
DoorDash has grown from executing simple restaurant deliveries to working with a wide variety of businesses, ranging from grocery, retail and pet supplies. Each business faces its own set of constraints as it strives to meet its goals. Our logistics teams — which range across a number of functions, including Dashers, assignment, payment processes, and time estimations — seek to achieve these goals by tuning a variety of configurations for each use case and type of business.
Although that process started with a limited set of configurations, the old system struggled to keep up with DoorDash’s growth across new verticals. The assignment team alone hosts multiple files in GitHub to maintain the burgeoning number of preferences, some of them now weighing in at more than a megabyte each. It doesn’t help that these preferences aren’t kept in standard formats; some are JSONs, others are CSVs, and still others have no format at all. Maintaining these files and updating them at the speed of DoorDash’s growth has been both challenging and risky, with multiple outages occurring because of incorrect configurations. Additionally, the current system operates with a limited set of features, reducing the speed with which new capabilities and experiments can be launched.
With all of that in mind, we set out to build a new logistics configuration platform that could not only meet today’s demands but could continue to scale well into DoorDash’s future growth.
Current architecture

Figure 1 represents a simplified, high-level version of DoorDash’s existing architecture in which users update their preferences in GitHub files, which are then pushed to the Redis cluster. At delivery creation, KafkaConsumer reads the data from Redis, creates a delivery assignment constraint (DAC) object, and then stores it in a DAC table via delivery service. During the assignment run, DeepRed fetches this information from delivery service via Apollo and uses these configurations for an assignment decision.
Challenges and limitations
At a high level, there are some challenges and limitations in the current architecture, including:
- Updating preferences in a single line for thousands of stores: DoorDash and its business partners operate in multiple countries and regions, each with its own specific preferences. For assignment purposes, preferences are set at various granular levels — business level, SP level, store level, and so on — resulting in a huge file of preferences. In the current implementation, there are thousands of stores that share the same preferences, creating a single line with thousands of stores. Adding, removing, or changing any of these generates a massive pull request, which is arduous to review and poses a significant risk of implementation failure.
- Unintentional preferences: Given a single block of stores that has multiple preference types, there have been occasions when preferences have been updated unintentionally.
- Difficult auditing and versioning: Although GitHub provides version control, proper auditing is impeded by heavily updated config changes in the same line.
- Time-consuming process to add new preferences: DeepRed considers a lot of signals and preferences during delivery assignments. New businesses constantly introduce additional requirements, and those new preferences need to be added in multiple systems. In the current architecture, These preferences are in the DAC table, KafkaConsumer, Apollo, delivery service, upstream clients (which set the preferences), and then DeepRed, creating a process that can take up to a week.
There are also some lower-level limitations and missing capabilities in the current architecture, including:
- No way to add ephemeral configs to run experiments: At DoorDash, we believe in running plenty of experiments to get the right values for all of our stakeholders. Ideally, we would like to run experiments on ad hoc configurations, but there is no way currently to add them temporarily and in a scalable manner.
- Preferences are not real-time: When a delivery is created, corresponding DACs are also made; DeepRed must consider these additional constraints during the assignment process. Each DAC is created only once, so if certain preferences have been modified before DeepRed picks up the object, these new preferences are never considered for assignment. This is particularly troublesome for scheduled deliveries and also causes headaches during debugging. There have been multiple incidents when delivery was created before the new preferences could be set.
- No single source of truth: DACs are pre-set at the business or entity level, but dynamic preference updates also are needed at the delivery level. Instead, DACs are updated via order service during order creation, but there is no way to know whether those preferences were created by order service or if they came from predefined values.
- Incorrect usage of existing preferences: Because of the effort required to include new preferences, sometimes existing preferences with magic values are used to achieve certain outcomes.
Resolving issues with a logistics configuration platform
To address all of these challenges, we built a logistics configuration platform that provides a single source of truth with reliability, scalability, auditing, and improved velocity. We have included an intuitive UI — LxConsole — on top of the platform. Each configuration at a high level is independent, versioned, and both history- and approval-controlled.
Solving existing problems
Our new architecture sharply reduces the time needed to add a new preference type; what used to take more than a week can be done in less than a day. Additionally, auditing and version control are streamlined, with each config request resulting in a newer version entry in the database. By default, each configuration is created in an in-review state. Relevant stakeholders can then review the request and approve or reject it. This process provides a much clearer auditing path, showing who changes what, when, and why. The new architecture presents each request on a separate line, as shown in Figure 2 below, allowing the reviewer to see both the requested value and the older value. The first graphic in Figure 2 shows the impenetrable results built into our old system.
Before
These are partial screenshots of the git-diff results from a request to update two store configurations:

After
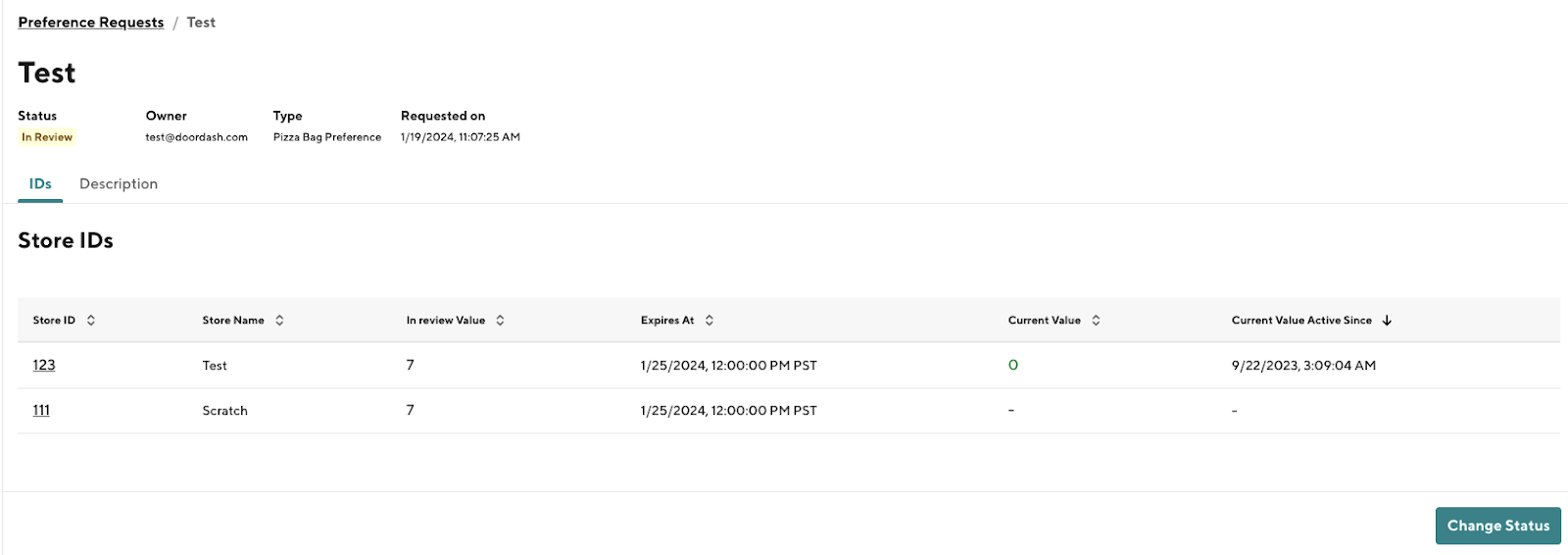
Building new capabilities
Apart from solving existing problems, the platform comes with many new capabilities:
- Expiration-based configuration: DoorDash has many use cases that need to set configurations for a certain time, and then auto revert them. This reduces time and effort to manage configuration and also avoids forgetting to revert.
- Time-based preferences: Each business and vertical wants different settings at different times of day. In this new platform, businesses can submit preference values for each time window; the platform then can return values based on those times (considering various time zones). This saves a client the effort of storing each configuration and then parsing complex time and date handling on their end. Clients, instead, can simply submit their preferences and get appropriate results. With this, businesses can fine-tune their preferences to achieve better results, as shown in this example:
Time Window based configuration:
{
{ StartTime: “0”, EndTime: “10”, value: “10”}
{ StartTIme: “11”, EndTime: “23”, value: “20”}
} - Ephemeral config types: Many DoorDash teams run experiments on preferences, but not all experiments result in final configuration. So, we need a way to add ad hoc config-types to run experiments without bloating them because config-types are primarily for long-term preferences rather than short-term experimental preferences. We included support in the new platform for adding new preferences — ephemeral configs — which would not require dev effort. It used to take around two weeks to do this, but the new configurations now allow teams to launch experiments in less than a day.
- Validation: Currently, there is no validation logic for different preferences. The new platform, however, does validations and rejects requests automatically if they do not satisfy predetermined criteria. This saves significant time for both the requester and the approver.
- Auto approval/rejection: As we onboard more use cases with a high frequency of updates and certain validations in place, we can skip manual approval for certain requests. At a very high level, the new platform will do auto-approval in two cases:
- Type-based auto approval/rejection: In these cases, all requests for a certain config type would be automatically approved. We are starting this with store-capacity, which are frequently updated configs by operators to adjust dispatch.
- Rule-based auto approval/rejection: In some cases, we can approve a request automatically when certain conditions are satisfied. For example, if validation for a given configType is successful and submitted by a certain group of people, the system can automatically approve the request.
- Extendable to any configuration type: With JSON as a type, the client theoretically can submit any arbitrary configuration and start using it in less than a day. The new platform does basic validations for JSON type and can add additional validations based on config-type. The platform is extensible so that any business can come and add their own validations on top of basic validation. With this design, clients can start using config-platform immediately and can also add additional support when needed.
- Experiment-based configuration: Engineers can set up their experiment configuration easily and write a JSON blob with required metadata such as experiment name, control, and treatment values as shown here:
{
experimentName: pizza_bag_hold_out
Control: 1,
Treatment:
{
T1: 2
T2: 3
}
}Data Model
Here is the simple data model used in the system with an explanation of each field and one example:
Schema
- Primary Key:
- domain:entityType:entityId:configType:version
- Other fields:
- value_type: Int, Double, String, Boolean, JSON etc
- config: value based on value_type
- config-status: Approved/Rejected/Expired/Deleted etc
- requester/approver/creationDate/description: other metadata
Explanation
- Domain: namespace (Pay, Assignment, Dx etc)
- entityType: store, business, SP, Delivery (more to add)
- entityId: <ID based on type>
- configType: <predefined type>
- version: Auto increment with each request
Example
| domain | entity_type | entity_id | config_type | version | config | config_status | created_at | expires_at | created_by |
| Pay | Store | 12345 | TEST_CONFIG | 1 | 7 | APPROVED | 2023-06-20 19:22:04 | saurabh |
Extendable to any entity type: As mentioned above, DoorDash works at various levels of granularity. This new platform supports adding configurations at all levels. With the schema shown in Figure 3 above, the platform can set configurations at any entity level. For example, if tomorrow there is a need to set a preference at a state level, users can simply add it with no need to make any changes except updating enums, which controls what's coming into the system. As with other parts of the design, this data model was finalized after multiple iterations. So far, this has worked for all foreseeable use cases.
Subscribe for weekly updates
Lessons learned
This section encapsulates our fundamental takeaways, providing a snapshot of the insights gained from our existing architecture and our transition to the new platform. These key lessons set the stage for the pragmatic yet forward-thinking approach we'll adopt in the upcoming steps, ensuring a robust foundation for the journey ahead.
- Think big, start small: This was a key development strategy for the platform from Day One. When we started the project, we were uncertain about the capabilities and client requirements that would be included. Instead, we focused on a basic concept: Build rock-solid small components and then iterate on top of them.
- Latency: We started with a basic CockroachDB cluster (CRDB) and three Kubernetes PODs per cell. This gave us enough performance to achieve our minimum viable product goals. We started with 300 queries per second (QPS) with p99 <10 ms; all of these were non-batched requests. As we started onboarding additional use cases and traffic, latency increased. We had to identify and fix a few problems to get latency back to where we wanted it.
- The first bottleneck we hit was when we opened traffic for batched calls from the snapshotting stage. Our latency shot from <10 ms to 500 ms for those batch calls. We moved from the default coroutine dispatcher to io-dispatcher, which increased parallelism. This improved our latency for batch calls from 550 ms to 350 ms, which was sufficient for our use case. Nonetheless, we continued to pursue improvements.
- Upon further analysis on the client side, we realized that we were supposed to create small batches; because of a small bug, however, we were making a single call with 2000 IDs rather than a batch size of 100 and we were contending with some duplicate IDs. Once we resolved these issues, our latency dropped from 350 ms to 40 ms.
- This batch call was gated behind the feature flag, which was enabled only for a subset entity types and corresponding entity ids. As we opened all traffic to config-service, our latency increased again from 40 ms to roughly 700 ms. We upgraded our CRDB cluster's instance-type which improved latency from 700 ms to 450 ms.
- We dove deeper to continue pursuing latency improvements. Though QPS to config-service didn’t increase much - 350 to 500 but peak QPS from config-service to CRDB increased from 400 req/sec to 20,000 req/sec. This was because, 1 single bulk-query request (with 1000 entities) was divided into individual request to CRDB (1000 request). After we changed our query from = clause to IN clause to use multiple entity ids, latency came back to a normal range of around 40 ms and had the same QPS to config-service and CRDB (Figure 4).

- Integration tests and local testing: Even before launching our MVP, we built integration tests and local testing setups into our system which helped in catching bugs and doing local testing at every stage. This also helped us build our iteration with confidence.
- Decoupled components and query patterns: Although we built a single endpoint for all retrieval use cases, we built use case-specific handlers. This gave us:
- Separate queries for separate use cases: Based on use cases, we optimized our queries repeatedly; updating a query for one use case didn’t interfere with other queries.
- Flexibility to move multiple endpoints: This also gives us the flexibility to break our single endpoint into multiple endpoints based on use cases without making any changes in our internal handlers. An example of this would be creating separate endpoints for UI versus service calls.
- Use out-of-the-box solutions when available: It's always best to deploy any available out-of-the-box solutions. DoorDash’s internal platform team already has built many features which come in handy, like an Asgard-based microservice, which comes with a good set of built-in features like request-metadata, logging, and dynamic-value framework integration.
Migration challenges
Our biggest challenge has been to migrate existing preferences even as the old system is actively being modified. With multiple stakeholders continuing to update the existing GitHub, it has been difficult to maintain parity with the new system. From the start, we adopted a few best practices to streamline the process, including:
- Good parity framework and migration scripts: We built a parity framework to compare results between the platform and runtime. Running in real-time, this framework can generate logs and metrics if there are any differences between the two systems. It also has helped in switching from using old preferences to new preferences with a small configuration.
- Scripts: Scripts helped us to convert to the final format -- CSV — saving us a significant amount of time.
- Clear guide with sample files and tracker: We prepared a guide and tracker to maintain clarity on which configurations already had been migrated, which were in progress, and how to prepare data for each config type.
- Communication: Maintaining clear communication at every level has been vital. We have proactively communicated with our stakeholders about what’s been launched, what remains a work in progress, how to use the new platform, and where to find any additional information they might need. We also monitor any changes being made in GitHub so that we can immediately ask stakeholders to use the new tool. This provides two advantages: No parity errors and immediate partner onboarding.
Next steps
Now that we've examined what we’ve learned from our existing architecture let’s shift focus to what lies ahead. The new architecture, called LxConfig Platform, allows us to pursue many new advantages, including:
- More clients and use cases: We recently launched our MVP and are excited to add more features to it. The LxConfig Platform has become a central focus for a variety of goals that we have set for next year and beyond. The platform is becoming a de facto standard to store the configurations. Our initial users were on the assignments team, and we are actively working on to onboard new teams, like pay, ETA, Drive.
- Simplified architecture: As previously noted, we are working towards simplifying the assignment system architecture by removing a number of unnecessary components as shown in Figure 5 below:

- Scaling: We currently are handling 500 req/s with less than 10 ms latency (p99) for non-batch calls and 40 ms for batched calls. As we bring on more clients and use cases, we need to increase this to 10,000 req/s while keeping latency as low as possible.
- Rules-based configuration: Just as with the different configurations required for varying time designations, certain conditions also require specific configurations. Currently, the client must build custom logic and do the processing. With rule-based configuration, however, clients can set configurations with discrete rules when they submit the request. At retrieval, the user can opt to pass a filter parameter, which the platform can use to return different values, as shown below:
{
Predicate: {
delivery_subtotal: >50
},
Preference: {
Risk_score: >30,
Shop_score: >20
}
}- Permission model design: Only the platform team currently has permission to approve requests, which is not a scalable solution for the long term. First, the platform team doesn’t have insights about the type of changes being requested. Second, approvals would consume far too much bandwidth from platform team engineers. While we work with the identity and security team to build a sophisticated permissions model, we are developing our own config type-based model to expand the set of people able to approve certain requests.
- Optimization: We are maintaining an ongoing search for hot spots in logic and query that could be improved over time.
- Reliability: We are careful to set realistic expectations for this new platform as we bring in clients and use cases. We are still building resiliency into our system by adding more endpoints to our SLO targets, fine-tuning our metrics, and building our infra resources, among other efforts. We continue to work toward building this platform’s ability to support T0 services and hard constraints. All current platform clients are T0 service, have fallbacks in place, and can perform in a degraded fashion if the platform becomes unavailable.
- Async request processing: The current platform can handle about 30,000 rows of CSV file processing in roughly one second in a sync call. This needs to increase when we begin to onboard daily update configurations that can include up to 100,000 rows. This can be achieved synchronously through finding and improving current limitations, keeping latency within one second, or asynchronously through decoupling request submission and processing. Moving to asynchronous will provide additional functionality and several advantages, including:
- Building a better write-path framework, breaking bigger requests into smaller parts;
- Allowing for partial success and failure and providing users details about success/failure.
- Scaling at very high input; and
- Easing the handling of system-submitted requests.
- New endpoints: Currently, requests are submitted only through LxConsole. As we move to support use cases in which configs are updated dynamically based on order type or through ML models, however, we need better methods for storing those requests. Having separate endpoints for them will keep the blast radius limited and isolated.
- New input formats: Currently, the platform is supporting byte-based input. We want to move to other formats, including file-based and record-based.
- Easy migration: With many configurations spread across multiple locations in a variety of formats, we need to improve ways to move them to config-service. Currently, we are exploring converting them to the format required by config platform if those configs are generated by a system that can be updated to use a new format. Alternatively, we can build a framework within config platform to consume CSVs and create JSONs out of them automatically. This process is ongoing while we determine which option will work best.
- Auto-consuming: While config platform is fed the data manually at the moment, we want to build a system for certain use cases to allow the platform to periodically check and pull the configuration from an auto-generated system, including possibly an ML model-generated configuration.
- Raw and derived configuration: We are also building capabilities to store raw and derived configuration data in config service for consumption and analytics. Details are being discussed, but we are excited to pursue this idea.
- Improving developer and partner velocity: While we have a good local testing framework at the moment, there are times we need sandboxes for doing end-to-end testing. We plan to enhance our platform with sandboxes that are in line with the rest of DoorDash. This will let developers spawn new environments and conduct end-to-end testing faster.
- Improved testing environment: Currently, LxPlatform doesn’t have a test endpoint. Because of this, clients connect to the prod environment for their testing. Depending on the number of clients, this could significantly increase QPS. We are considering building a parallel non-prod environment for end-to-end testing without affecting prod.
- Refine data model: As more use cases come in, we want to maintain a level of control while also allowing some flexibility regarding what kind of data to store. In the current model, configType is a single value, but we are exploring breaking it into two levels: configType and configSubType. With this change, a certain config type can have unlimited subtypes without needing to update enums for new subordinate use cases.
- Data warehouse pipeline: We are working to set up a pipeline to move data from the primary database to a data lake for long-term storage, providing easy accessibility for analytics. This will help keep the primary database small, providing better performance.
- Self-serve new config type registration: A lower-priority goal would be to provide a self-service option for partners to define their own config types. All the properties defined for these config types would be part of the registration process. This would free the platform from having to add any code changes for new config types.
Final thoughts
We started with a big vision and continue to move in that direction one step at a time, learning as we go along. Creating the platform was just the beginning. We are excited about the possibilities for continued growth as we continue to iterate and improve the system to meet the ever-changing needs of DoorDash’s growing business.
If you’re passionate about building innovative products that make positive impacts in the lives of millions of merchants, Dashers, and customers, consider joining our team.
Acknowledgements
Thank you to the working group, Ben Fleischhacker, and Ashok Thirumalai for their contributions to the discussion, design, and execution. Thanks to Paul Brinich and Gayatri Iyengar for your constant leadership support on the project. Thanks Sameer Saptarshi, Suhas Khandiga Suresh, and Ryan Xie for working both as partners & contributors. Thanks Joy Huang and Lillian Liu for reviewing product perspectives.
Finally, many thanks to Janet Rae-Dupree, Robby Kalland, and Marisa Kwan for their continuous support in reviewing and editing this article.





 QixuanWang
QixuanWang


 MarcoChirico
MarcoChirico




