Data Orchestration Trends: The Shift From Data Pipelines to Data Products
Simon Späti
JUNE 14, 2022
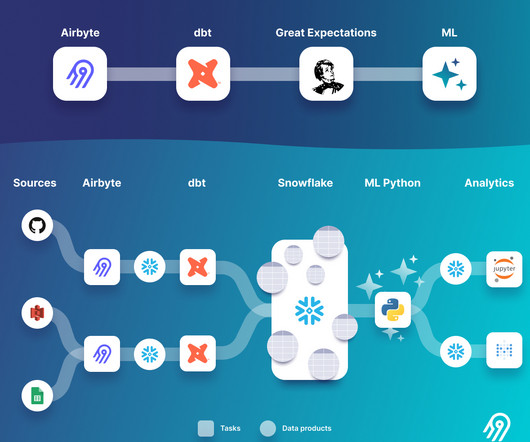
Data consumers, such as data analysts, and business users, care mostly about the production of data assets. On the other hand, data engineers have historically focused on modeling the dependencies between tasks (instead of data assets) with an orchestrator tool. How can we reconcile both worlds? This article reviews open-source data orchestration tools (Airflow, Prefect, Dagster) and discusses how data orchestration tools introduce data assets as first-class objects.






















Let's personalize your content