Polars vs Pandas. Inside an AWS Lambda.

Nothing gives me greater joy than rocking the boat. I take pleasure in finding what people love most in tech and trying to poke holes in it. Everything is sacred. Nothing is sacred. I also enjoy doing simple things, things that have a “real-life” feel to them. I suppose I could be like the others and simply write boring tutorials on how to do the same old thing for the millionth time.
Ugh. No thanks.
Today I want to do something spectacularly normal. Something Data Engineers do. I’m simply going to write an AWS Lambda to process some data, one with Polars, and one with Pandas. What do I hope to accomplish?
Well, I can usually make a few people mad. AWS Architectures and fan clubs, Polars people, Pandas people, and the general public at large. Bring it.
Does it matter?
Does it matter if you write an AWS Lambda in Polars vs Pandas? I don’t know. I mean you pay for the amount of memory, or size/footprint of your Lambda. Of course, you also pay for the entire runtime as well.
- memory matters
- runtime matters
The reality is if you are not paying much in AWS Lambda costs, then you probably don’t have anything to worry about. I suppose if you running Lambdas at scale, well then, you would think Polars could help you out. Why?
- Lazy execution for lower memory footprint.
- Fast means you pay for less runtime.
I suppose as a sidenote, we can also use SQL Context in Polars to make our code a little more readable since apparently people just can’t stop using SQL for everything. Then there is the technical debt argument. Sure, you can use what is considered “old” and “tried-and-true” technologies. But, what fun is that?
I’ve seen Pandas used a lot in different data pipelines over the years. The reality? It’s typically ugly code. Old code. Certain features become obsolete or depreciated, versions change, you have to change the code, pip sucks, and the story goes on. Besides … the syntax if for the birds.
What next?
Well, I want to be fair, even though people will accuse me of being not that, and send me angry emails. I will do with them what I do with the rest. Delete.
My plan is to find a fairly large dataset, but not that large. Maybe we can find like 5 GB of data to somehow crunch inside a Lambda. This seems probably normal for what a lot of people might find themselves doing. I also just want to see how the code feels, and then of course we can inspect memory usage and runtime. Then you can make your own decisions, stay stuck in the past, or move to the future.
Get some data.
Let’s get some data to work with. Let’s use the BackBlaze hard drive dataset, it appears one-quarter of data from 2022 is a little of 6 GBs. Perfect for us.

Here is all the data sitting in my s3 bucket.
So, now we can actually do something. Ok, we are also going to use Docker to build our AWS Lambda images, storing them in an ECR repository.
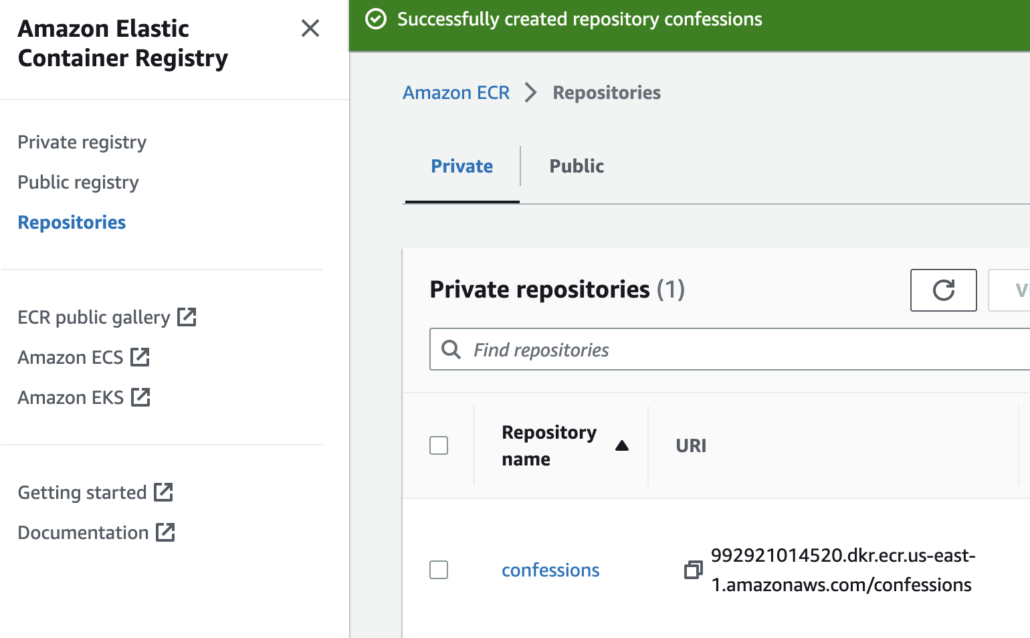
Here is a little short guide on how I go about building my Docker image and storing it in AWS ECR so it’s available for use with an AWS lambda.
buildimagetagimage- ECR
login pushimage
The actual commands in my case are (of course run from the correct directory) …
docker build -t confessions .aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin 992921014520.dkr.ecr.us-east-1.amazonaws.com/confessionsdocker tag confessions:latest 992921014520.dkr.ecr.us-east-1.amazonaws.com/confessions:latestdocker push 992921014520.dkr.ecr.us-east-1.amazonaws.com/confessions:latest
And done.
Shall we have a look at my Python code for the pandas lambda?
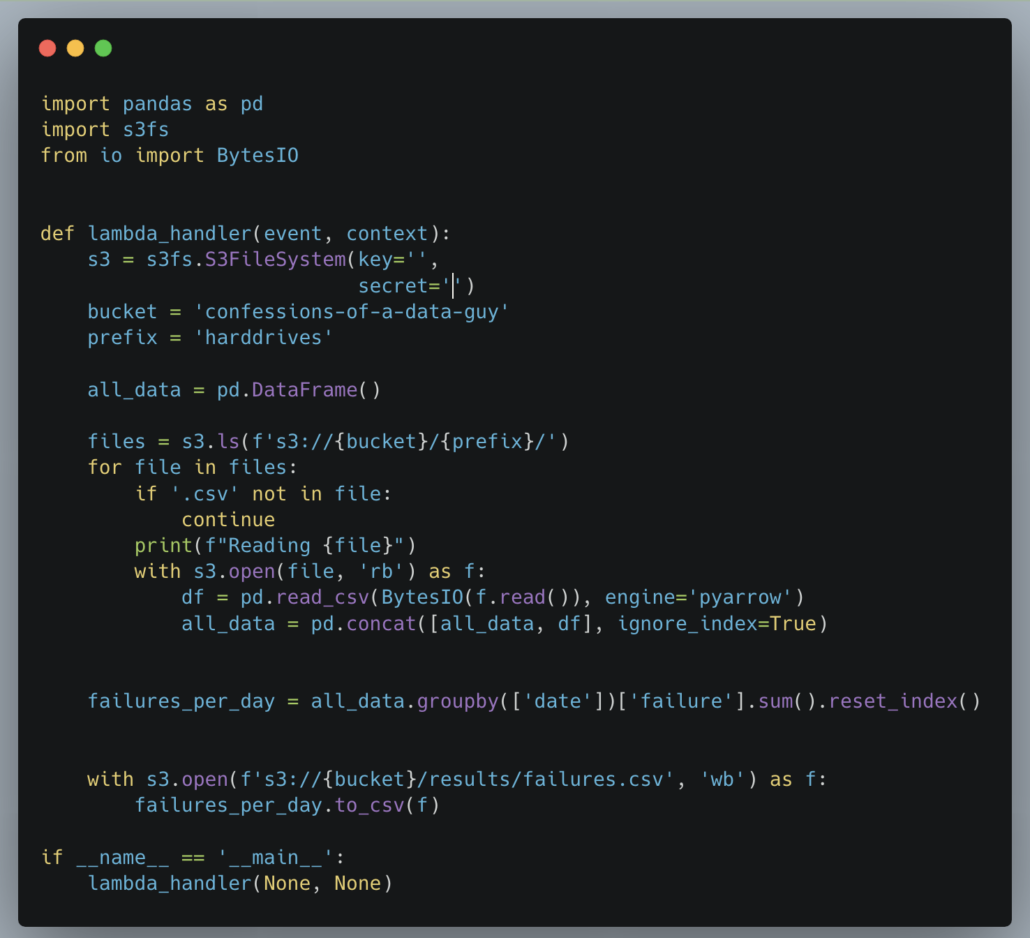
There is nothing special about my Python. It’s a bit of a contrived example, but you get the point. List the files in the s3 bucket, read them into dataframe(s), and do the analytics. There are about 90 files that will have to be read … have fun with that Pandas.
I’m sure some astute Pythonista will give me the old “one-two” for doing it wrong. I will file it with the rest of the complaints.
Below is my AWS lambda all ready to rip.
And this to invoke it.
aws lambda invoke --function-name arn:aws:lambda:us-east-1:992921014520:function:pandasLambda --region us-east-1 --profile confessions output.json
Well, should have seen this coming … between the AWS Lambda and Pandas. Memory Error.
`[ERROR] MemoryError: Unable to allocate 711. MiB for an array with shape (90, 1034753) and data type float64`
More poor little personal AWS account has a 3GB max on Lambda memory, not the official 10GB you can get if you really want. I think I shall just hack down the data I’m working on so it’s maybe 2GBs worth of files, see what happens.
Deleted, a bunch of files. Now what we got?
aws s3 ls --profile confessions --summarize --human-readable --recursive s3://confessions-of-a-data-guy/
Total Objects: 38
Total Size: 2.6 GiB
Ok, let’s give ‘er the old Pandas try again.
Welp, here we go again.
`[ERROR] MemoryError: Unable to allocate 727. MiB for an array with shape (90, 1058502) and data type float64`
Good ole’ Pandas. Can’t handle 2.6GB of data on a 3GB Lambda. I’m sure all the Pandas fans will roast me about what I could do. Well, that is sort of the point. I want to show what an Average Engineer is going to go through when trying to write some “simple” code to do a “simple” thing.
Ok, let’s delete some more files. What’s it going to take to get Pandas to run? After some more deletes, here is what the bucket shows.
Total Objects: 31
Total Size: 2.1 GiB
Anddddddd … you guessed it. Memory Errors. And people wonder why half of us hate Pandas. Ok, I guess we delete some more data.
Down to …
Total Objects: 24
Total Size: 1.6 GiB
Maybe? Maybe? (I know we could program around this, but the fact that you would have to…)
Nope. Memory Error.
Dang. Welp, let’s keep hacking away at the files.
Total Objects: 17
Total Size: 1.1 GiB
I mean, can we not work on 1.1GBs of data on a 3GB Lambda with Pandas??
Nope. Memory Error. Maybe you’re going to yell at me to use Pandas append and not concat, well I’m using the latest version of Pandas to take advantage of the PyArrow backend, and append was dropped. So.
Delete more data? LoL! Welp, here we are, down from 90 files to 10.
Total Objects: 10
Total Size: 639.1 MiB
Lest you think I lie, here are the lambda logs, it dies on the 5th file.
| Reading confessions-of-a-data-guy/harddrives/2022-03-23.csv | ||
| Reading confessions-of-a-data-guy/harddrives/2022-03-24.csv | ||
| Reading confessions-of-a-data-guy/harddrives/2022-03-25.csv | ||
| Reading confessions-of-a-data-guy/harddrives/2022-03-26.csv | ||
| Reading confessions-of-a-data-guy/harddrives/2022-03-27.csv | ||
| [ERROR] MemoryError: Unable to allocate 727. MiB for an array with shape (90, 1058557) and |
Again, I know we could program around this specific problem, maybe just work on one file at a time, do the math, accumulate and stash, do the next, etc. But, I’m trying to make a point, at some point, you have to ask yourself, “If I have to program around these problems, should I be using a different tool?”
Ok. A measly 213MB on a 3GB Lambda. Sheesh Pandas.
Total Objects: 4
Total Size: 213.1 MiB
And finally, done.
,date,failure
0,2022-03-23,10
1,2022-03-24,12
2,2022-03-29,4
It’s pretty amazing, isn’t it?
It’s almost impossible to compare these two tools, Pandas and Polars isn’t it?
Polars Suprise.
So, now it is time to turn our weary eyes towards the ever-lauded Polars. First, it is plainly and quite obviously a better tool than Pandas. But, there is always a but. It does take time to work the kinks out of new tools always, no matter how nice you think they are. Remember, I just want to read a bucket of s3 files as easily as possible and do some simple work on a Lambda … I want it to be as easy as it would be with Spark!
Firstly, because of the file-by-file iteration we had to do in Pandas, I has my hopes extremely hight that Polars in conjunction with pyarrow might be able to simply read a folder. But alas, that was not to be. Buggy.

It simply would not do it.
[ERROR] ArrowInvalid: GetFileInfo() yielded path ‘confessions-of-a-data-guy/harddrives/2022-03-31.csv’, which is outside base dir ‘s3://confessions-of-a-data-guy/harddrives/’
Traceback (most recent call last):
It’s like it was trying to scan the directory, and sort of working, but puking about a file inside the directory. So disappointing. If I’m going to be hard on Pandas, I must throw some stones at Polars and Pyarrow.
But, never fear, just a little Googling figured it out. Seems if I mess with a few things, and be specific about what files I want, we can get it to work. Although, I am curious about the memory portion of how Polars will deal with this 90 file and 60 GBs of data.
Do you think Polars will end up like Pandas, choking out the box or not?
I’m going to use both PyArrow and Polars together, so I’m not sure this is all that fair to Pandas, but it makes sense in my head.
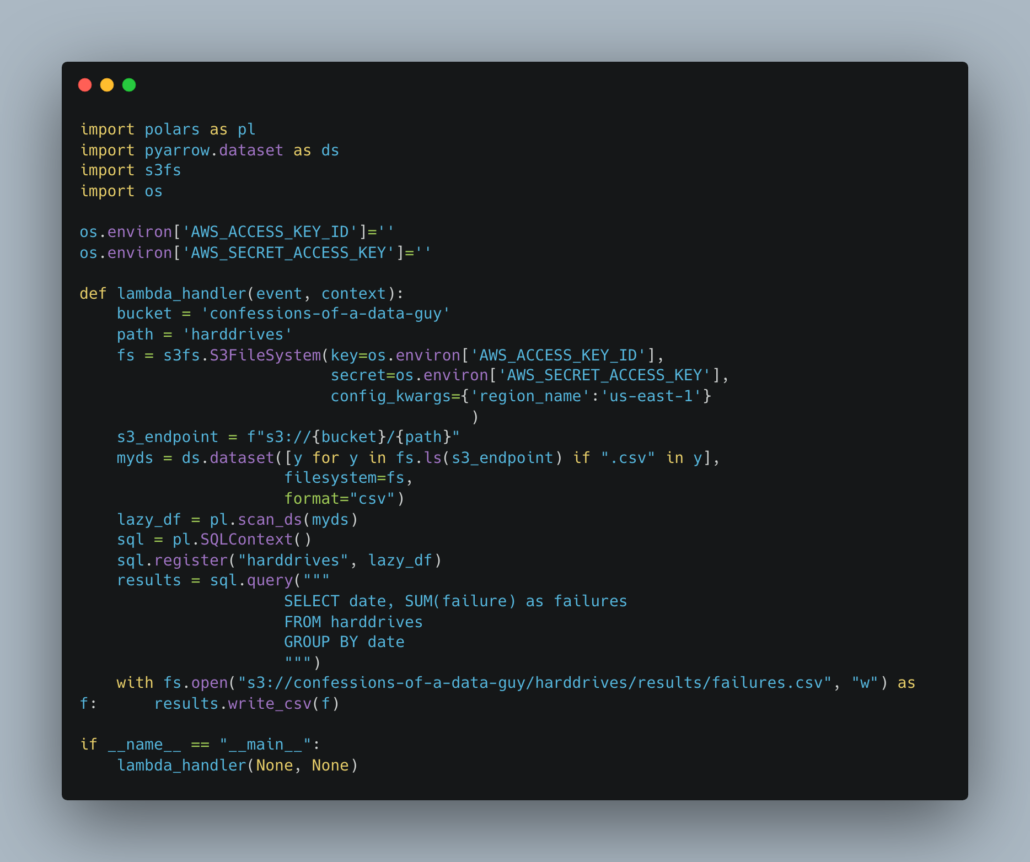
What’s interesting about this Polars code compared to the Pandas code? Well, much like the Pandas code it’s very simple, and the biggest difference is that I don’t have to do any file iteration myself (other than passing a list of the s3 files to a dataset), along with any sort of union or concat of DataFrames to be able to work on the dataset as a whole!
It also makes use of the lazy abilities of Polars, so as to reduce memory usage and allow Polars query optimizations to happen.
As well, I get to use SQL to write my aggregation, which no Data Engineer can complain about.
The real question is, can Polars process 6GB of data on the 3GB Lambda within 15 minutes timeout limit????
It’s almost too much to bear. If it can, I say, we must all bow before Polars as our supreme leader and benefactor (besides Spark that is.)
Well, I can’t believe it. Success!
And the results.csv even looks valid!!
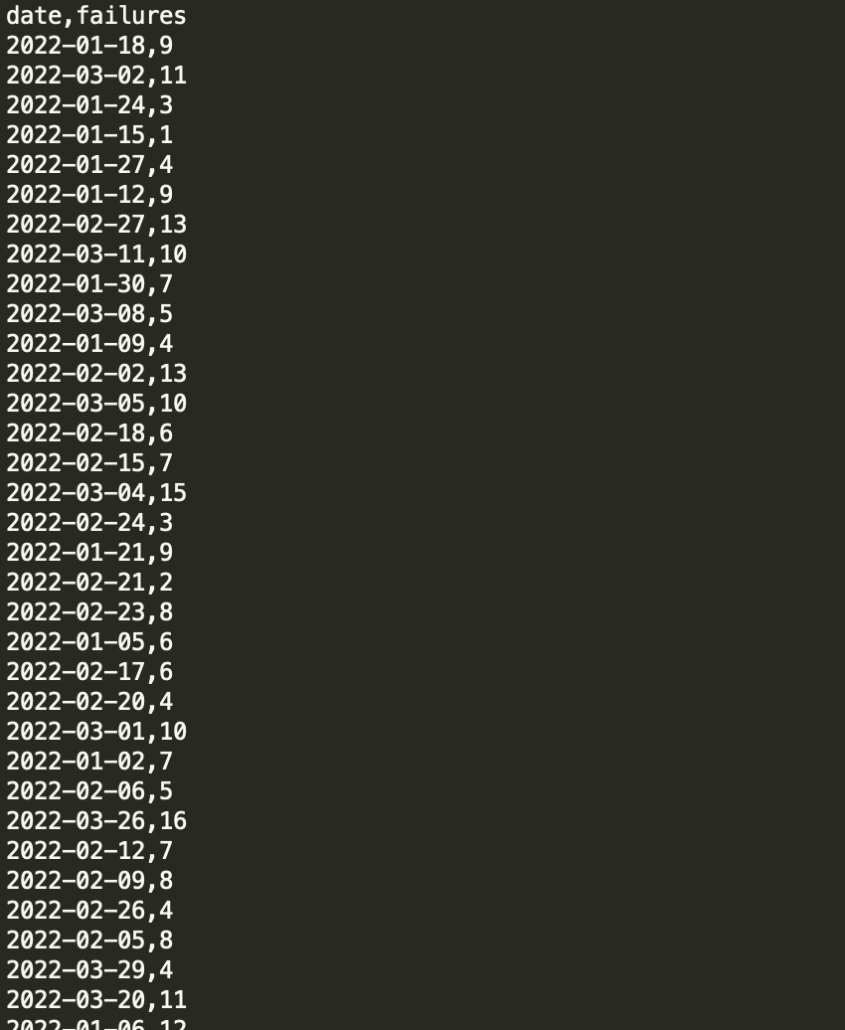
What a wonderful tool Polars is. I’m honestly surprised it could do all this with little to no effort.
What about runtime and memory usage on Lambda? 91015.92ms which is about 1.5 minutes. And it maxed out at less than 1GB of memory used, Max Memory Used: 882 MB.
That’s what I’m talking about, what a great tool! Long live Rust.
Hi there,
And what about using the arrow backend available from Pandas 2.x instead of default numpy backend ?
Another interesting benchmarks could be DuckDB+Pandas or even DuckDB+Polars
Fantastic article
Minor point: your pandas code would’ve been more efficient if you’d appended all the dataframes to a list and then called `concat` once at the end, rather than repeatedly calling `concat` each time
Not that it would make much difference for the comparison, just leaving this here as an “FYI in case you can’t use polars for whatever reason”
Thanks for the informative article. I was looking for such benchmark for a very long time.
(But if “I just want to read a bucket of s3 files as easily as possible and do some simple work”, then I will use Athena!)
You should get the `failure` per file, not just concat all dataframes. The memory problem should NOT happened, since single file is just about 50MB.