
As DoorDash made the move from made-to-order restaurant delivery into the Convenience and Grocery (CnG) business, we had to find a way to manage an online inventory per merchant per store that went from tens of items to tens of thousands of items. Having multiple CnG merchants on the platform means constantly refreshing their offerings, a huge inventory management problem that would need to be operated at scale. To solve this scaling problem our team built a write-heavy inventory platform that would be able to keep up with all the changes on the platform.
Before we dive in, let’s define some important terminology. In simple terms, “inventory” refers to the list of items present in a specific store of a Convenience and Grocery (CnG) merchant. This list also comes with store-specific information, most importantly price and availability. Along with inventory, “catalog” refers to the information about an item that is typically common across all stores of a business. The combined information from inventory and catalog make up the view that customers see when they land on a store page on doordash.com.
This article outlines the challenges we faced while building the inventory platform and how we solved them after multiple iterations of experimentation and analysis.
Note: A few months back, our peers at the DashMart engineering team released an article elaborating on how they used CockroachDB changefeed to support real-time inventory changes. Organizationally, the DashMart team currently operates on a slightly different architecture than the rest of the CnG platform. While that team focused more on a specific aspect of inventory (real-time change propagation), we will focus on general pitfalls and how to circumvent them while building a write-heavy inventory ingestion platform. Additionally, the Fulfillment engineering team recently released this article about how they use the CockroachDB to scale their system. We also got similar benefits by using the CockroachDB in our system.
The challenges associated with supporting CnG inventory management
DoorDash refreshes the inventory of CnG merchants multiple times a day in three different ways:
- updates are done automatically by ingesting flat inventory files received from the merchant
- our Operations team loads the inventory data through internal tools
- the inventory is updated via signals from the Dasher app used by a Dasher shopping at a CnG store
Since the number of CnG stores is in the higher tens of thousands, and each store may contain tens of thousands of items, refreshing could involve more than a billion items in a day. To support these operations we built an inventory platform to process these items in a reliable, scalable, and fault-tolerant way. This system would ensure that we could provide an accurate and fresh view of all sellable items in stores to our customers.
The technical requirements of our ideal inventory platform
Any inventory platform has to fulfill a number of requirements: it needs to process a very high volume of items per day to provide a fresh view of the in-store inventory of a merchant. We need to satisfy the following technical requirements:
- High Scalability
- As our business grows, the inventory platform needs to support more items that are added to the system
- Frequent updates need to be supported so that inventory freshness is maintained
- High Reliability
- Our pipeline should be reliable, so that all of the valid inventory update requests from merchants should eventually be processed successfully
- Low Latency
- The item data is time-sensitive, especially the price and availability attributes. So we need to make sure we process all of the merchant's items with a reasonable latency. The gap between receiving data from the merchant and displaying data to the customer should be as small as possible.
- High Observability
- Internal operators should be able to see the detailed and historical item-level information in the inventory management system.
- The pipeline should have lots of validations and guardrails. Not all of the merchant-provided items can be shown to the customer and the system should be able to answer why an item provided by the merchant is not being displayed to the customer.
Functional architecture
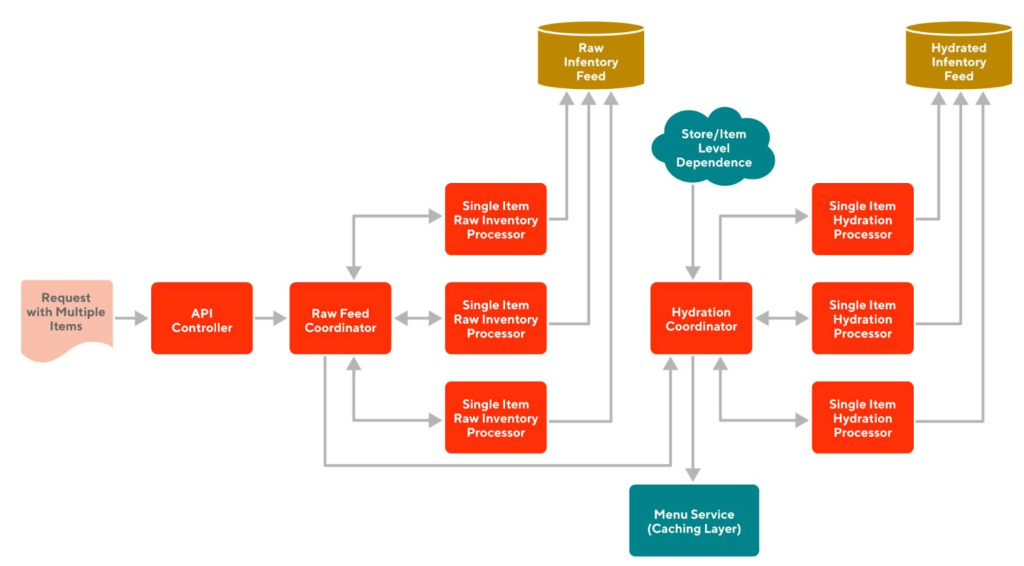
To begin the technical discussion we will start with the high-level architecture of our inventory ingestion pipeline, outlining the flow and transformation of inventory data. Then we will review the primary components in the following sections.
Figure 1 shows a high-level design of our inventory ingestion pipeline, which is an asynchronous system ingesting inventory from multiple different sources, processing them, and passing them to downstream systems where the view is served to customer-facing entities.

API controller
Our gRPC-based API controller acts as the entry point of inventory data to the platform, and is responsible for receiving and validating inventory signals from multiple sources: merchants, internal operators, Dashers, etc.
Raw feed persistence
Most of the inventory processing after the API controller is asynchronous and is executed via Cadence workflows. We store the raw input received from a merchant in order to serve subsequent read use cases for other workflows (for example, Self-Serve Inventory Manager is a merchant-facing tool providing real-time inventory information to the merchants which is obtained from the persisted raw feed). It also helps in observability and troubleshooting when unexpected data surfaces in customer views.
Hydration
As mentioned earlier, the detailed view of a store item involves both inventory and catalog attributes. The inventory ingestion pipeline at DoorDash is responsible for hydrating (i.e. enriching) raw inventory information with catalog attributes. We fetch these attributes from a service that an independent sister team maintains.
Price calculation
Similar to hydration, we also rely on external configuration fetched from a dependent service to perform per-item price calculation as and when required. For example, the price of a weighted item such as a bunch of bananas or a bag of potatoes is derived from its unit price and average weight.
Out-of-stock predictive classification
Serving an accurate availability status for a store item is a hard problem as Merchant inputs are not always the most accurate, nor very frequent. Availability signals from Dashers when they do not find items in a store bridge the gap, but not completely. We eventually implemented a predictive model which learns from historical order and INF (item-not-found) data and classifies whether an item can be available in-store or not. This classifier also acts as an important component of the ingestion pipeline.
Guardrails
No pipeline is without errors caused due to code bugs in their own systems and/or issues in upstream systems. For example, there could be an issue with an upstream module that is responsible for standardizing inventory input for a merchant before pushing them to our inventory platform; this could result in incorrect over-inflated or under-inflated prices. These errors are significant as they have a direct customer impact. For example, a bunch of bananas can show up as $300 instead of $3.00 in the customer app due to price conversion bugs in the pipeline. To protect against such price surges, the inventory platform needs to establish best-effort guardrails (and alerting mechanisms) which can detect and restrict updates when certain conditions are met.
Observability
The inventory platform executes the inventory ingestion pipeline for tens of thousands of convenience and grocery stores, each having tens of thousands of items in them. It is very important to have full visibility into this pipeline at an item level as well as a store level (aggregated statistics). We need to know if an item was dropped due to some error in the pipeline, as that directly relates to the item not being available on the store page. The observability options that the inventory platform offers help business and product personnel monitor the inventory status for each merchant, as well as calculate business OKRs:
- Item-level processing details are passed on to a Kafka layer which is read by a Flink job and populated in Snowflake (which can be queried separately)
- Store-level details are aggregated and persisted in one of our Cockroach DB prod tables directly from the pipeline
- Input and output payloads to and from the pipeline are stored in S3 for troubleshooting purposes
Reliability
Because of the extensive amount of computations and dependent services, our inventory pipeline needs to be asynchronous. Cadence is a fault-oblivious & stateful workflow orchestrator that satisfies this responsibility for us. We execute a lot of our business logic in long-running Cadence jobs. Thankfully, Cadence provides us with reliability and durability characteristics out of the box.
- Retry: Cadence has the capability to automatically retry a job if it fails abruptly. It also provides good control over the retry mechanism with the ability to set the maximum number of attempts.
- Heartbeat: We also send heartbeats from our worker to the orchestrating Cadence server to indicate the alive-ness of our job. This is a capability that comes bundled with Cadence itself.
These durability characteristics using Cadence enable the platform to be more reliable and fault-tolerant.
Incremental changes to the solution after the MVP
Our MVP was focused on doing as much as necessary to get the functional architecture up and running, i.e. we were initially more focused on functional correctness than scalability. When updating our MVP to the next iteration, we made incremental improvements as we gradually rolled out more merchants onto our system and/or identified performance bottlenecks in the evolving system. Let’s go over a few of those incremental changes.
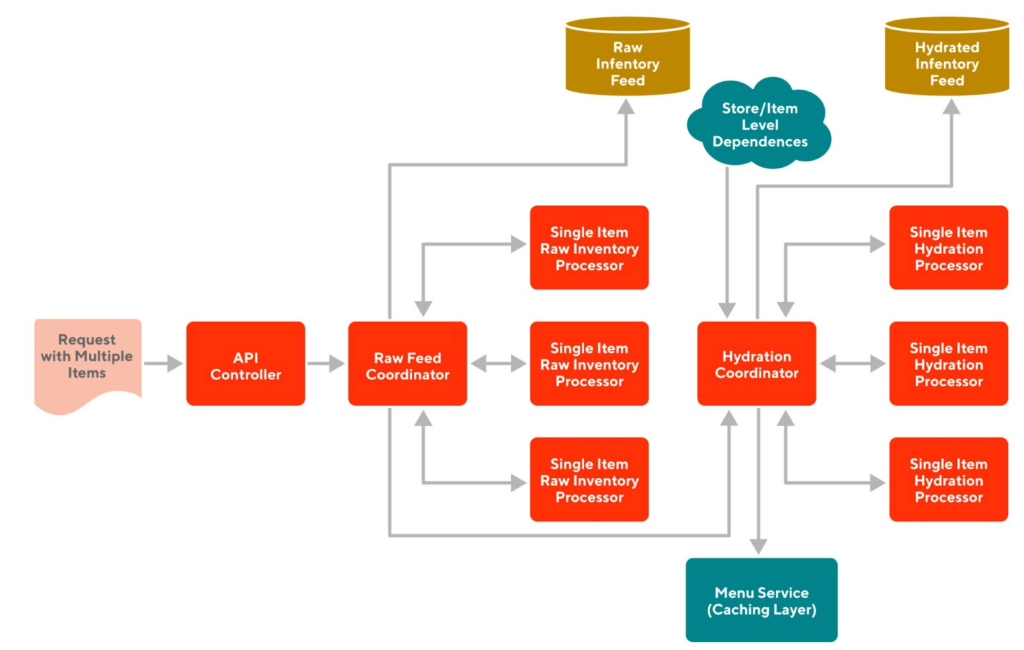
Change item-level API to batch API
Initially, our goal was to build an item-based system through and through. For the MVP version (shown in Figure 2), we built an item-level API, and to create/update one item, the caller needs to call our API once. If a store has N items, the caller will need to call the API N times, which can happen in parallel. But when we need to update the serving source (aka Menu Service) for a big merchant, which could have tens of thousands of stores with each store potentially selling tens of thousands of items, the throughput may become too high to handle. We could have scaled up by adding more resources but we thought about this differently.

Let’s think about the use case again: when we update one store, the caller already knows the complete list of items and they could simply send us the complete list of items in one API call. The most common use case would make it possible to batch the items and send them to our service within one request so our service will take much fewer API requests. Our service could save the payload in S3 and consume it asynchronously through a Cadence job.
Of course, it is important to note that we wouldn’t want to increase the batch size indefinitely because of network bandwidth limitations as well as durability concerns. So we have to find the right balance between sending enough data in a batch but also not too much.

After making it a batch API (shown in Figure 3), we observed improvements in the processing speed, but it was still far from what we desired.
Database table optimization
As we added more metrics on each step, we found the database access to be a significant bottleneck. We use CockroachDB which is a distributed SQL database and is widely used across DoorDash. After more investigation and discussion with our internal storage team, we took the following actions to optimize our database:
Choose a natural primary key instead of auto-incrementing a primary key
The tables that we were working with had been created some time ago with an artificial primary key which auto-increments. This primary key had no relation to DoorDash’s business parameters. One could argue that such a key makes sense for some use cases, but looking at our query and insert/update patterns, we realized that we can reduce the load by changing the primary key to be a combined primary key naturally constructed from business parameters. Using a natural composite key helped us reduce columns and query more efficiently because all our queries are mostly centered around those business parameters. A discussion about primary key best practices for CockroachDB can be found in this documentation.
Cleanup DB indexes
- Add missing indexes for all the queries. Over time we had added new columns, and with the fast pace of development, we had missed adding indexes that were necessary for the types of queries we were making. We carefully gathered all our queries and added the missing DB indexes.
- Remove unnecessary indexes. We had changed parts of our implementation with time and hadn’t removed the unused indexes. Also, our natural primary key was combined and constructed from a few different fields and we did not need indexes for each of them separately, as the combined index also serves the case for querying one or more of the columns in the combined index. For example, if there is already an index for columns (A, B, C), we don’t need a separate index for querying with (A, B). Note that we would need an index for (B, C), however.
Reduce the column count
Our table originally had around 40 columns and all of the columns can be updated at the same time for most cases. So we decided to put some of the frequently updated columns into one single JSONB column. There are pros and cons to keeping them separate vs putting them together. For our use case of simple text and integer attributes merged into a JSON, it works just fine.
Configure time-to-live for fast-growing tables
In order to keep the database volume and subsequent query load in check, we finalized a few high-intensity-write tables which do not need to have data for too long and added TTL (time-to-live) configurations for those in CockroachDB.
These database optimizations improved the system significantly, but we weren’t quite there yet.
DB and dependency retrieval logic modified to be store-level from item-level
To update one item, we will need to fetch a lot of information from the store level and the item level, such as the store-level inflation rate and the item-level catalog data. We could choose to fetch that information on demand as we are processing each item. Or, before we start processing, we could fetch all the necessary store-/item-level information in batch (shown in Figure 4), and pass it to each individual item to process. By doing so, we would save a lot of QPS for downstream services and databases, and improve performance for our systems as well as theirs.
Subscribe for weekly updates
Batch the DB upsert within one request to CockroachDB
Every time we finished item-level processing, we saved the result to the database by using a single item upsert - this caused very high QPS in the database. After discussing with our storage team, it was suggested that we batch the SQL requests. So we adjusted the architecture: after each item processing is complete, we collect the result and keep it in the memory of the processor. Then we aggregate the queries with 1,000 per batch and send the batch within one SQL request (shown in Figure 5).
Before the batch query
Request 1
| USPERT INTO table_name (column1, column2, column3, ...)VALUES (value11, value12, value13, ...); |
Request 2
| USPERT INTO table_name (column1, column2, column3, ...)VALUES (value21, value22, value23, ...); |
Request 3
| USPERT INTO table_name (column1, column2, column3, ...)VALUES (value31, value32, value33, ...); |
After the batch query
Request 1
| UPSERT INTO table_name (column1, column2, column3, ...) VALUES (value11, value12, value13, ...); UPSERT INTO table_name (column1, column2, column3, ...) VALUES (value21, value22, value23, ...); UPSERT INTO table_name (column1, column2, column3, ...) VALUES (value31, value32, value33, ...); |
After the above change, we observed that the DB request QPS dropped significantly, and we were getting closer to a desirable outcome.
Rewrite the batch upsert from multiple queries to one query
After a few months, we onboarded more and more merchants to this new system, and we observed the database hardware resource consumption increased significantly. We did investigate further and it was suggested that we rewrite the batch queries. We are using JDBI as our interfacing layer with the DB, and we had incorrectly assumed that providing the @SqlBatch annotation would automatically give us the best performance.
Before the query rewrite
Previously we batched the queries by using a JDBI built-in batch function, and that function batched the queries by adding them line by line but didn’t rewrite the queries into one query. This reduced the number of connections needed by the service to write to the DB, but on reaching the DB layer, the queries were still item-level.
| UPSERT INTO table_name VALUES (v11, v12, v13,...v1n);UPSERT INTO table_name VALUES (v21, v22, v23,...v2n);UPSERT INTO table_name VALUES (v31, v32, v33,...v3n);...UPSERT INTO table_name VALUES (vm1, vm2, vm3,...vmn); |
After the query rewrite
Now we are customizing the rewrite logic to merge those upsert queries into one query and CockroachDB only needs to execute one query to upsert all of those values.
| UPSERT INTO table_name VALUES (v11, v12, v13,...v1n), (v21, v22, v23,...v2n), (v31, v32, v33,...v3n), (v41, v42, v43,...v4n), (v51, v52, v53,...v5n); |
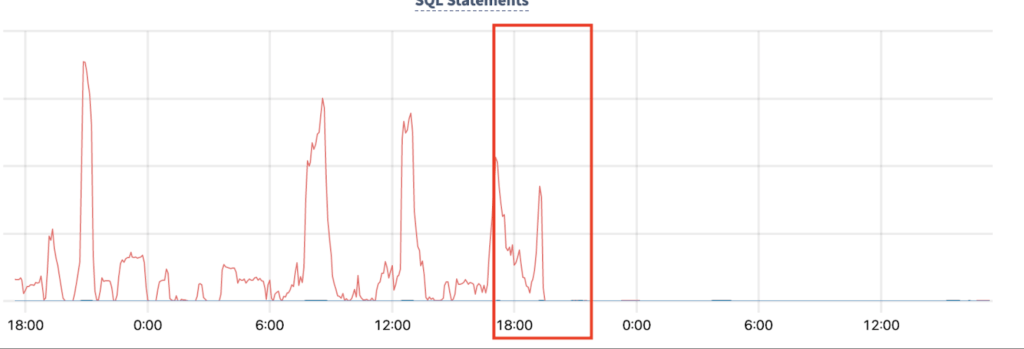
After the query rewrite change, we observed our service performance improved significantly at application layer and storage layer
- The per item processing time reduced by 75% (shown in Figure 6)
- The storage QPS dropped by 99% (shown in Figure 7)
- The storage CPU utilization dropped by 50% (shown in Figure 8)


Conclusion
Building and scaling a digital inventory is difficult as the data size of digital inventory could be gigantic, and at the same time it needs to be accurate to provide the correct in-store view of inventory. Also, it is time-sensitive because we need to show the correct price and availability of an item to the customer as soon as we get that information from the merchant. We learned a lot about how to maintain such a write-heavy, scalable, and reliable system, which could be applied to similar problems in other domains. We would like to point out a few key takeaways.
At the beginning of the implementation, put effort into creating an exhaustive metrics dashboard, so when performance issues arise, it is easy to narrow down the bottleneck of the system. In general, having high visibility into the real-time system from the start can be very useful.
Save data in a way that can help the read-and-write pattern. Inventory data may not be a flattened list of data--they may have a certain level of hierarchy. They could be saved as item-level or store-level, it is all about determining the read-and-write pattern for the service. In our serving layer, we store the menu as a tree because we frequently read at a menu level, while in the ingestion layer, we store them as item based because of the frequent item-level writing.
Batch whenever possible in API and DB. Most of the time, when we update inventory, we would update a whole store’s or geolocation’s inventory. Either way, there are multiple items to update, so it’s best to try to batch the update instead of updating single items for each request or query.
If the business unit allows asynchronous processing, make computations asynchronous and establish a strong SLA for job time per unit (i.e. store or item). Time for single-item processing includes time spent in network communication, which adds up when there are potentially billions of items to process. Instead, if we send the entire store’s inventory via one request, and on the server side use a blob storage to save the request payload, and process it asynchronously, then the client side can save the waiting time and the service can have high throughput. On this note, also establish the idea that content will be updated in near-real time instead of real-time. Cadence is a good tool for processing near-real-time jobs and has many built-in features to improve system reliability and efficiency.
Follow best practices for the applicable DB–each database will provide best practices guidance on the performance, such as CockroachDB performance best practice. Reading these carefully can help us determine the anti-patterns in the services.
Make sure to keep indexes simple and concise based on the relevant queries–no more, no less.






 QixuanWang
QixuanWang




 JobPortraits
JobPortraits
