Operation-Based SLOs
Zalando developed a new type of SLOs to monitor the critical aspects of its business which is based on Operations. This blog post describes how that framework works, and how it contributes to healthier on-call rotations.

Principal Software Engineer

Anyone who has been following the topic of Site Reliability Engineering (SRE) has likely heard of Service Level Objectives (SLOs), and Service Level Indicators (SLIs). SLIs and SLOs are at the core of the SRE practices. They are fundamental to establish the balance between building new features on a product, shipping fast, or working on the reliability of that product. But they are not easy to get right. Zalando has gone through different iterations of defining SLOs, and we’re now in the process of maturing our latest iteration of SLO tooling. With this iteration, we are addressing fragmentation problems that are inherent to service based SLOs in highly distributed applications. Instead of defining reliability goals for each microservice, we are working with SLOs on Critical Busines Operations that are directly related to the user experience (e.g. "View Catalog", "Add Item to Cart"), rather than a specific application (Catalog Service, Cart Service). In this blog post we’re going to present our Operation Based SLOs, how we define them, the tooling around them, how they are part of our development process, and also how they contributed to a healthier on-call.
The first iterations of defining SLOs
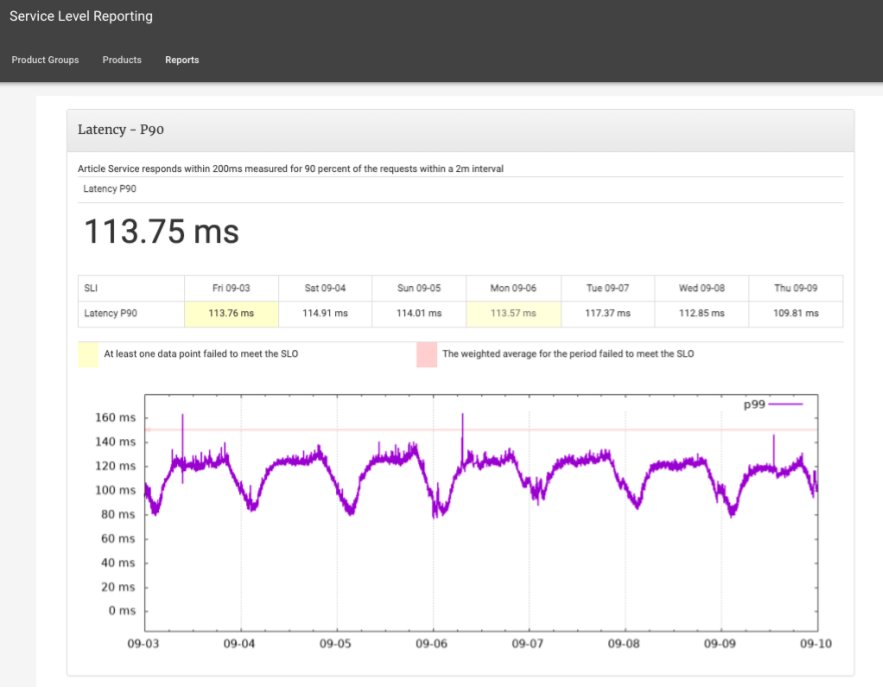
To understand where we are right now, it’s important to understand how we got here. When we introduced SRE in Zalando back in 2016 we also introduced SLOs. At the time, we went with service based SLOs. Each microservice would have SLOs on whatever SLIs service owners defined (usually availability and latency), and they would get a weekly report of those SLOs, through a custom tool that was tightly coupled with our homebrew monitoring system.
As these were new concepts in the company, we ran multiple workshops across the company for Engineers and Product Managers to train them on the basics and to kick-start the definition of SLOs across all engineering teams. Product Managers and Product Owners started to get unexpected questions from other peers and engineers:
- "What is the desired level of service you wish to provide to your customers?"
- "How fast should your product be?"
- "When is the customer experience degraded to an unacceptable level?"
The last one was particularly relevant for services that have different levels of graceful degradation. Say the service cannot respond in the ideal way; it uses its first fallback strategy that is still "good enough" so we consider it a success. But what if that first fallback also fails? We can use a second fallback just so we don’t return an error, but maybe that is no longer a response of acceptable quality. Even though the response was successful from the client’s perspective, we still count it as an error. What was particularly interesting about this thought process was that it created a break from defining availability exclusively based on HTTP status codes (where failure is anything in the 5xx range). It’s good to keep this reasoning in mind, as it will be useful further down.
SLOs saw an increasing adoption across the company, with many services having SLOs defined and collected. This, however, did not mean that they were living up to their full potential, as they were still not used to help balance feature development and improving reliability. In a microservice architecture, a product is implemented by multiple services. Some of those services contribute to multiple products. As such, Product Managers had a hard time connecting the myriad of SLOs and their own expectations for the products they are responsible for. Because SLOs are on a microservice level, the closest manager would be on the team level. Taking into consideration the previous point that a product is implemented by multiple services, aligning the individual SLOs for a single product would mean costly cross-team alignment. Raising the SLO discussion to a higher management level would also be challenging, as microservices are too fine grained for a Head or Director to be reviewing. The learning at this stage was that the boundaries of Products did not match individual microservices.

We later tried to add additional structure to the existing SLOs. One of the challenges we had with service based SLOs was the sheer amount of services that had to be measured and monitored for their SLOs. Realistically speaking, they could not all have the same level of importance. To ensure teams focused on what mattered the most, a system of Tier classifications was developed - Tier 1 being most critical and Tier 3 being least critical. With each service properly classified, teams knew what they should be keeping a close eye on. Having the Tier definition also allowed us to set canonical SLOs according to an application's tier classification. Our tooling evolved to keep up with these changes.
To summarise, our experience with service based SLOs struggled to overcome the following challenges:
- High number of microservices. The more there are, the more SLOs teams have to monitor, review, and fine tune.
- Mapping microservice SLOs to products and their expectations. When products use different services to provide the end-user functionality and with some services supporting several products, SLOs easily conflict with each other.
- SLOs on a fine grained level made it challenging for management to align on them. When dealing with SLOs on such a granular level as micro services, Management support beyond the team level is difficult to get. And within the team level, it requires costly cross-team alignment.
Symptom Based Alerting
In our role as SREs we were in frequent contact with different teams, helping them with PostMortem investigation, or reviewing their monitoring (what metrics were collected and paging alerts that were set up). While teams were quick to collect many different metrics, figuring out what to alert on was a more challenging task. The default was to alert on signals that could indicate a wider system failure ("Load average is high", "Cassandra node is down"). Knowing the right thresholds to alert on was another challenge. Too strict, and you’re being paged all the time with false positives. Too relaxed, and you’re missing out on potential customer impacting incidents. Even figuring out whether the alert always translates to customer impact was also tricky at times. All of this led us to push for a different alerting strategy: Symptom Based Alerting.
You can find more details about Symptom Based Alerting in the slides of one of the talks we did on this topic. But the main message of that talk is that there are some parallels between SLOs and Symptom Based Alerts. Namely, about what makes a good SLO, or a symptom worth alerting, and how many SLOs and alerts you should have. Both SLOs and Symptom based alerts should be focused on key customer experiences123 by defining alerts and SLOs on signals that represent those experiences. Those signals are stronger when they are measured closer to the customer, so we should measure them on the edge services. There are benefits to keeping both alerts and SLOs at a low number23. Focusing on the customer experience, rather than all the services and other components that make up that experience helps ensure that. By alerting on symptoms, rather than potential causes for issues, we can also identify issues in a more comprehensive way4, as anything that may negatively affect the customer experience will be noticed by the signal at the edge.
Let's see how this works in practice by taking the following SLO as an example: "Catalog Service has 99.9% availability". Let's assume Catalog Service is an edge service responsible for providing to our customers the catalog information, its categories, and the articles included in each category. If that service is not available, customers cannot browse the Catalog. Because it is an edge service it can fail due to issues in any of the downstream services. That, in turn, would negatively affect the availability SLO. Any breach of the SLO means that the customer experience is also affected. Due to the connection between the SLO's performance and the customer experience we come to the conclusion that the degradation of the SLI "Catalog Service availability" is a symptom of a degraded customer experience. The SLO sets a threshold after which that degradation is no longer acceptable, and immediate action is required. Or in other words, we should page when our SLO is missed, or in danger of being missed.
From this we derived the following formula:
Essentially, we wanted to capture high level signals (or symptoms) that represented customer interactions. These signals could be captured at the edge services that communicate with our customers. If those signals degraded, then the customer experience degraded. Regardless of whatever it was that caused that degradation. If we couple that with an SLO, then, following the formula above, we get our alert threshold implicitly.
There is an additional feedback loop between SLOs and symptom based alerts when you couple them like that:
- If you get too many pages, then the respective SLO should be reviewed, even if temporarily.
- If you get too few pages, then maybe you can raise the SLO, as you are overdelivering.
- If you have a customer experience that is not covered by an alert, then you likely also identified a new SLO
The problem with setting up alerts at those edge services, however, was that it would always fall down to the team owning those services to receive the paging alerts and perform the initial triage to figure out what was going on.
While the concept seemed solid, and made a lot of sense, we were still missing one key ingredient: how could we measure and page based on these symptoms, without burning out the team at the edge given they'd be paged all the time?
Introducing Operation Based SLOs
When rolling out Distributed Tracing in the company, one of the challenges we faced was where to begin with the service instrumentation work to showcase its value early on. Our first instinct was to instrument the Tier 1 services (the most critical ones). We decided against this approach because we wanted to observe requests end-to-end, and instrumenting services by their criticality would not give us the coverage across system boundaries we were aiming for. Also, it is relevant to highlight that Tracing is an observability mechanism that is operation based, so we thought that going with a service based approach would be counter-intuitive. We then decided to instrument a complete customer operation from start to finish. But the question then became: "Which operation(s)?".
Earlier, for our Cyber Week load testing efforts, SREs and other experienced engineers compiled a list of "User Functions". These were customer interactions that were critical to the customer-facing side of our business. Zalando is an e-commerce fashion store, so operations like "Place Order" or "Add to Cart" are key to the success of the customer experience, and to the success of the business. The criticality argument was also valid to guide our instrumentation efforts, so that is what we used to decide which operations to instrument. This list became a major influence on the work we did from then on.
One of the key benefits we quickly got from Distributed Tracing was that it allowed us to get a comprehensive look at any given operation. From looking at a trace we could easily understand what were the key latency contributors, or where did an error originate in the call chain. As these quick insights started becoming commonplace during incident handling, we started wondering if we could automate this triage step.
That train of thought led us to the development of an alert handler called Adaptive Paging (you can see the SRECon talk to learn more details about Adaptive Paging). When this alert handler is triggered, it reads the tracing data to determine where the error comes from across the entire distributed system, and pages the team that is closest to the problem. Essentially, by taking Adaptive Paging, and having it monitor an edge operation, we achieved a viable and sustainable implementation of Symptom Based Alerting.

But rather than going around promoting Adaptive Paging as another tool that engineers could use to be alerted, we were a bit more selective. A single Adaptive Paging alert, monitoring an edge operation can cover all the services in the call chain, which span multiple teams. No need to have every individual team monitoring their own operations, when a single alert would serve the same purpose (while being less noisy, and easier to manage). And figuring out what to alert on was rather straightforward thanks to our list of "User Functions". We renamed it to Critical Business Operations (CBO), to be able to encompass more than strictly user operations, and once again followed that list to identify the signals we wanted to monitor. Alerts need a threshold to work, though. Picking alert thresholds was always a challenging task. If we are talking about an alert handler that can page any number of teams across several departments, this becomes an even more sensitive topic that requires stronger governance.
Our list of CBOs was a customer centric list of symptoms that could "capture more problems more comprehensively and robustly". And SLOs should represent the "most critical aspects of the user experience". Basically, all we needed was a target (which would be our alert threshold) and we would also have SLOs. CBOs then became an implementation of Operation Based SLOs.
Let’s take as an example "Place Order". This operation is clearly critical to our business, which is why it was one of the first to make the Critical Business Operations list. As there are many teams and departments owning services that are contributing to this operation, the ownership for the SLO is critical. We chose the senior manager owning the customer experience of the Checkout and Sales Order systems to define and be accountable for the SLO of the "Place Order" operation. This also ensured that SLO had management support. We repeated this process for the remaining CBOs. We identified the senior managers responsible for each of the CBOs (Directors, VPs and above) and discussed the SLOs for those operations. With each discussion we would end up with: a CBO with an SLO signed off by senior management; and a new alert on that same CBO that would be sure to page only on situations where customers were truly affected.
Our Operation Based SLOs tackled the issues we had with the service based approach:
| Service Based SLOs | Operation Based SLOs |
|---|---|
| High number of SLOs. | A short list of SLOs, easier to maintain as changes in service landscape have no implications on the SLO definition. |
| Difficult mapping from services to products. | SLOs are now agnostic of the services implementing the Critical Business Operations. |
| SLOs on a fine grained level made it challenging for management to align on them. | Products have owners. We also changed the approach from bottom-up, to top-down to bring additional transparency to that ownership. |
There were additional benefits that came with this new strategy:
- Longevity of the SLOs → "View Product Details" is something that has always existed in the company’s history, but as a feature it has gone through different services and architectures implementing it.
- Using SLOs to balance feature development with reliability → Before, the lack of ownership meant that teams were not clear when to stop feature development work to improve reliability should the availability decline. Now they had a clear message from the VP or Director that the SLO was a target that had to be met.
- Out-of-the-box alerts → Our Adaptive Paging alert handler was designed to cover CBOs. As soon as a CBO has an SLO, it can have an alert with its thresholds derived from the SLO.
- Transport agnostic measurements → Availability SLOs no longer need to be about 5xx rate, or using additional elaborate metrics. OpenTracing’s error tag makes it a lot easier for engineers to signal an operation as conceptually failed. This enables the graceful degradation scenario mentioned earlier.
- Understanding impact during an incident → 50% error rate in Service Foo is not easily translatable to customer or business impact, without deep understanding of the service landscape. A 50% error rate on “Add to cart” is much clearer to communicate and derive urgency of needing to be addressed immediately.
SRE continued the rollout of CBOs by working closely with the senior management of several departments agreeing on SLOs that would be guarded by our Adaptive Paging alert handler. With this we also continued the adoption of Symptom Based Alerting. As more and more CBOs were defined, we needed to improve the reporting capabilities of our tooling, and developed a new Service Level Management tool that catered to this operation based approach.
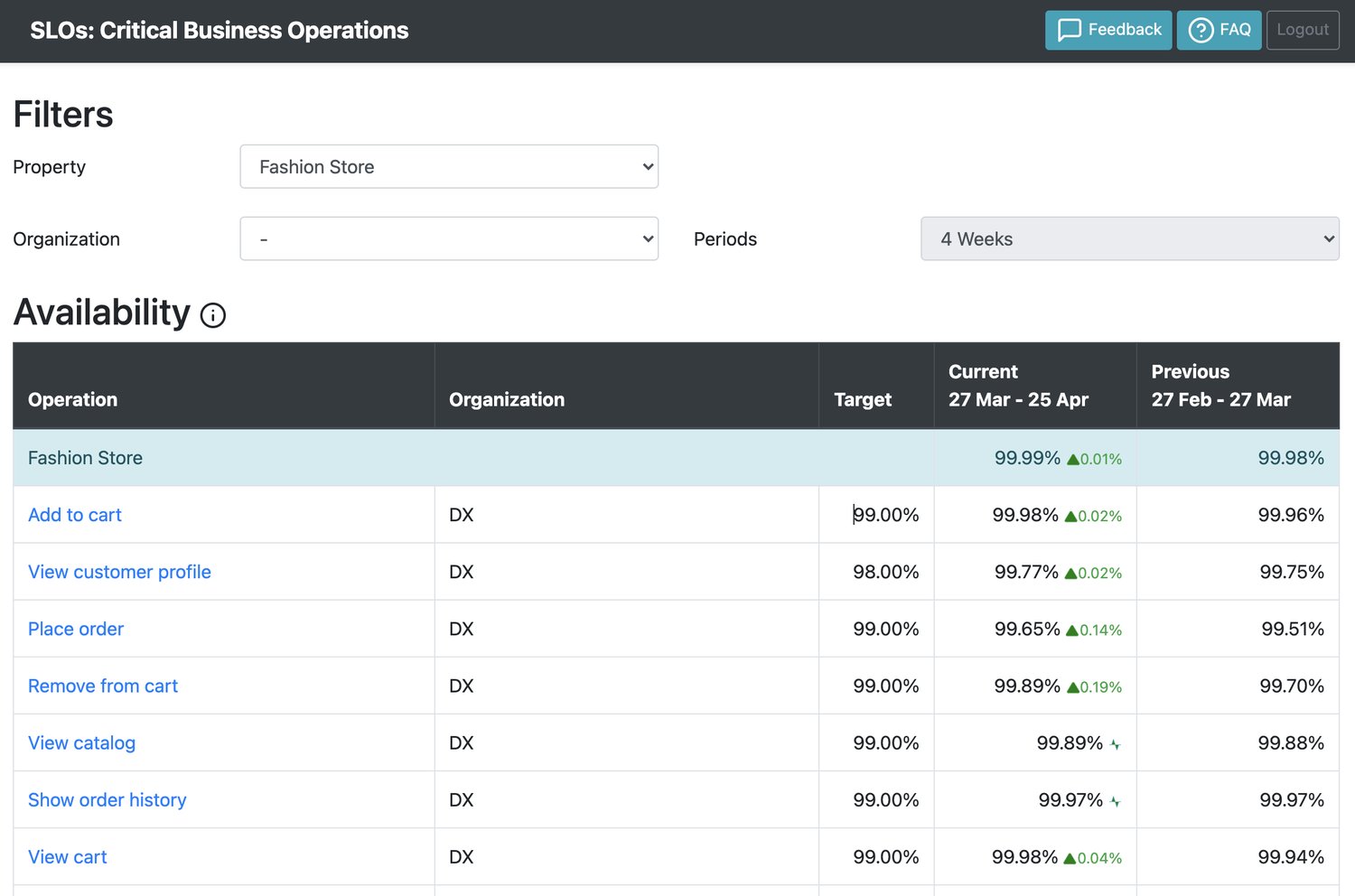
As the coverage of CBOs and their respective alerts took off, we started getting reports that the alerts were too sensitive. Particularly, there were multiple occasions of short lived error spikes that resulted in pages to on-call responders. To prevent these situations, engineers started adding complex rules to the alerts on a trial and error basis (usually using time of day, throughput, duration of the error condition). SRE was aiming at creating alerts that did not require much effort from engineers to set them up, with no fine tuning required, or that would not change as components and architecture evolved. We were not there yet, but we soon evolved our Adaptive Paging alert handler to use the Multi Window Multi Burn Rate strategy which uses burn rates to define alert thresholds. The Error Budget became much more relevant with this change. The alerts went from being triggered whenever the error rate breached the SLO, to having the decision of whether a page should go out or not based on the rate we are burning the error budget for an operation. This not only prevented on-call responders from being paged by short lived error spikes, but also meant we could pick up on slowly burning error conditions. Because the Error Budget is derived from the SLO, it is still the SLO that made it possible to derive the alert threshold automatically. Together with the adaptability of Multi Window Multi Burn Rate which made it unnecessary to fine tune alerts, this meant engineering teams required no effort to set up and manage these alerts. We also made sure that the Error Budget was visible in our new Service Level Management tool.

Putting this model to the test
Everything we described so far seems to make perfect sense. And as we explained it to several teams, no one seemed to make any argument against it. But still, we were not seeing the initiative gaining the momentum we expected. Even teams that did adopt CBOs, weren’t disabling their cause based alerts. Something was missing. We needed the data to support our claims of a better process that would reduce false positive alerts, while ensuring wide coverage of critical systems. That’s what we set out to do, by dogfooding the process within the department.
For 3 months we put the whole flow to the test within the SRE department. We defined and measured CBOs for our department, with their SLO targets (at the same time demonstrating that this approach wasn’t exclusively for the use of end-user or external customer systems). Because SRE owns the Observability Platform our CBOs included operations like "Ingest Metrics", or "Query Traces". Those CBOs were monitored by Adaptive Paging alerts. Within our weekly operational review meeting we would look at the alerts and incidents created in the previous week, and gradually identify which cause based alerts could be safely disabled or not. All of this had the support of senior management, granting engineers the confidence to take these steps.
By the end of that quarter we reduced the False Positive Rate for alerts within the department from 56% to 0%. We also reduced the alert workload from 2 to 0.14 alerts per day. And we did this without missing any relevant user-facing incidents. In the process we disabled over 30 alerts from all the teams in the department. Those alerts were either prone to False Positives, or already covered by the symptom based alerts.
One thing the on-call team did bring up was that shifts had become too calm. They risked losing their on-call ‘muscle’. We tackled this with regular "Wheel of Misfortune" sessions, to keep knowledge fresh, and review incident documentation and tooling.
What's next?
We are not done yet with our goal of rolling out Operation Based SLOs. There are still more Critical Business Operations that we can onboard, for one. And as we onboard those operations, teams can start turning off their cause based alerts that lead to false positives.
And there are additional evolutions we can add to our product.
Alerting on latency targets
Right now, CBOs only set Availability targets. We also want CBO owners to define latency targets. After all, our customers not only care that the experience works, but also that it is fast. While we already have the latency measurements, and could, technically, trigger alerts when that latency breaches the SLO, it is challenging to use our current Adaptive Paging algorithm to track the source of the latency increase. We don’t want to burden the team owning the edge component with every latency alert, so we are holding off on those alerts until a proper solution is found.
Event based systems
So far we’ve been focusing on direct end-customer experiences, which are served mostly by RPC systems. There is a good chunk of our business that relies on event based systems, and that we also want to cater for with our CBO framework. This is quite the undertaking, as monitoring of event based systems is not as well established as traditional HTTP APIs. Also, Distributed Tracing, the telemetry pillar behind our current monitoring and alerting of CBOs, was not designed with an event based architecture in mind. And the loss of the causality property reduces the usefulness of our Adaptive Paging algorithm.
Non-edge customer operations
We always tried to measure customer experience as close to the edge as possible. There are, however, some operations that are deeper in the call chain, but would still benefit from closer monitoring. To prevent an uncontrolled growth of CBOs, well defined criteria needs to be in place to properly identify and onboard these operations.
Closing notes
Operation Based SLOs granted us quite a few advantages over Service Based SLOs. Through this type of SLOs we were also able to implement Symptom Based Alerting, with clear benefits for the on-call health of our engineers. And we were even able to demonstrate the effectiveness of this new approach with numbers, after trailing within the SRE department.
But the purpose of this post is not to present a new and better type of SLOs. We see operation based SLOs and service based SLOs as different implementations of SLOs. Depending on your organization, and/or architecture, one implementation or the other may work better for you. Or maybe a combination of the two.
Here at Zalando we are still learning as the adoption of this framework grows in the organization. We'll keep sharing our experience when there are significant changes through future blog posts. Until then we hope this inspired you to give operation based SLOs a try, or that it inspires the development of a different implementation of SLOs.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Backend Engineer!