Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Orchestration Tools (Quick Reference Guide)


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Imagine, if you will, a world where data just… flows. No hiccups. No “Oops, wrong format.” Just smooth, seamless operations. This is the world that data orchestration tools aim to create.
Data orchestration tools minimize manual intervention by automating the movement of data within data pipelines. Similar to a traffic director for information, data orchestration tools gather data from various locations, organize it into a usable format, and then activate it for analysis and consumption.
So, what makes a good data orchestration tool? Like much of the modern data stack, a good orchestration tool should be cloud-based and user-friendly (hand-coded Frankenstein software need not apply).
For years, the dominant force in data orchestration has been the open source, Python-based Apache Airflow. A rich user interface, broad scalability, strong community support, and critical mass adoption from major tech companies have made Apache Airflow an indispensable tool for most data teams. According to one Redditor on r/dataengineering, “Seems like 99/100 data engineering jobs mention Airflow.”
But is Airflow still the right answer for everyone? Or are there other data orchestration tools that could be a better fit for your pipeline needs?
Let’s take a look at 11 other data orchestration tools challenging Airflow’s seat at the table.
Table of Contents
Airflow
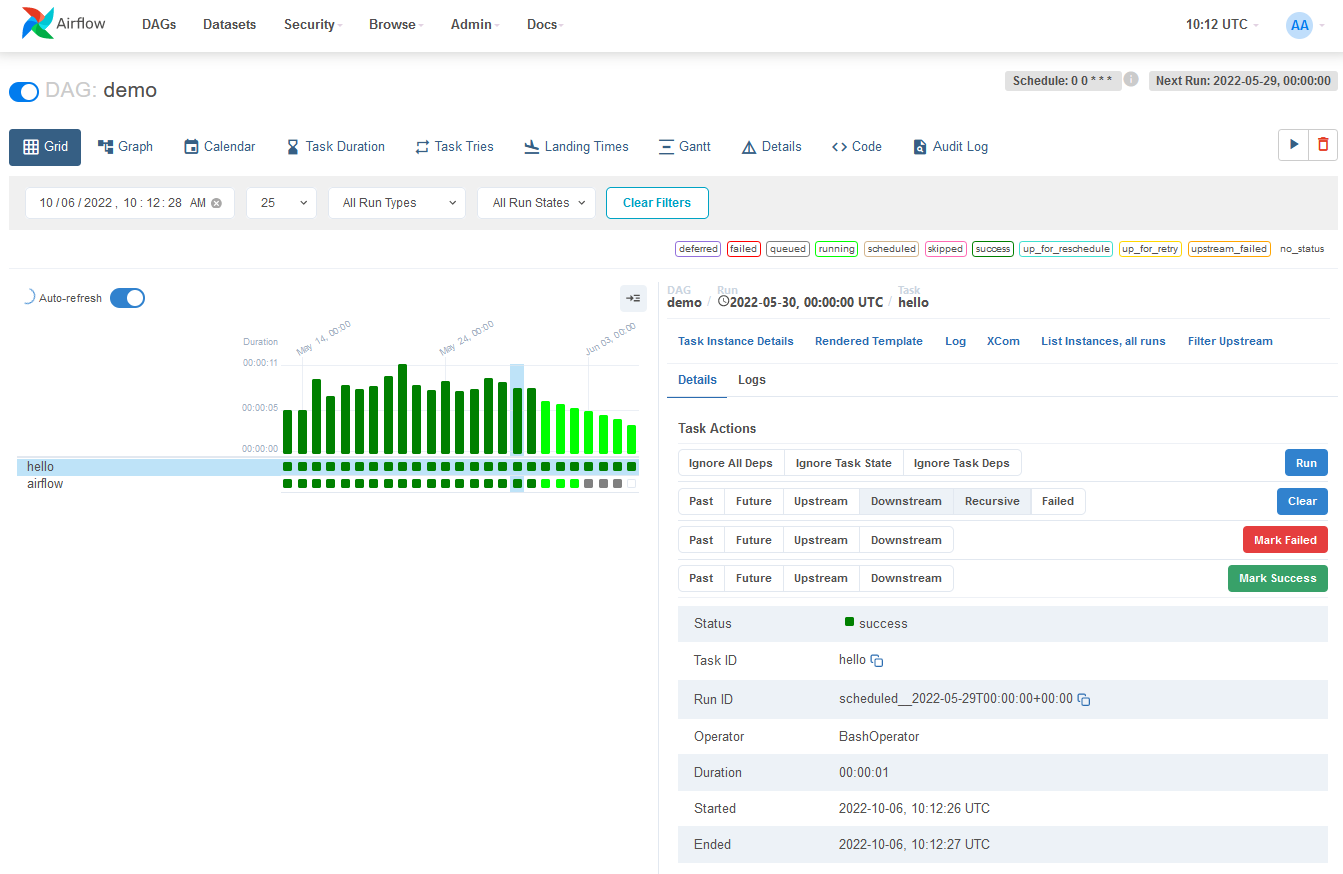
First things first—what’s Airflow?
A lot’s changed since Airflow floated onto the scene back in 2015. But even as the modern data stack continues to evolve, Airflow maintains its title as a perennial data orchestration favorite—and for good reason.
As the OG of the data orchestration tools, Airflow is renowned for its ability to programmatically create, schedule, and monitor intricate data workflows, allowing you to define combinable tasks into directed acyclic graphs (DAGs) to represent data pipelines.
In terms of features and benefits, it offers a user-friendly web interface for easier coding, a vast array of built-in operators for extensibility, and it’s actively developed with the likes of Airbnb (where it originated), Spotify, and Lyft, adopting and contributing to it.
However, like any tool, Airflow is not without its challenges. While its versatility is a strength, that same flexibility can also be a double-edged sword, leading to complexities that might not be suitable for all use cases. Some users have reported operational headaches, especially when scaling to larger workflows. Issues like race conditions, scheduling overheads, and complexities in upgrading to newer versions can sometimes mar the experience.
It’s essential to weigh these considerations against its benefits to determine if Airflow is the right fit for your needs.
Prefect
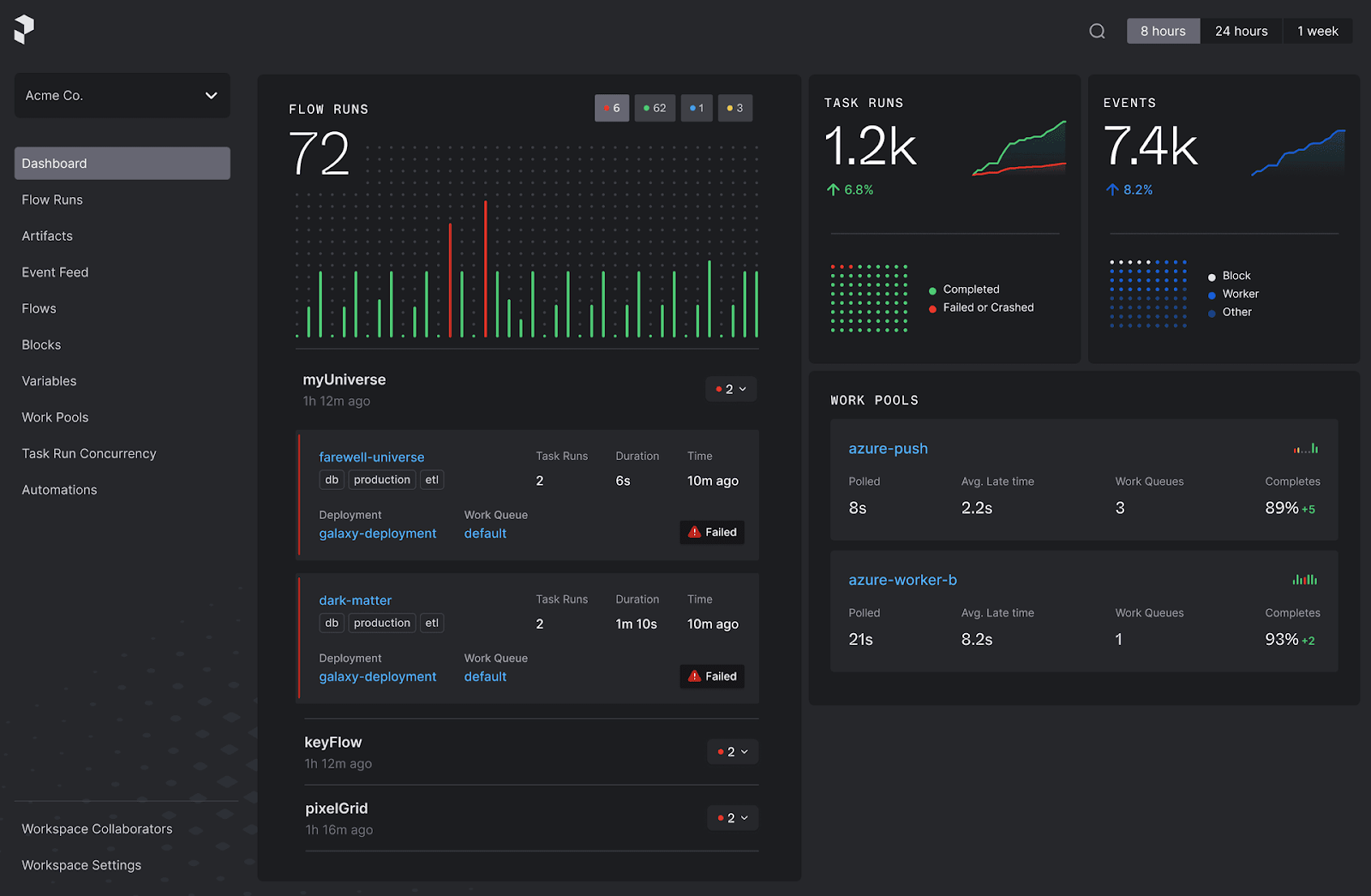
Built by an early major Airflow committer as a first-principles rewrite of Airflow, Prefect was designed to remove much of the friction common to interacting with an orchestrator.
With Prefect, you can orchestrate your code and provide full visibility into your workflows without the constraints of boilerplate code or rigid DAG structures. The platform is built on pure Python, allowing you to write code your way and deploy it seamlessly to production.
Prefect’s control panel also offers scheduling, automatic retries, and instant alerting, ensuring you always have a clear view of your data processes.
To learn more about how Prefect addresses some of the challenges of Airflow at scale, check out The Implications of Scaling Airflow.
Dagster
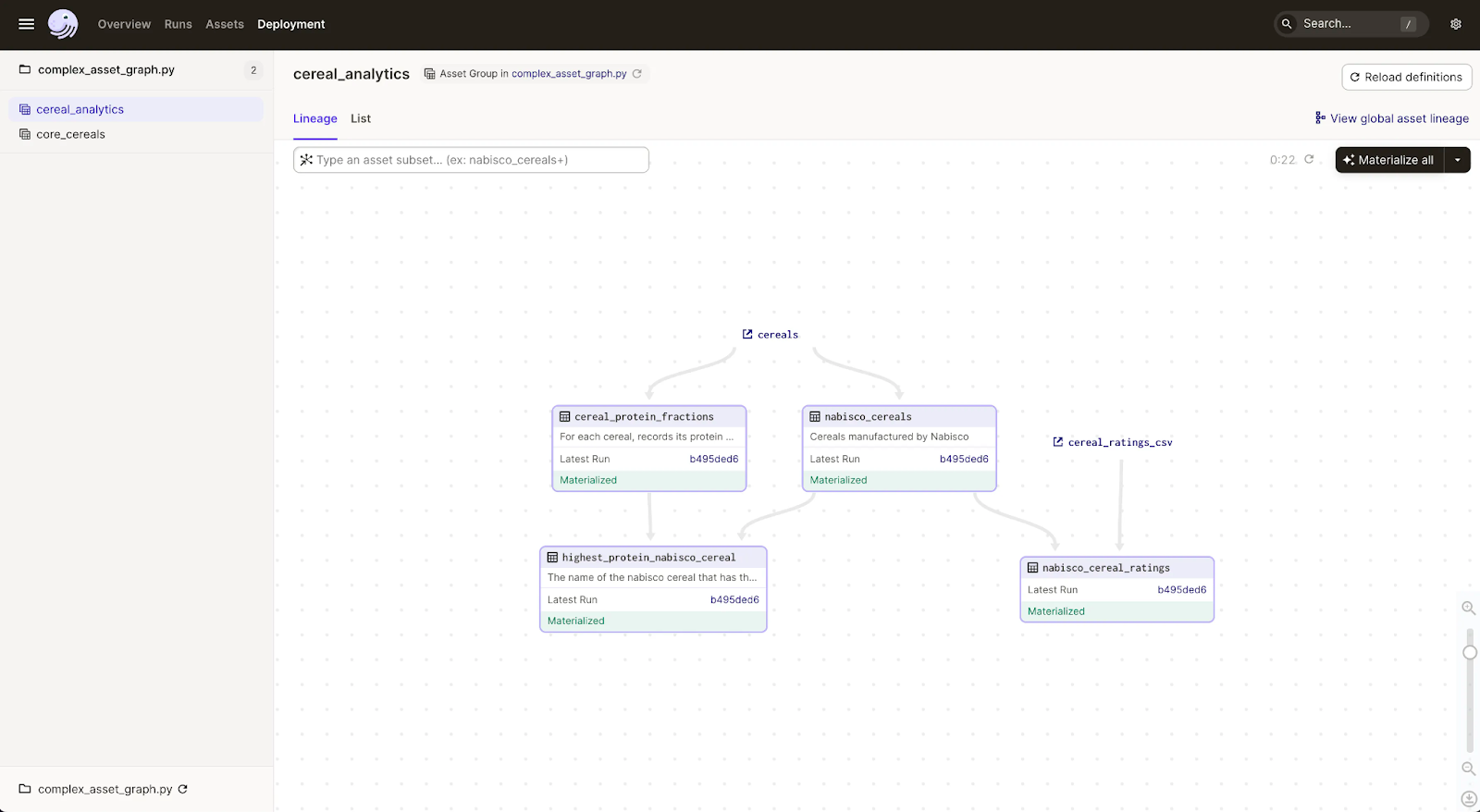
Dagster presents itself as a next-generation open-source orchestration platform tailored for the development, production, and observation of data assets.
With Dagster, you’re equipped with a frictionless end-to-end development workflow, enabling you to effortlessly build, test, deploy, run, and iterate on data pipelines.
This platform emphasizes a declarative approach, allowing you to focus on key assets and embrace CI/CD best practices from the outset. A standout feature is the Software-Defined Assets (SDAs), which introduce a new dimension to the orchestration layer, promoting reusable code and offering greater control across pipelines.
Read their Dagster vs. Airflow article for a quick head-to-head comparison.
Mage
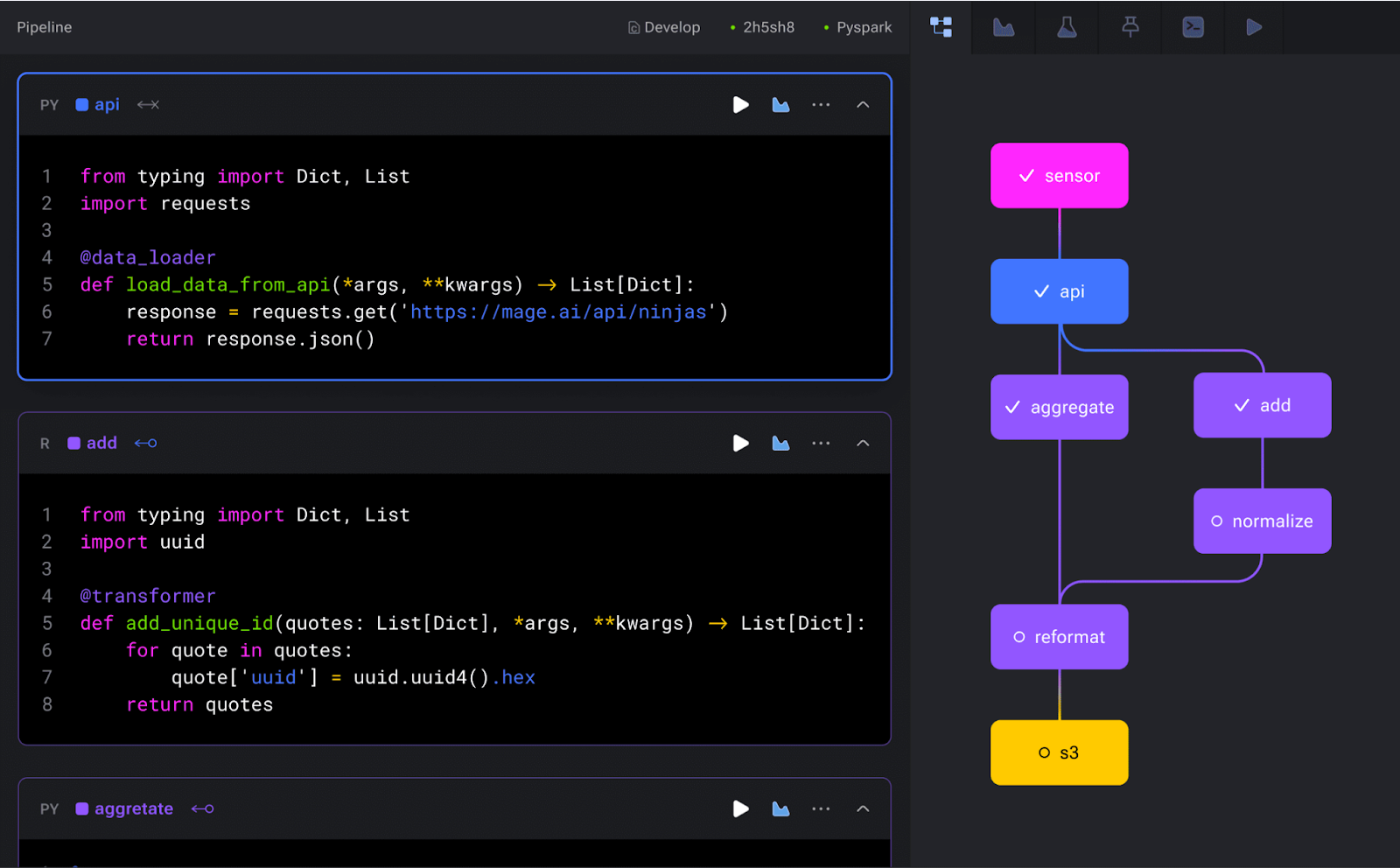
Mage boldly compares itself to Airflow with a quote from a staff data engineer at Airbnb (the original company responsible for Airflow): “You’ll love Mage. I bet Airflow gets dethroned by Mage next year!”
Whether or not that’s actually true, Mage does offer some unique approaches among data orchestration tools. With Mage, you can seamlessly integrate and synchronize data from third-party sources, constructing both real-time and batch pipelines using Python, SQL, and R. The platform emphasizes an easy developer experience, allowing you to start developing locally with just a single command or even launch a cloud-based dev environment using Terraform.
One of Mage’s standout features is its interactive notebook UI, which provides instant feedback on your code’s output, ensuring that data is treated as a first-class citizen. Each block of code in your pipeline produces data that can be versioned, partitioned, and cataloged for future reference. And when it’s time to deploy, Mage simplifies the process by supporting deployment to major cloud platforms like AWS, GCP, Azure, and DigitalOcean.
Luigi
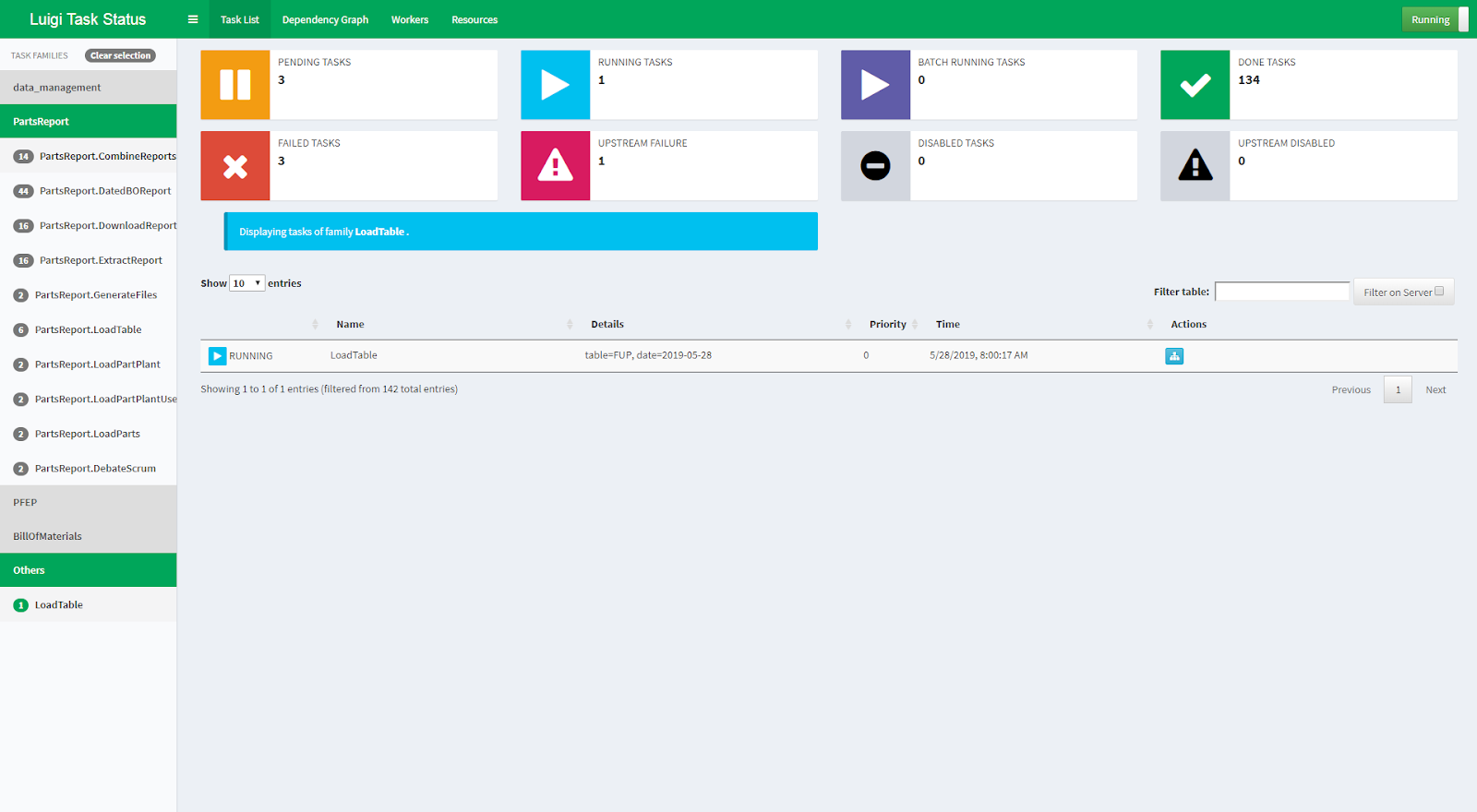
Luigi is an open source, Python-based package designed to facilitate the construction of intricate pipelines for batch jobs. Luigi’s strength lies in its ability to stitch together a variety of seemingly disparate tasks, be it a Hadoop job, a Hive query, or even a local data dump. Because tasks have dependencies on other tasks, this allows for Luigi to create intricate dependency graphs, date algebra, and even recursive task references.
Spotify utilizes Luigi to orchestrate thousands of tasks each day, forming the backbone of recommendations, A/B test analysis, and more.
Rivery
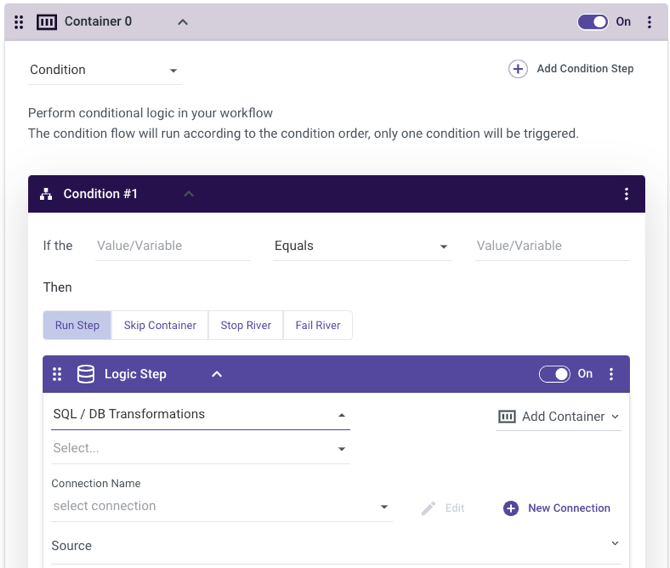
Another Airflow competitor, Rivery seamlessly connects and orchestrates all your data sources in the cloud.
A standout feature of Rivery is its no-code solution, enabling practitioners to play a more intentional role in creating their pipelines and freeing up the development team to focus on infrastructure and other core responsibilities.
Rivery offers conditional logic, containers, loops, and advanced scheduling. The platform is designed to scale and offers centralized data operations to create a single source of truth.
Keboola Orchestrator
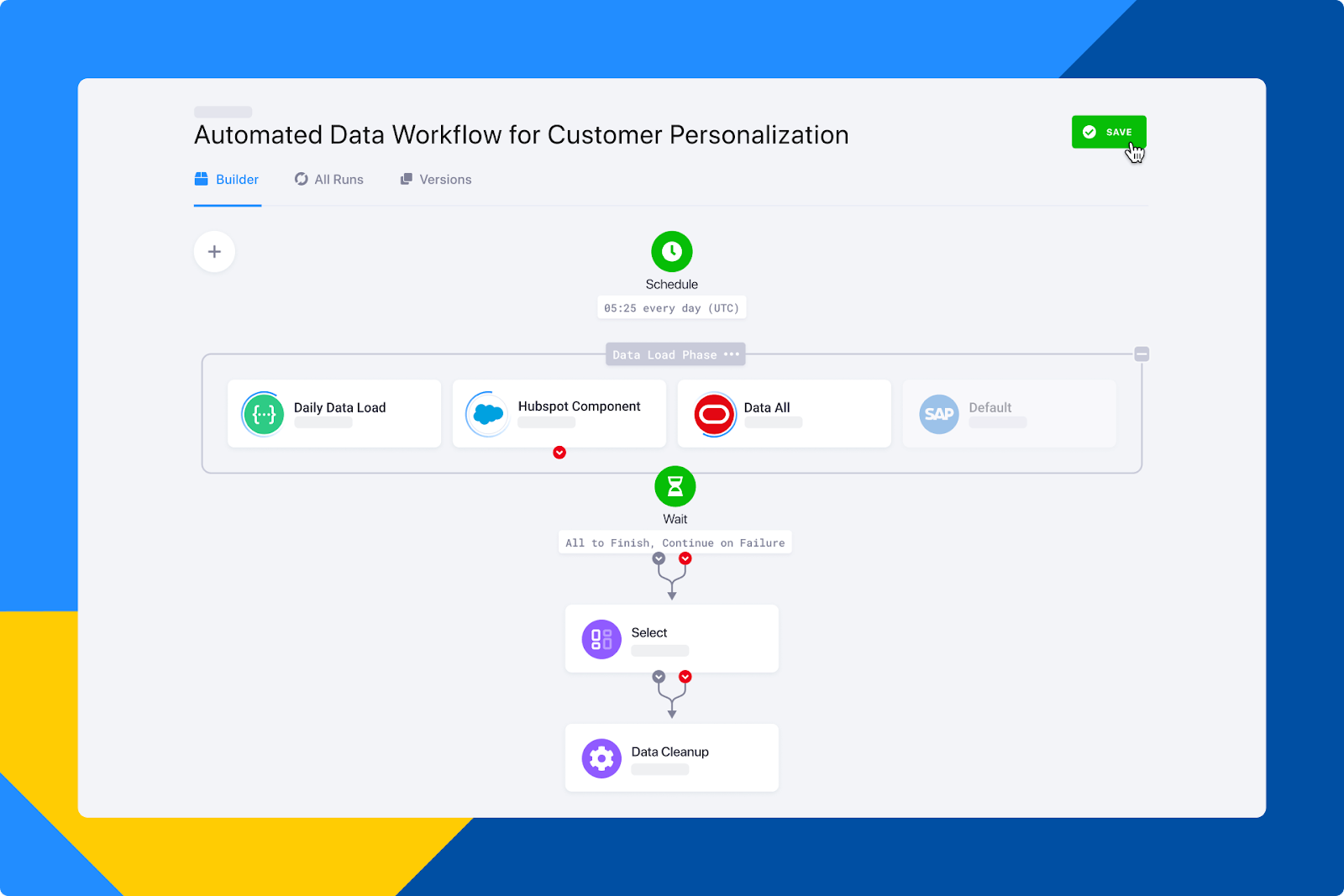
Keboola Orchestrator is an enterprise-grade data orchestration tool that can automate tasks ranging from manipulating data with transformations and writing data into BI tools to loading data using various extractors. The platform provides flexibility in determining the order of tasks, allowing for both sequential and parallel executions, and Keboola allows you to set automatic schedules for orchestrations and configure notifications.
Flyte
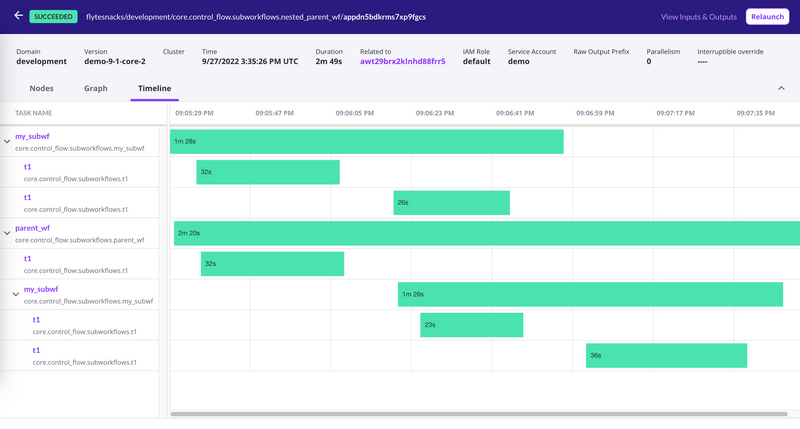
Flyte is an open-source orchestration platform that simplifies the process of building and managing data and ML workflows. One of its standout features is its built-in multitenancy, which promotes decentralized pipeline development on a centralized infrastructure for scalability, collaboration, and efficient pipeline management.
Additionally, Flyte incorporates versioning as a core feature, allowing you to experiment on a centralized infrastructure without workarounds. Read their Flyte vs. Airflow article to see how they compare.
Metaflow
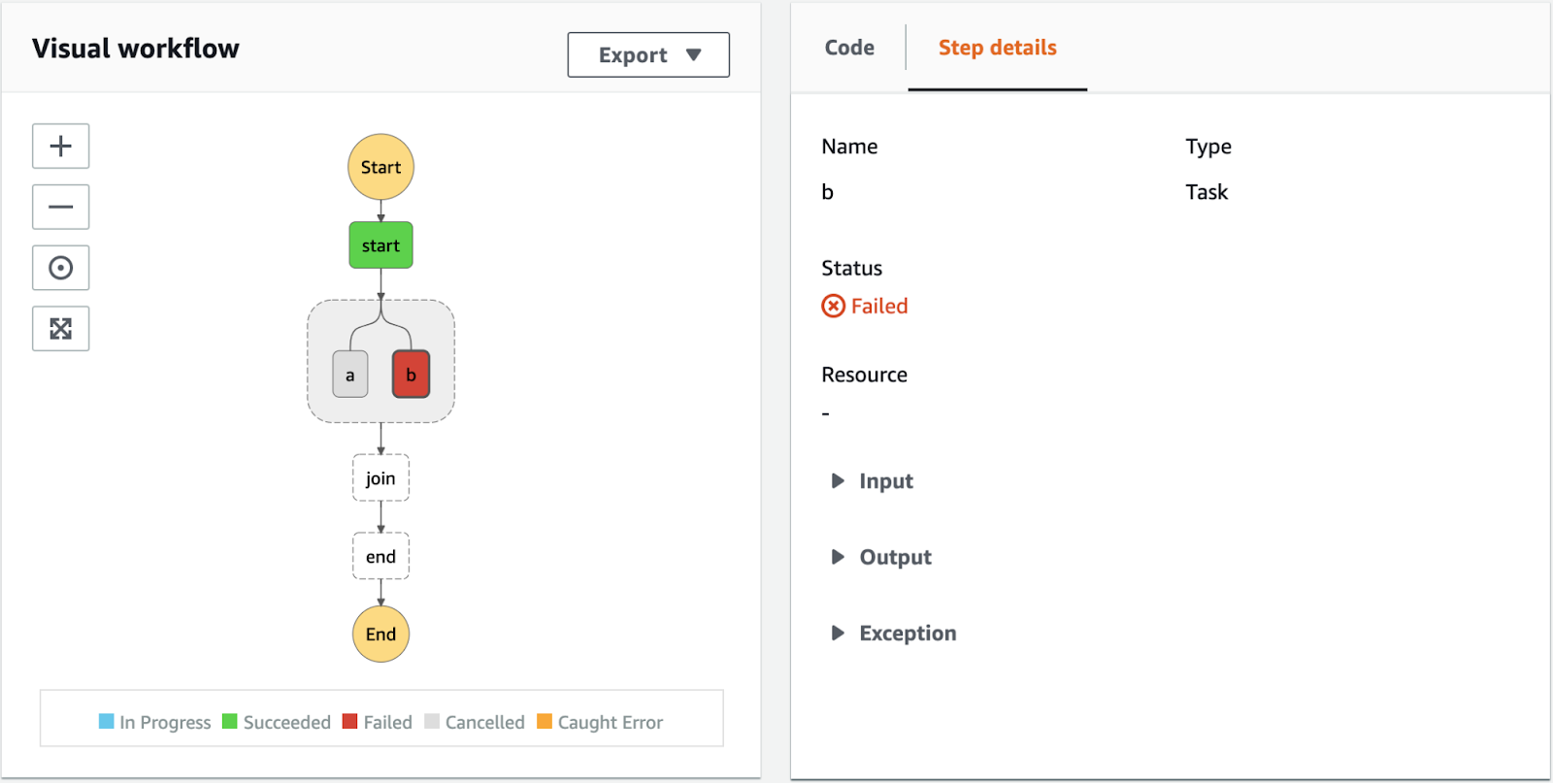
Metaflow, originally conceived at Netflix, offers a robust platform for building and deploying intricate workflows. This data orchestration tool employs a dataflow paradigm, representing programs as directed graphs termed “flows.” These flows consist of operations, or “steps,” that can be organized in a variety of ways, including linear sequences, branches, and dynamic iterations using “foreach.”
Among data orchestration tools, one standout feature is the concept of “artifacts,” or data objects created during a flow’s execution. They simplify data management, ensuring automatic persistence and availability across steps.
Metaflow integrates with all the top cloud solutions you would expect as well as Kubernetes and the systems around them.
Azure Data Factory
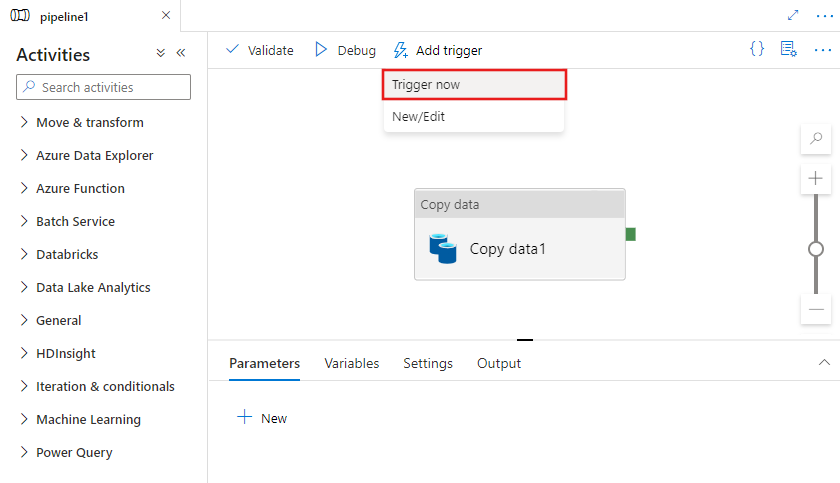
Azure Data Factory (ADF) is Microsoft’s cloud-based data integration service that orchestrates the movement and transformation of data across various data stores. While ADF provides serverless pipelines for data process orchestration and visual transformations, they also have a Managed Airflow service that allows you to leverage the Python code-centric authoring of Airflow.
Naturally, this solution will only be a good data orchestration tool for you if you’re already on Azure, so if that’s not the case, feel free to scroll on by.
Databricks Workflows
Databricks Workflows is a data orchestration tool designed to streamline data processing, machine learning, and analytics pipelines within the Databricks Lakehouse Platform. This data orchestration tool manages task orchestration, cluster management, monitoring, and error reporting. Jobs can be scheduled periodically, run continuously, or triggered by events like new file arrivals, and they can be created and monitored through the Jobs UI, Databricks CLI, or the Jobs API.
While Databricks recommends its own Jobs for orchestrating data workflows, it also supports Apache Airflow if you prefer defining workflows in Python. In that case, scheduling and workflow management are handled by Airflow, but the execution can still take place in Databricks.
Google Cloud Composer
And finally, if you’re in the Google Cloud ecosystem, you might be drawn to Cloud Composer. As Google’s fully-managed Apache Airflow orchestrator, it offers end-to-end integration with Google Cloud products, including BigQuery, Dataflow, Dataproc, Datastore, Cloud Storage, Pub/Sub, and Google’s AI platform.
According to Google, their data orchestration tool enables data engineers to author, schedule, and manage pipelines across both hybrid and multi-cloud environments as DAGs using Python.
Data orchestration tools are just one piece of the puzzle
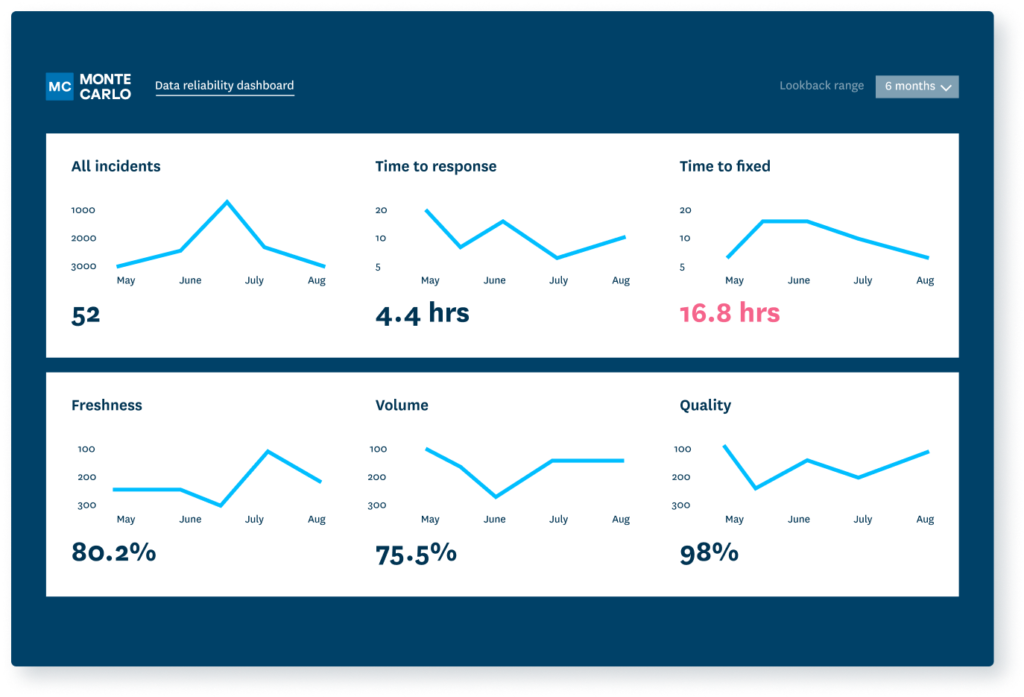
Ensuring the seamless flow and transformation of data with data orchestration tools is a great step towards building a scalable pipeline infrastructure. But what about the quality of data that’s flowing through those pipelines? This is where data observability platforms, like Monte Carlo, come into play.
You can implement all the new infrastructure and tooling into your platform that you want, but if you don’t maintain the quality of your data, you’re unlikely to end up with much more than a lesson in futility. Sure, you can push more data through more pipelines, but that just means more data quality incidents on the other side.
With the increasing complexity of data workflows and the myriads upon myriads of ingestion sources, the chances of encountering anomalies, inaccuracies, and downtime incidents get higher every day. Monte Carlo acts as your data’s guardian, ensuring that what flows into your freshly orchestrated pipelines is only the cleanest, most consistent, and most trustworthy data for your stakeholders.
In today’s data-driven world, can you really afford to take chances with your data’s reliability? Contact our reliability experts and discover how Monte Carlo can elevate your data game to new heights.
Read more posts.