Boosting Machine Learning Algorithms: An Overview
The combination of several machine learning algorithms is referred to as ensemble learning. There are several ensemble learning techniques. In this article, we will focus on boosting.

Combing various machine learning algorithms while solving a problem usually results in better results. The individual algorithms are referred to as weak learners. Their combination results in a strong learner. A weak learner is a model that gives better results than a random prediction in a classification problem or the mean in a regression problem.
The final result from these algorithms is obtained by fitting them on the training data and combining their predictions. In classification, the combination is done by voting, while in regression, it’s done via averaging.
The combination of several machine learning algorithms is referred to as ensemble learning. There are several ensemble learning techniques. In this article, we will focus on boosting.
Let’s start learning––pun intended!
What is Boosting?
Boosting is an ensemble learning technique that sequentially fits weaker learners to a dataset. Every subsequent weak learner that is fitted aims at reducing the errors resulting from the previous one.
How does boosting work?
Generally, boosting works as follows:
- Create the initial weak learner.
- Use the weak learner to make predictions on the entire dataset.
- Compute the prediction errors.
- Incorrect predictions are assigned more weight.
- Build another weak learner aimed at fixing the errors of the previous learner.
- Make predictions on the whole dataset using the new learner.
- Repeat this process until the optimal results are obtained.
- The final model is obtained by weighting the mean of all weak learners.
Boosting Algorithms
Let’s look at some algorithms that are based on the boosting framework that we have just discussed.
AdaBoost
AdaBoost works by fitting one weak learner after the other. In subsequent fits, it gives more weight to incorrect predictions and less weight to correct predictions. In this way, the models learn to make predictions for the difficult classes. The final predictions are obtained by weighing the majority class or sum. The learning rate controls the contribution of each weak learner to the final prediction. AdaBoost can be used for both classification and regression problems.
Scikit-learn provides an AdaBoost implementation that you can start using immediately. By default, the algorithm uses decision trees as the base estimator. In this case, a `DecisionTreeClassifier` will be fitted on the entire dataset first. In subsequent iterations, the fit will be done with incorrectly predicted instances given more weight.
from sklearn.ensemble import DecisionTreeClassifier, AdaBoostClassifier model = AdaBoostClassifier( DecisionTreeClassifier(), n_estimators=100, learning_rate=1.0) model.fit(X_train, y_train) predictions = rad.predict(X_test)
To improve the performance of the model, the number of estimators, the parameters of the base estimator, and the learning rate should be tuned. For example, you can tune the maximum depth of the decision tree classifier.
Once training is complete, the impurity-based feature importances are obtained via the `feature_importances_` attribute.
Gradient tree boosting
Gradient tree boosting is an additive ensemble learning approach that uses decision trees as weak learners. Additive means that the trees are added one after the other. Previous trees remain unchanged. When adding subsequent trees, gradient descent is used to minimize the loss.
The quickest way to build a gradient boosting model is to use Scikit-learn.
from sklearn.ensemble import GradientBoostingClassifier model = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0) model.fit(X_train, y_train) model.score(X_test,y_test)
The algorithm can be used for regression and classification problems.
eXtreme Gradient Boosting - XGBoost
XGBoost is a popular gradient boosting algorithm. It uses weak regression trees as weak learners. The algorithm also does cross-validation and computes the feature importance. Furthermore, it accepts sparse input data.
XGBoost offers the DMatrix data structure that improves its performance and efficiency. XGBoost can be used in R, Java, C++, and Julia.
xg_reg = xgb.XGBRegressor(objective ='reg:linear', colsample_bytree = 0.3, learning_rate = 0.1, max_depth = 5, alpha = 10, n_estimators = 10) xg_reg.fit(X_train,y_train) preds = xg_reg.predict(X_test)<
XGBoost offers the feature importance via the `plot_importance()` function.
import matplotlib.pyplot as plt xgb.plot_importance(xg_reg) plt.rcParams['figure.figsize'] = [5, 5] plt.show()
LightGBM
LightGBM is a tree-based gradient boosting algorithm that uses leaf-wise tree growth and not depth-wise growth.
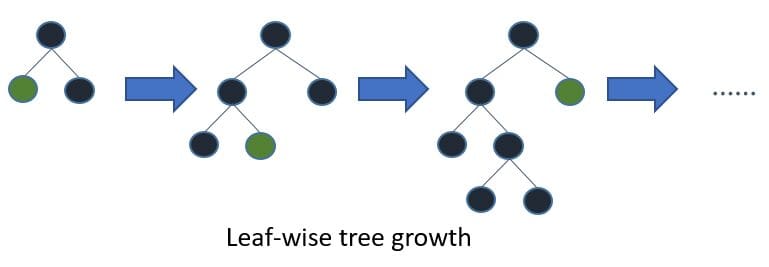
Leaf-wise tree growth.
The algorithm can be used for classification and regression problems. LightGBM supports categorical features via the `categorical_feature` argument. One-hot encoding is not needed after specifying the categorical columns.
The LightGBM algorithm also has the capacity to deal with null values. This feature can be disabled by setting `use_missing=false`. It uses NA to represent null values. To use zeros set `zero_as_missing=true.`
The objective parameter is used to dictate the type of problem. For example, `binary` for binary classification, `regression` for regression and `multiclass` for multiclass problems.
When using LightGM, you’ll usually first convert the data into the LightGBM Daset format.
import lightgbm as lgb lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
LightGBM also allows you to specify the boosting type. Available options include random forests and traditional gradient boosting decision trees.
params = {'boosting_type': 'gbdt',
'objective': 'binary',
'num_leaves': 40,
'learning_rate': 0.1,
'feature_fraction': 0.9
}
gbm = lgb.train(params,
lgb_train,
num_boost_round=200,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train','valid'],
)
CatBoost
CatBoost is a depth-wise gradient boosting library developed by Yandex. In CatBoost, a balanced tree is grown using oblivious trees. In these types of trees the same feature is used when making right and left splits at each level of the tree.
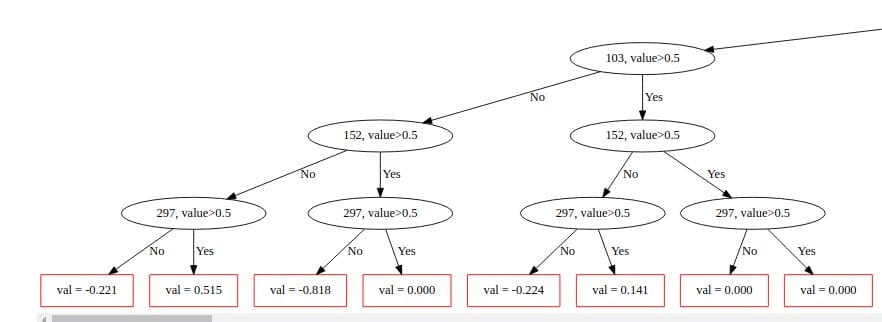
Using the same feature to make left and right splits.
Like LightGBM, CatBoost supports categorical features, training on GPUs, and handling of null values. CatBoost can be used for regression and classification problems.
Setting `plot=true` while training visualizes the training process.
from catboost import CatBoostRegressor cat = CatBoostRegressor() cat.fit(X_train,y_train,verbose=False, plot=True)
Final Thoughts
In this article we have coved boosting algorithms and how you can apply them in machine learning. Specifically, we have talked about:
- What is boosting?
- How boosting works.
- Different boosting algorithms.
- How different boosting algorithms work.
Happy boosting!
Resources
Derrick Mwiti is experienced in data science, machine learning, and deep learning with a keen eye for building machine learning communities.