customers beyond that they needed to fail over to other regions. Google Cloud posted regular updates sharing what they could, such as this, four hours into the incident:
“Summary: We are investigating an issue affecting multiple Cloud services in the europe-west9-a zone
Description: Water intrusion in europe-west9-a led to an emergency shutdown of some hardware in that zone. There is no current ETA for recovery of operations in europe-west9-a, but it is expected to be an extended outage. Customers are advised to fail over to other zones if they are impacted.
We will provide an update by Wednesday, 2023-04-26 00:30 US/Pacific with current details.
We apologize to all who are affected by the disruption.
Diagnosis: Customers may be unable to access Cloud resources in europe-west9-a
Workaround: Customers can fail over to other zones.”
After the first few hours, updates became pretty much copy-paste and uninformative. However, GCP kept providing them, and was clear about when the next update was due.
While I appreciate continuous updates, these were unnecessarily verbose and robotic in tone; as if someone was resending the same template every 30 minutes. It was also hard to tell when an update contained new information. Despite that, it’s better to send updates and make them visible after an incident, than to not send them, or remove them post-incident.
AWS did the best job of sharing concise, clear and frequent-enough updates among all the cloud providers. Here are the updates from the first hour of the incident:
“[5 June 2023] 12:08 PM PDT We are investigating increased error rates and latencies in the US-EAST-1 Region.
12:19 PM PDT AWS Lambda function invocation is experiencing elevated error rates. We are working to identify the root cause of this issue.
12:26 PM PDT We have identified the root cause of the elevated errors invoking AWS Lambda functions, and are actively working to resolve this issue.
12:36 PM PDT We are continuing to experience increased error rates and latencies for multiple AWS Services in the US-EAST-1 Region. We have identified the root cause as an issue with AWS Lambda, and are actively working toward resolution. For customers attempting to access the AWS Management Console, we recommend using a region-specific endpoint (such as: https://us-west-2.console.aws.amazon.com). We are actively working on full mitigation and will continue to provide regular updates.
1:14 PM PDT We are continuing to work to resolve the error rates invoking Lambda functions. We're also observing elevated errors obtaining temporary credentials from the AWS Security Token Service, and are working in parallel to resolve these errors.
1:38 PM PDT We are beginning to see an improvement in the Lambda function error rates. We are continuing to work towards full recovery.”
Ninety minutes into the incident, an update provided a summary of progress:
“1:48 PM PDT Beginning at 11:49 AM PDT, customers began experiencing errors and latencies with multiple AWS services in the US-EAST-1 Region. Our engineering teams were immediately engaged and began investigating. We quickly narrowed down the root cause to be an issue with a subsystem responsible for capacity management for AWS Lambda, which caused errors directly for customers (including through API Gateway) and indirectly through the use by other AWS services. We have associated other services that are impacted by this issue to this post on the Health Dashboard.
Additionally, customers may experience authentication or sign-in errors when using the AWS Management Console, or authenticating through Cognito or IAM STS. Customers may also experience intermittent issues when attempting to call or initiate a chat to AWS Support.
We are now observing sustained recovery of the Lambda invoke error rates, and recovery of other affected AWS services. We are continuing to monitor closely as we work towards full recovery across all services.”
And an update inside the final hour and a half of the outage:
“2:00 PM PDT Many AWS services are now fully recovered and marked Resolved on this event. We are continuing to work to fully recover all services.
2:29 PM PDT Lambda synchronous invocation APIs have recovered. We are still working on processing the backlog of asynchronous Lambda invocations that accumulated during the event, including invocations from other AWS services (such as SQS and EventBridge). Lambda is working to process these messages during the next few hours and during this time, we expect to see continued delays in the execution of asynchronous invocations.
2:49 PM PDT We are working to accelerate the rate at which Lambda asynchronous invocations are processed, and now estimate that the queue will be fully processed over the next hour. We expect that all queued invocations will be executed.”
Azure is the only cloud provider whose updates from during the incident cannot be viewed after it was resolved. I tracked this incident at the time and there were regular updates. However, today there is no paper trail to see their contents.
There is plenty to like about how Azure handles public communications, but it is the only major cloud provider that makes incident notes inaccessible to public view after an outage is resolved.
2. Preliminary incident details
With any incident, mitigation comes first. An investigation starts after everything is back to normal and customers can use a service as normal. This investigation can be time consuming, so it’s hard to tell customers exactly when to expect more details. However, in these cases we aren’t talking about a small engineering team with a few users; but the largest cloud providers in the world upon whom tens of thousands of businesses rely. And these businesses expect some full details when a full investigation is complete. Here’s how the providers compared:

AWS was extremely fast in providing a summary of the incident, and did so in just 5 minutes (!!) after the incident was mitigated. Below is the update added to the status page:
3:42 PM PDT Between 11:49 AM PDT and 3:37 PM PDT, we experienced increased error rates and latencies for multiple AWS Services in the US-EAST-1 Region. Our engineering teams were immediately engaged and began investigating. We quickly narrowed down the root cause to be an issue with a subsystem responsible for capacity management for AWS Lambda, which caused errors directly for customers (including through API Gateway) and indirectly through the use of other AWS services. Additionally, customers may have experienced authentication or sign-in errors when using the AWS Management Console, or authenticating through Cognito or IAM STS.
Customers may also have experienced issues when attempting to initiate a Call or Chat to AWS Support. As of 2:47 PM PDT, the issue initiating calls and chats to AWS Support was resolved.
By 1:41 PM PDT, the underlying issue with the subsystem responsible for AWS Lambda was resolved. At that time, we began processing the backlog of asynchronous Lambda invocations that accumulated during the event, including invocations from other AWS services. As of 3:37 PM PDT, the backlog was fully processed. The issue has been resolved and all AWS Services are operating normally.”
Call me amazed. Credit where it is due, this communication was fast and on point. Unfortunately, it was also almost the last time AWS communicated anything publicly about this outage.
Google Cloud posted a preliminary incident review 14 days after the regional outage was resolved, at the time when the europe-west-9-a zone was still down. The fact that the zonal outage lasted 14 days makes it a little tricky to judge whether Google Cloud posted the preliminary report one day after the full outage was resolved, or 14 days after the regional outage was mitigated.
I am leaving the 14 days here, because a regional outage is far wider-reaching than a zonal outage, and Google did leave customers who were dependent on the europe-west-9 region – but not the europe-west-9-a zone – waiting two weeks for preliminary details.
Azure is the only cloud provider that publishes timelines on preliminary PIRs (production incident reviews) – and for full incident reviews:
“We endeavor to publish a ‘Preliminary’ PIR within 3 days of incident mitigation, to share what we know so far. After our internal retrospective is completed (generally within 14 days) we will publish a ‘Final’ PIR with additional details/learnings.”
In this case, I remember Azure did publish such a review, and it was within the 3-day timeframe. However, after the final review was published the preliminary review was no longer publicly available.
3. Incident postmortem and retrospective
Until this post, the 3 cloud providers did comparably well at handling their incidents. Post-incident is where things diverged significantly:

3.1 Azure’s standout postmortem and retrospective
On 5 July 2023, one of the worst storms to ever hit the Netherlands struck, which I can attest to, first-hand. In The Scoop #55 I shared a photo of a tree uprooted and felled by the storm winds, just a few blocks from my house. I wrote that such an event could tear cables. Well, it turns out this is exactly what happened in Azure’s case; the storm uprooted a tree which yanked a data center fiber path out from under the ground:

The full production incident review was published within two weeks of mitigation, and contained these sections:
- “What happened?”
- “What went wrong and why?“
- “How did we respond?”
- “How are we making incidents like this less likely or less impactful?“
- “How can customers make incidents like this less impactful?”
The storm severed a cable which caused 25% of network links between two West Europe data centers to become unavailable. The problem was that network capacity was already above target utilization – and packets started to drop as a result of the capacity loss. Azure responded by starting to rebalance traffic in its network, and sent technicians to repair the cable. Cable restoration took longer thanks to the extreme weather, and functionality was restored thanks to rebalancing the network.
Azure was the only provider to share dates alongside not-yet-completed action items. Not only was Azure the fastest of all providers to publish their final postmortem: but it is the only cloud provider to do this with dates as ETAs:
“How are we making incidents like this less likely or less impactful?
- We have repaired the impacted networking links, in partnership with our dark fiber provider in the Netherlands. (Completed)
- Within 24 hours of the incident being mitigated we brought additional capacity online, on the impacted network path. (Completed)
- Within a week of the incident, we are 90% complete with our capacity augments that will double capacity in our West Europe region to bring utilization within our design targets. (Estimated completion: July 2023)
- As committed in a previous Post Incident Review (PIR), we are working towards auto-declaring regional incidents to ensure customers get notified more quickly (Estimated completion: August 2023).”
Now this is what I call self-imposed accountability!
Azure took the incident review further than other cloud providers, by holding a post-incident video discussion. This discussion is like a video retrospective, and Azure describes it like this:
“In addition to providing a written post-incident review after major outages, we also now host these retrospective conversations. You’re about to watch a recording of a livestream, where we invited impacted customers through Azure Service Health to join our panel of experts in a live Q&A.”
The video discussion is 23 minutes long, and well worth a watch for anyone interested in reliability or networking:
This video retrospective featured several people:
- The hosts: David Steele (Senior Program Manager on the Post-Incident Transparency team) and Sami Kubba (Principal PM Manager and Communications Team Lead)
- Dave Moltz: Head of the Networking team
- Jitendra Padhye: Partner Software Engineering Manager
- Frank Rey: Partner Technical Program Manager
The video retrospective was surprisingly useful, with a lot of information the PIR did not contain. For example:
- Azure sees about 40 fiber cut issues per day(!), meaning a fiber cut is “business as usual.” During the recording, a fiber cut was being handled in the UK which was invisible to customers.
- The Western Europe region was “running hot” compared to other regions, in not having as much networking redundancy as Azure prefers. The team ended up adding enough capacity to create more resilience.
My impression of Azure from a reliability perspective has greatly improved after watching this incident review. It feels like the Azure team took the incident seriously, were transparent about what happened, and were very clear about what improvements they were making to avoid similar outages. The review also helped reveal the scale at which Azure operates, with more than three dozen fiber cuts occurring every day, globally!
The review closed with these words:
“At the scale at which our [Azure’s] Cloud operates, incidents are inevitable. Just as Microsoft is always learning and improving, we hope our customers and partners can learn from these two, and provide a lot of reliability guidance through the Azure Well-Architected Framework. (...)
We’re really focused on being as transparent as possible and showing up as being accountable after these major incidents.”
Azure not only talks the talk; it walks the walk. Outstanding incident transparency is a blueprint any vendor can follow – if you want to go above and beyond on transparency and accountability, that is.
3.2 Google Cloud’s detailed incident review
The good thing about Google Cloud is that it published a preliminary incident review, and followed up with a postmortem two months after the incident on 23 June, after the region went offline on 25 April. The bad thing is that these two reviews contradict one another: the preliminary postmortem makes clear that two zones operated out of one data center (!), but the final review omitted this rather significant detail. Even worse, Google Cloud did not address this contradiction, despite me asking them about it for about a month. In September, I covered the outage in depth in The Pulse #61: What is Going on at Google Cloud?, writing:
“In Paris, Google Cloud seems to have partially operated two zones from the same data center. The fire that took the “europe-west9” region offline was caused by a water leak in the battery room at a Globalswitch data center, which is where one of Google Cloud's zones operates.
Google published a preliminary incident report two weeks after the incident, on 10 May. In this report they wrote:
- A water leak caused a fire in a Paris data center, in the battery room.
- The water leak initially impacted a portion of europe-west9-a; however, the subsequent fire required all of europe-west9-a and a portion of europe-west9-c to be temporarily powered down (...) Many regional services were affected while europe-west9-c was partially unavailable.
It’s clear the fire was in the data center where the europe-west9-a zone was based. But why would a fire in europe-west9-a require the powering down of a portion of an independent data center? The obvious explanation is that some instances of europe-west9-c were operated in the same data center location as europe-west9-a operates from!
I asked Google if europe-west9-a and europe-west9-c are in the same building, at least partially. The company responded, but failed to answer the question.”
Ultimately, Google Cloud went through the process of providing status updates, then providing a preliminary postmortem, and then closing with a final incident review. However, in comparison with the other cloud providers:
- AWS did a better job with concise and informative status updates.
- Both Azure and AWS provided a preliminary incident report much faster than Google Cloud did. Azure had its final incident report ready in the 14 days Google took to publish a preliminary report.
- Azure was more up front in sharing the root cause of the outage, and changes they made for greater resilience. Google did a decent job with the root cause though.
Google Cloud did provide the most detailed written post-incident analysis of all three providers. It also addressed how one building could bring down a whole region, and what they were doing about it, writing:
“Google uses an internal version of regional Spanner as a back-end database to several Google Cloud services such as IAM and various control planes that manage our infrastructure and services for a region. The outage had a regional impact as this regional Spanner was not configured correctly across the three buildings in the region for it to maintain its quorum. Regional Spanner should have had one replica in each of the three buildings in the region. Instead, it had two of its three replicas in two different clusters in the building that was powered down. (...)
We are currently conducting a detailed per-region audit (and conducting any required remediation if needed) of our internal regional Spanner allocations to confirm all regions fully meet Google Cloud expectations for fault isolation to prevent this issue in the future.”
This incident is hard to separate from what looks like a deliberate design choice by Google to partially operate two zones out of one data center. This is the type of approach that would be impossible to fathom AWS doing because the company is clear that “two zones” always means two separate locations, far enough away from each other. So even if a data center goes up in flames – as happened to Google – the region is still operational.
3.3 Silence of AWS (until this article was about to publish)
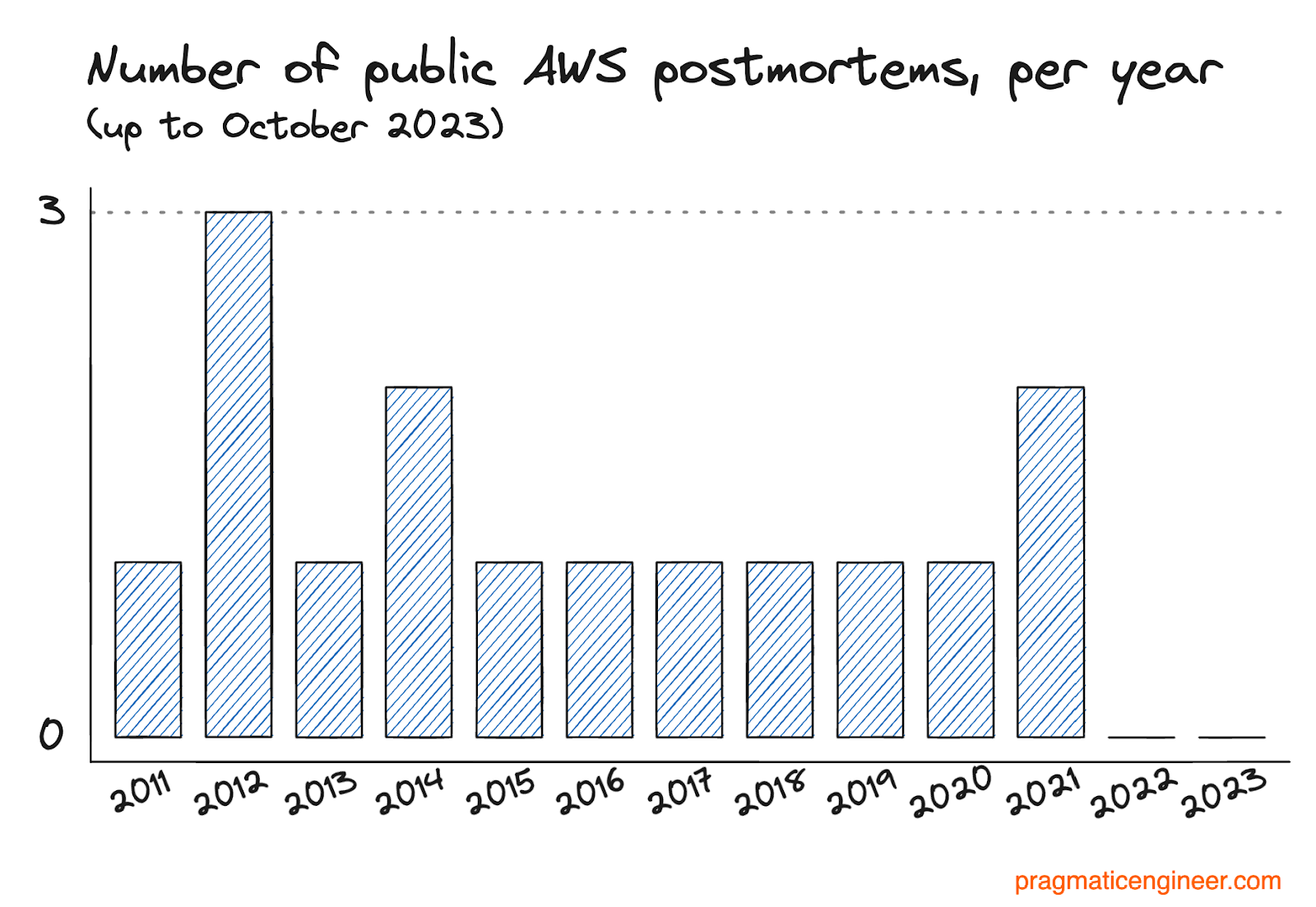
AWS did not follow up with any form of postmortem for more than four months after the incident. The company maintains a page with postmortems, stating that the page contains incidents deemed significant. On average, there has been once postmortem published per year, and none since December 2021:
We can easily compare this publishing cadence with other providers:
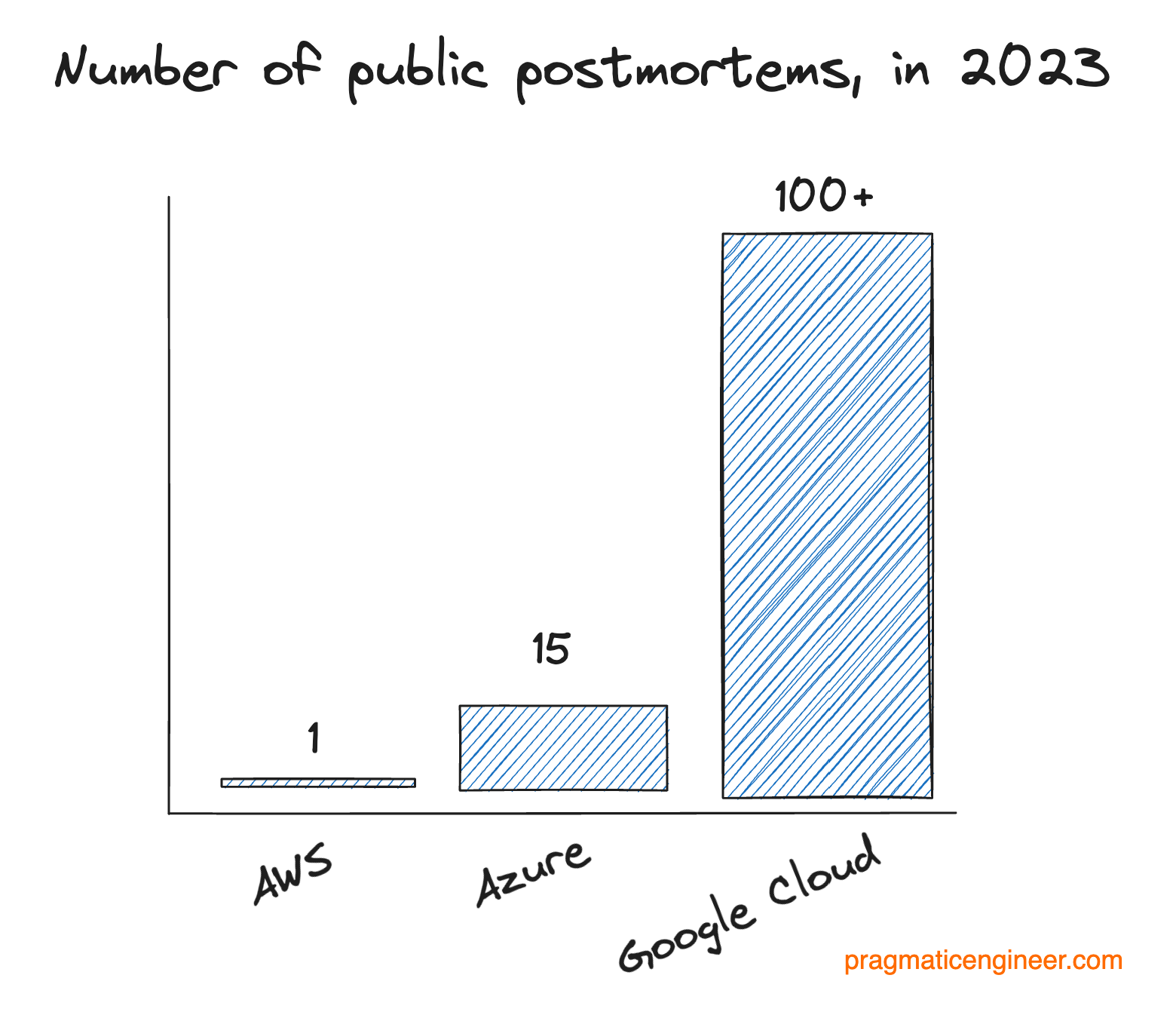
Looking at 2023 incidents for 2023:
- Google Cloud published more than 100 production incident reviews, and is the most granular of all providers in reporting incidents
- Azure published 15 production incident reviews
- AWS published zero… until 20 October
As I was writing this article, it struck me as very odd that despite AWS’s outage having the largest customer impact and being felt across the globe, AWS was the only provider not publishing any form of postmortem. So I reached out to the company on 15 October – more than 4 months after the outage of 4 June – and asked if it would publish a postmortem.
I said I was writing this article which compares how cloud providers respond to regional outages, and also that out of GCP, Azure, and AWS, only they (AWS) had failed to publish a postmortem for a major outage. I also asked for a definition of what “broad and significant customer impact” means: as this is the definition AWS uses in deciding when to publish a public postmortem.
On 19 October, a spokesperson from AWS responded, and asked for a bit more time. On 20 October, this person responded by linking to a new postmortem. This was the first public postmortem from AWS in two years!
It is pretty clear AWS published this postmortem because of the press inquiry. While I’m glad about this, it makes me wonder: why does it take someone writing an article about how AWS avoids publishing postmortems after major incidents, for AWS to finally publish a postmortem?
AWS’s public postmortem lacks some key details about what happened. In the face of AWS’s absence of public communication on the outage at the time, I did some digging to find out what caused such a large region to go down. From June’s The Scoop #52: AWS’s us-east-outage:
“While no postmortem yet published, I talked with current Amazon engineers who said it was a load test for AWS Lambda which caused the incident:
- The load test seems to have overloaded AWS Lambda. Many services depend on Lambda and started to degrade
- When the engineering team figured out the likely cause, they killed the load test and added more capacity to Lambda. The test was killed about an hour into the outage
- The next 2-3 hours of the outage were spent recovering degraded services. Some needed to be restarted, and the recovery of others was slower than expected”
The postmortem AWS shared gives more details on how Lambda works, and why it couldn’t handle more capacity. However, the postmortem omits mentioning the increase in load was due to a load test, and that mitigation involved stopping the load test.
It’s actually a great sign that AWS regularly does load testing; but within AWS there were plenty of questions about why it took so long to notice that capacity was pushed overboard by the test, and why it took so long to stop the test. The public postmortem reads as abstract, and I don’t get the feeling that transparency was a goal of this document.
These were three out of the seven topics covered in the subscriber-only article Three Cloud Providers, Three Outages: Three Different Responses. The full edition additionally covers:
- What is a cloud region and how does it differ between cloud providers? A recap.
- Why is AWS so opaque to the public?
- Why is Azure stepping up in transparency and accountability?
- Lessons for engineering teams from the three cloud providers
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 tech newsletter on Substack.