Ballista (Rust) vs Apache Spark. A Tale of Woe.
![]()
Sometimes it seems like the Data Engineering landscape is starting to shoot off into infinity. With the rise of Rust, new tools like DuckDB, Polars, and whatever else, things do seem to shifting at a fundamental level. It seems like there is someone at the base of a titering rock with a crowbar, picking and prying away, determined to spill tools like Java, Scala, Python, Spark, and Airflow, the things we’ve known and loved for years, from their lofty thrones.
Maybe they all have had their time in the Data Engineering sun, maybe it’s time to shake things up. It seems to be happening. It’s always hard to have those we hold dear be poked and prodded at. I’ve been using Spark since before it was cool, so when I started to hear the word Ballista start to show up here and there, I took note.
Besides, I’ve been dabbling my grubby little fingers in Rust for some months now, and have seen The Light. Is it possible I could be living at the dawn of a new era? A new and exciting frontier of Data Engineering, finally, after all this time? Could Rust really take over? Will something like Ballista pull that old Spark from its distributed processing tower and claim its rightful place?
Ballista – Rust-based Distributed Processing.
When I start to eyeball something new, some new Data Engineering tool, most of the time I would consider myself an eternal skeptic. I’ve been around the old block one too many times. The problems have changed very little in the last decade. The tools haven’t changed much, that is until lately.
Also, many of the tools that I see are released only incrementally better than their supposed competitors. Maybe a fancy UI update, a few Python decorators, and yet they claim to be some groundbreaking new tech that will revolutionize Data Teams. Yeah … not.
So why give my precious time to Ballista?
- Distributed Processing has become standard, and practically boring these days.
- Spark has been reigning supreme for a long, long time.
- Curiosity
- Knowing how game-changing Rust is.
- My eternal desire to push against the norm.
What is Ballista
So let’s start to get into Ballista. What is it? What can we expect from it?
“Ballista is a distributed compute platform primarily implemented in Rust, and powered by Apache Arrow.”
So, a Rust distributed system that uses Apache Arrow (columnar in-memory) format. Sounds almost too good to be true. Kinda makes a person wonder why we haven’t heard more rumblings about it, but I guess Spark does have a stranglehold. What else can we know about Ballista?
- Scheduler and an executor process that are standard Rust executables
- SQL and DataFrame queries can be submitted from Python and Rust
- SQL queries can be submitted via the Arrow Flight SQL JDBC driver
- The scheduler has a web user interface for monitoring query status as well as a REST API.
I mean that all seems straightforward. Dataframes, SQL, master, and executors, are par for the course. This does bring up a thought. I guess the only thing we gain over Spark is that Ballista is Rust based, with a better memory model, no Gargabe Collection overhead, and better serialization and deserialization, so it’s just faster?
I have noticed over the years that vendors and new tech likes to push the whole “I’m faster than everyone else” argument. But it only goes so far in the real world. We expect things to be fast. It needs to be fast AND offers something its competitors don’t … maybe better developer experience, ease of deployment, better APIs and interfaces, anything. People don’t like change generally, they need to have something that nudges them over the edge.
What am I looking for in Ballista?
![]()
I’m going to be looking for a few high-level things when trying out Ballista.
- How easy is it to install and set up a cluster?
- How easy is it to submit jobs to a cluster?
- How easy is it to use Datafame API?
- How easy is it to use the SQL API?
- How does performance compare to PySpark?
- How good or bad is the documentation?
I mainly just want to see if I have any trouble doing the basics and see if I feed any weak spots. One good indication of the maturity of a product is simple use it from scratch, see what kinda problems appear, how easy or not easy things are, and see if you can use the documentation. My hopes are high.
Setting up and installing a Ballista cluster.
Well, I hate to say it, but this is where I ran into my first trouble. It was hard and almost impossible to find the documentation for setting up a standalone Ballista cluster. Hard enough to find stuff about the Kubernetes deployment. Luckily after I about gave up, I did find some.
Call me old school, whatever, I like trying to install my own clusters from scratch. Why? Because it teaches you something about the systems you are working on. For example, many years ago when I was starting to get into Spark, I would set up and configure my own mini clusters using Linode. It helped me learn how the master would talk to nodes, how much memory to configure for a worker, and so on.
I want that same sort of very raw experience with Ballista. Sure, you can jump to just running something on your laptop, but I believe you’re leaving some important learnings on the table when you do that.
I’m going to use Linode and configure a small 3-node cluster manually.
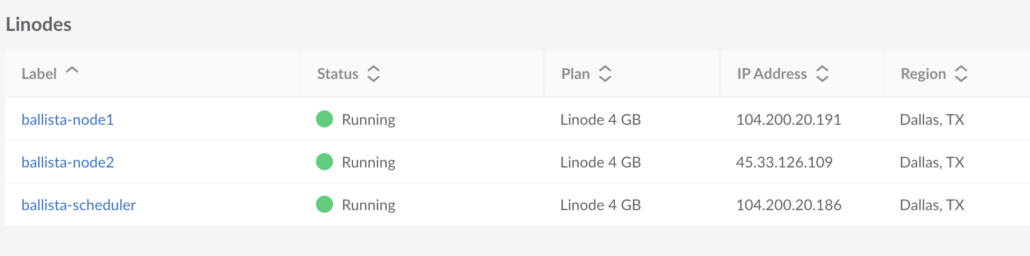
So I have three 4 GB memory nodes, one scheduler, and two nodes running Ubuntu. The first thing I will do is harden all the servers, block all traffic incoming, then whitelist the ips for the different servers. I highly recommend fail2ban and ufw on Linux machines, you use for projects.
Also, of course, I needed to install Rust on the boxes, via
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | shsnap install rustup --classic rustup install stable rustup default stable
Starting with my two nodes, ballista-node1and ballista-node2 it’s time install cargo install ballista. I will perform these operations on both executors, then the scheduler.
cargo install --locked ballista-executor
First error.
error: linker `cc` not found
= note: No such file or directory (os error 2)
error: could not compile `libc` (build script) due to previous error
warning: build failed, waiting for other jobs to finish…
error: failed to compile `ballista-executor v0.11.0`, intermediate artifacts can be found at `/tmp/cargo-installYxFe8O
C errors for years with Linux and Python, this sounds like some sort of build tooling errors. When in doubt on a Linux machine …sudo apt install build-essential
error: failed to run custom build command for `etcd-client v0.10.3`
Caused by:
process didn’t exit successfully: `/tmp/cargo-install36G8jd/release/build/etcd-client-2e3fdb39a44c22d6/build-script-build` (exit status: 101)
— stdout
cargo:rerun-if-changed=proto
cargo:rerun-if-changed=proto/auth.proto
cargo:rerun-if-changed=proto/kv.proto
cargo:rerun-if-changed=proto/rpc.proto
cargo:rerun-if-changed=proto/v3election.proto
cargo:rerun-if-changed=proto/v3lock.proto
cargo:rerun-if-changed=proto
— stderr
thread ‘main’ panicked at ‘Could not find `protoc` installation and this build crate cannot proceed without
this knowledge. If `protoc` is installed and this crate had trouble finding
it, you can set the `PROTOC` environment variable with the specific path to your
installed `protoc` binary.If you’re on debian, try `apt-get install protobuf-compiler` or download it from https://github.com/protocolbuffers/protobuf/releases
Ok, easy enough.
sudo apt install protobuf-compiler
Well, took a good 15 minutes, but finally install with no errors!
Things get tricky.
The problem from here on out is that the interwebs, including the main documentation, are strangely silent on installing and configuring a standalone cluster. There is plenty of docs for a Kubernetes install, but nothing much for standalone, as well, it’s just generally lacking documentation and good charts giving the high-level design of a Ballista cluster.
Nothing that explains, “Hey, there are the configs you really should pay attention to.” Or “This is how the scheduler talks to the executor, make sure you have x, y, z figured out.” Sorta disappointing really. It is a little disappointing, it’s hard to get folk to adopt and try new things when the barrier to entry is riddled with puzzles, it surely doesn’t help anything.
The only thing to be found is 2 `.toml` files, but they don’t mean much to someone for the first time without any context. Context is key. For example, I would assume one of the first things a person would do would be to “tell” or “configure” Ballista to know … hey scheduler … your executors reside at x, y, and z IP addresses. And … hey scheduler, these are your executors.
Switching to Ballista on Kubernetes.
Since there is plenty of documentation for Ballista on K8s, I guess I will just throw up my hands in defeat and go that route. There are some already written yaml that I can just modify and deploy myself.
 Thank the good Lord for Linode. Making life easy.
Thank the good Lord for Linode. Making life easy.
I can easily configure my kubectl.
export KUBECONFIG=~/Downloads/ballista-kubeconfig.yaml
kubectl get nodes
NAMESTATUS ROLESAGE VERSION
lke116245-172520-649a29355034 Ready<none> 15m v1.26.3
lke116245-172520-649a293554d3 Ready<none> 14m v1.26.
lke116245-172520-649a29355aec Ready<none> 15m v1.26.3
We are good with Kubernetes, time to deploy Ballista.
First we create a persistant volume for Ballista inside K8’s, i will probably use s3 data, but I have no idea of Ballista needs some persistant storage for its data processing.
kubectl apply -f pv.yaml
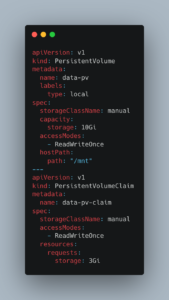
Next, our main cluster.yaml for the Ballista setup. I didn’t find any “official” DockerHub images for Ballista, but found some from the creator of DataFusion and Ballista, Andy Grove, to reference for the K8’s pull, since I didn’t feel like building a scheduler and executor images myself and hosting them myself somewhere. No thanks.
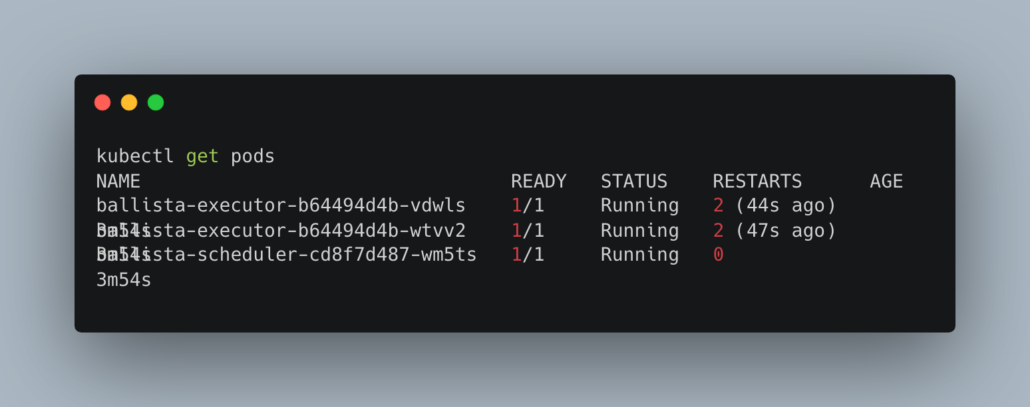
kubectl apply -f cluster.yaml
![]()
Now I could see my scheduler plus 2 executors running.
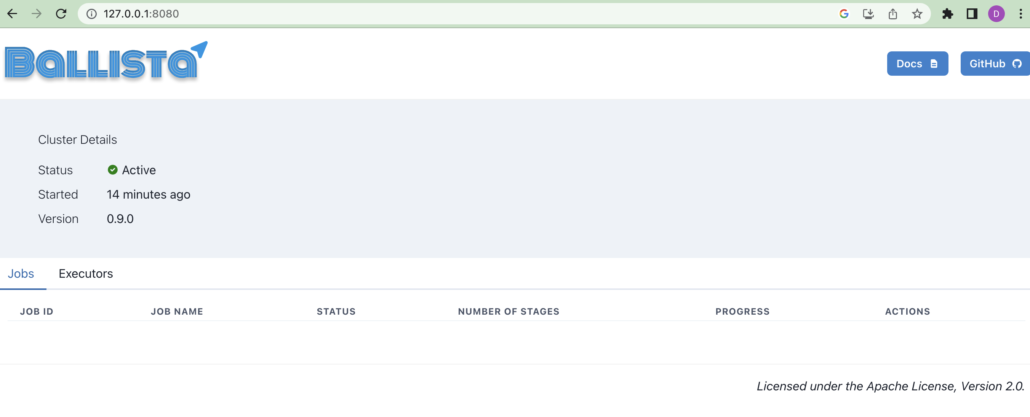
Finally, time to port-forward the scheduler UI running on port 80 over to my machine, see if all this heartache is worth it, get a UI finally.
kubectl port-forward service/ballista-scheduler 8080:80
Well, what do you know. It worked. I feel like quiting at this point, but I should probably keep going.
Processing data on a Ballista cluster.
Ok, so what I want to do know is just crunch some data with Ballista, and see what happens, see what the experience is like. But first, I’m going to just explain a few simple things.
First, our Ballista scheduler which is our entry point into Ballista, has two ports, 80 which serves our UI shown above, and 50050 with is the API allowing us to programmatically connect to the cluster.
I ran the following command to forward the K8’s scheduler port to my local machine, so we can connect via some code and try to do something.
kubectl port-forward service/ballista-scheduler 50050:50050.
Of course, like any other Data tool, Ballista has Python bindings for us to write Pythons scripts, and since Ballista is just a distributed version of DataFusion, we have access to use a SQL context, or DataFrame API. Simply a `pip3 install ballista` command away.
I tried the Python bindings first to get a connection to Ballista and get an error right away.
AttributeError: module ‘ballista’ has no attribute ‘BallistaContext’
>>> import ballista
>>> ctx = ballista.BallistaContext(“localhost”, 50050)
Traceback (most recent call last):
File “<stdin>”, line 1, in <module>
AttributeError: module ‘ballista’ has no attribute ‘BallistaContext’
Anyways, I would rather use Rust. That should be native since Ballista is a Rust product, and we will in theory run into fewer problems like this.
I almost forgot something, we need to copy a bunch of data to our k8’s persistent volume that is in use by our Ballista cluster. We can simply use kubectl cp command to do this. I’m going to use the Divvy Bike trip free dataset for our example data.
I basically ran this command and copied a bunch of CSV files out into the scheduler PODs mnt location which is our persistent storage volume. So it should be available to all our PODs on k8s.
kubectl cp 202301-divvy-tripdata.csv ballista-scheduler-cd8f7d487-wm5ts:mnt/data
I copied out 5 CSV files. Let’s try to write a Rust Ballista program that will simply count the number of records in all these CSV files.
But, I get the same errors.
Research First.
This is where I start to feel silly. For the life of me, I can’t get the Rust program to compile and build, it’s clear there are some internal issues with the Ballista cargo crate. Then I do some more research I should have done in the beginning. It appears the Ballista as we know it was handed over to the Apache Foundation.
https://github.com/ballista-compute/ballista <- you can read that here.
It also points over to a new repo, arrow-datafusion. <- https://github.com/apache/arrow-datafusion
But, guess what? That isn’t Ballista, the distributed version of DataFusion, it’s just … DataFusion. This is where it gets confusing, it appears, as far as I can gather and read, Ballista has been abandoned. I read some stuff about Arrow Flight SQL < – https://arrow.apache.org/docs/format/FlightSql.html and https://arrow.apache.org/ballista/user-guide/flightsql.html . Again, all I can gather is that development on Ballista is dead.
This is unfortunate. If someone is working on making Distributed Rust via DataFusion distributed, it isn’t clear who is in charge and if anyone is working on it. What a shame!
I got my hopes up for no reason. It’s clear that what work was put into Ballista was top-notch, it clearly had the makings of something that could give Spark a run for its money, but alas, our dreams are dashed to pieces on the shores of bureaucracy and reality.
Ballista has moved around a few times and is currently at https://github.com/apache/arrow-ballista
It’s a pity that you think the development on Ballista is dead. Actually, my team and I have been actively working on the Ballista. Compared to the Spark, Ballista is still very young.
– Compared to the Spark, it does not integrate with any resource manager, like Hadoop Yarn or K8s controller. Internally we set up the cluster on K8s. And we may contribute back this part to the community in the next following months.
– Currently we regard it as just a distributed task execution framework. It’s not responsible for the SQL optimization and single task execution efficiency. The Datafusion is in charge of those.
– Currently the data exchange is relatively simple, which may create too many small files when doing shuffle write. For this part, we have a plan to improve it by introduce push-based shuffling when don’t need to flush shuffle data on disk and sort-based shuffling like Spark to reduce the shuffle files written to disk for current pull-based shuffling.